이어드림
1.Basic Tech

통신 프로토콜(TCP/IP)을 통해서 정보를 제공하는 것이고 무선 인터넷같은 경우 주파수를 통해서 단말기에 전달하는 방식입니다.우리가 편하게 인터넷을 사용할 수 있는 이유는?해저 케이블을 통해서 서버가 접속이 되기 때문입니다.Client정보를 요청하는 자Server정보
2.MongoDB with Python
보통 우리는 SQL을 통해서 데이터베이스에 접근 후에 데이터 수정 및 추출을 하는 것이 익숙할 것입니다.허나, 재미있는 것은 실제 데이터를 분석하고 추출할 때 SQL을 사용하지 않고 다른 방법을 사용합니다. 그것이 바로 몽고DB입니다.이번 이어드림에서 첫 실습은 바로
3. MongoDB with Python(2)
이전 블로그의 내용을 계속해서 나아가는 것입니다.API를 활용하여 연동한 후에 데이터를 Json파일 형식화를 시도해보겠습니다.response.json() \`\`\`
4.Flask with python
Flask 실습한 내용에 관련한 코드입니다. 현재는 코드만 보고 이해가 될 수 있도록 자세하게 주석을 써보는 공부를 하는 중입니다.실습 전, 결론으로 말하면 상황에 맞는 라이브러리를 먼저 호출 후에 변수를 할당합니다.그리고 나서 데코레이션을 활용하여 route를 설정하
5.Linkedist
Linkedist 링크드리스트의 가장 큰 장점은 리스트의 길이가 가변적이라는 겁니다. 배열의 단점을 링크드리스트가 커버 할 수 있습니다. 배열은 크기가 가변적이지 않죠. 우선 크기를 정해준 다음에 모자라면 메모리를 더 할당하고, 배열의 데이터를 복사해야 되죠. 오래
6.Stack
위의 그림처럼 데이터를 한 쪽에서만 넣고 뺄 수 있는 구조로 LIFO(Last In First Out)리고 불립니다.즉, 마지막에 쌓은 데이터가 먼저 나오는 것이죠\*장점구조가 단순하기에 구현이 쉽고 데이터 저장 및 읽는 속도가 빠릅니다.\*단점스택에 데이터를 쌓을 범
7.linked_queue
Linked List는 노드들이 위와 같이 여러 구조로 연결한 것입니다.\*삽입자료를 삽입하려면 추가할 장소로 가서 기존의 링크를 끊은 후에 추가할 위치의 prev와 next를 연결하는 힙니다. 시간 복잡도는 다이렉트이기에 O(1)입니다.\*제거자료를 삭제하려면 삭제
8.Double_linked_list

단일 연결 리스트와 달리 head와 tail를 가지고 각 노드는 앞 과 뒤 노드의 정보를 가지고 있기에 양쪽으로 접근이 가능합니다. 그래서 양방향 연결 리스트라고 불리게 되었습니다.\*삽입삽입할 노드(new_node)의 prev는 이전 노드를 가리킵니다.삽입할 노드의
9.Circular_queue
배열로 구현이 되지만 배열의 단점을 극복한 것입니다. 원형 큐 또한 큐이기 때문에 선입선출방식입니다.고정된 크기의 배열로 구현되고 원이기 때문에 수열적 생각도 좋습니다.\*삽입데이터가 처음 삽입될 때 rear방향으로 삽입됩니다.데이터가 끝 위치에 다닿으면 다음에는 다시
10.Binary Search
오름차순으로 정렬되어있는 리스트 내에서 특정한 값의 인덱스를 찾는 알고리즘입니다.정렬된 리스트에서만 사용되기에 빠른 속도이고 시간복잡도는 O(logN)입니다.n/2 혹은 (n+1)/2 번째를 기준으로 좌우를 비교하면서 원하는 값을 찾는 방식입니다.\*예제(flow)
