Linkedist
리스트는 순서가 있는 데이터를 늘어놓은 형태의 자료구조를 의미합니다. 링크드 리스트란?
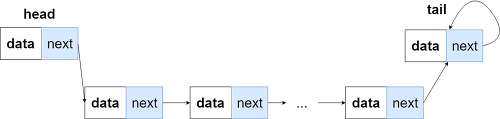
링크드 리스트는 각각의 데이터가 그 다음의 데이터를 가리키는 방식으로 순서를 말합니다.
링크드 리스트의 각 원소는 노드 (Node)라고 하며 각 노드는 데이터와 그 다음 노드를 가리키는 포인터 (Pointer) 를 가지고 있습니다.
링크드 리스트의 맨 앞과 맨 끝 노드를 각각 머리 (Head), 꼬리 (Tail) 노드라고 하고 각 노드의 앞쪽 노드를 전임 노드 (Predecessor Node), 뒤쪽 노드를 후임 노드 (Successor Node) 라고 합니다.
이런 구조의 장점은 리스트의 길이가 가변적이라는 겁니다. 배열의 단점을 링크드리스트가 커버 할 수 있습니다.
이제 코드로 구현하겠습니다.
처음이신 분들위해서 주석을 전부 달아놓아고 그로 인해 조금 어색한 부분도 있습니다. 말씀해 주시면 수정하겠습니다.
Code
#linkedist 실습 코드 짜기
#다른 교육생분들에게 설명을 위해서 주석을 꼼꼼하게 적었습니다.
#이 클래스는 단순히 data 즉, 이동의 중심인 Node가 어떻게 들어오고 이동하는지를 정의하는 파트입니다.
class Node(object): #Node로 클래스 명하는 이유는 링크드리스트의 동작 원리는 노드의 이동이기 때문입니다.
#가장 기본적인 data, next_node를 설정해주기 위한 함수
def __init__(self, data=None, next_node=None): #self는 기본 인자, 처음엔 당연히 리스트 안에 데이터가 없는 것이 맞기에 data와 next_node를 초기화 시켜야 합니다.
self.data = data # data할당하여 초기화
self.next_node = next_node # next_node 할당하여 초기화
def get_data(self): # 데이터를 얻는 함수로 받자마자 그대로 반환
return self.data #데이터 반환
def set_next(self, new_next): #데이터를 받은 후 진행되는 함수로 new_next는 리스트에 데이터가 들어온 다음을 말합니다
self.next_node = new_next # 데이터가 들어오게 되면서 previous 와 current(previous의 next)개념이 구축되기에 next_node는 새롭게 올 다음 인자를 의미#이제 링크드리스트를 실제로 구현해보겠습니다
#우리가 아는 숫자를 삽입하는 데이터가 곧 노드라는 개념과 같다고 생각하면 이해하기 편하실 것 같습니다
#head는 데이터가 없는 더미노드입니다.
class LinkedList(object):
def __init__(self, head=None): #첫 시작은 항상 이 함수로 시작을 합니다. 자 링크드리스트의 첫 부분을 우린 head라고 합니다. 허나, head는 처음부터 없기에 초기화(None)를 한 것입니다.
self.head = head #head를 할당 후 초기화
def insert(self, data): #data를 삽입하는 함수를 설정해보갰습니다.
new_node = Node(data)#위의 data가 Node class를 상속받은 것을 의미합니다.
new_node.set_next(self.head) #head의 처음으로 들어올 node를 의미합니다.
self.head = new_node # head에 할당될 것은 당연히 node일 것입니다.
def size(self): #node가 들어오게되면 당연히 기존 공간을 넘어갈 것입니다. 만약 부족하게 되었을 때 이 함수는 노드가 들어올 공간을 만들어 줍니다.
current = self.head #링크드리스트의 현재 상태를 말하는 것으로 아직은 head만 있는 상태를 뜻합니다.
count = 0 #처음엔 0으로 초기화를 시킵니다.
while current: #링크드인이 실행이되면서 current는 당연히 변화할 것입니다. 그것에 대한 반복문입니다. 더이상 늘려도 되지 않을 때 얼마나 늘렸는 return으로 반환
count +=1 #헤드를 통과하는 node가 하나씩 생길수록 공간이 하나씩 증가합니다.
current = current.get_next() # node가 하나씩 들어오고 공간이 생기면 점점 순차적으로 넘어갈 것입니다.
return count #공간을 몇 개 정도 늘렸는지 알 수 있습니다.
def search(self,data): #이제는 데이터 삽입이 끝나고 공간도 넓혔습니다. 그렇다면 데이터가 정말로 있는지 확인하는 함수입니다.
current = self.head #첫 시작은 언제나 head부터입니다.
found = False #제대로 찾기 위해서 found를 초기화하는 것입니다.
while current and found is False: #current와 found가 False(node가 없고 data를 찾지 못한다)까지 실행 즉, True가 되면 실행 종료이고 current반환입니다.
if current.get_data() == data: #current에 데이터가 있다면
found = True # 당연히 그 데이터를 찾을 것입니다,
else: #만약 있지 않다면
current = current.get_next() #그 다음 데이터로 넘어가세요
if current is None: #만약에 current에 아무것도 없다면
raise ValueError("Data not in list") #리스트에 데이터가 없다는 문구 호출
return current
def delete(self, data): #데이터를 삭제하는 내용이 있는 함수입니다.
current = self.head # 첫 시작은 head부터입니다. head부터 삭제가 됩니다.
previous = None #초기화
found = False #초가화
while current and found is False: #True가 될 때까지 실행
if current.get_data() == data: # data가 같다면(수집이 된 상태겠지요?)
found = True #당연히 찾을 수 있습니다
else: # 아니라면?
previous = current #현재가 아닌 이전 데이터를 할당합니다
current = current.get_next() #그래서, 그 다음에 데이터를 찾게 합니다
#왜 이러한 과정을 거치는 이유는 링크드인은 강의에서 보셨다시피 중간을 삭제해도 다시 연결이 됩니다. 그래서 found입장에선 삭제된 데이터를 찾는 게 중요한 게 아니라 있는 데이터를 찾는 게 중요하기에
# 그냥 다음으로 넘겨버리는 것입니다.
if current is None: #current에 아무것도 없다면
raise ValueError("Data not in list") #데이터가 없다는 말을 호출
if previous is None: #previou에 아무것도 없다면
self.head = current.get_next() # head가 넘어가서 채워
else:
previous.set_next(current.get_next()) #current 와 preivous가 있다면 previous의 다음은 current라는 정의에 적합한 상태가 되겠죠?
성장을 도울 아카이빙 블로그