11.Buble sort
안전 정렬 vs 불안정 정렬중복된 값의 순서 보장 여부를 뜻하는 것입니다.\*\*In-place 정렬 vs Out of place 정렬원본 데이터 내 정렬 여부를 뜻하는 것입니다.인접한 두 element의 값을 비교하는 것으로 두 값이 정렬되어있지 않다면 위치를 교환정
12.Hash
KEY: 중복이 되지 않는 고유 값VALUE : Key를 기준으로 매핑됨Hash 함수: key와 value관계를 성공적으로 만들어주는 것. 즉, 키를 통해서 해시값을 매핑시키는 함수입니다.시간복잡도는 O(1)해싱함수가 좋다면 키 값을 고르게 분포시키기에 계산이 빠르고
13.Insertion Sort
리스트의 앞에서부터 이미 정렬된 서브 리스트 값들과 비교 후에 자신의 위치에 삽입을 하는 것입니다.삽입 정렬은 인덱스 0인 부분(서브 리스트)은 이미 정렬이 되었다고 판단을 하여 인덱스 1인부분 부터 정렬을 시작합니다.작은 값은 큰 값의 앞으로 보내지고 큰 값은 다른
14.Merge Sort
하나의 리스트를 두 개의 균등한 크기의 리스트로 분할을 한 후에 부분 리스트를 합치면서 정렬을 합니다.그래서, 전체가 정렬이 되게 하는 방식입니다.주로 재귀함수에서 쓰입니다.시간복잡도는 O(NlogN)\*예시
15.Quick Sort
병합 정렬처럼 숫자를 나누면서 정렬이 진행이 되기에 시간복잡도는 O(NlogN)이 됩니다.하지만 시간은 병렬 정렬보다 빠릅니다.특징공간(spaital)지역성: 특정 클러스터의 기억 장소들에 대해 참조가 집중적으로 이뤄지는 경향으로 참조된 메모리 근처의 메모리를 참조합니
16.HTML
HTML은 head와 body로 구성이 되는데, head안에는 페이지의 속성 정보를 body안에는 페이지의 내용을 담고 있습니다.head안에 들어가있는 대표적인 요소들은 meta, script, link, title등입니다.scropt는 페이지의 속성을 정의하거나 필요
17.트리
한 노드가 여러 노드를 가르킬 수 있는 것으로 비선형적 자료구조입니다. 그리고, 데이터 구조의 계층적인 속성을 표현하고 그래프 형태입니다.\*root와 edge\*부모 자식\*경로(path)\*Depth\*level\*트리 안에 서브 트리(재귀적 관점)\*현실 예시\*
18.이진트리(Binary Tree)
각 노드가 최대 2개(0~2)의 자식 노드를 가지는 트리이지만 왼쪽 자식노드와 오른쪽 자신노드와 다릅니다.\*간단한 코드정 이진 트리(full binary tree, strict tree)모든 노드가 2개의 자식을 가지거나 자식이 없는 경우를 말합니다.포화 이진 트리(
19.트리 탐색
루트 노드를 방문하고 왼쪽 서브 트리를 그리고 오른쪽 서브 트리를 합니다.왼쪽 서브 트리 후 루트 노드 방문하고 마지막으로 오른쪽 서브 트리를 합니다.왼쪽 서브 트리 후 오른쪽 서브 트리를 하고 마지막에 (루트)노드 방문합니다.
20.이진 탐색트리(BST)
트리 구조 자체로는 데이터의 특성에 아무런 제약이 없다.노드의 왼쪽 서브 트리에는 루트 노드보다 작은값이다.노드의 오르쪽 서브 트리에는 루트 노드보다 큰 값이다.중복된 값이 없다.서브 트리는 다시 이진 탐색 트리가 되어서 위의 특징을 갖는다.레벨에 생각 없이 트리의 가
21.힙(Heap)
완전 이진 트리최대 힙: 부모 노드의 값은 항상 자식 노드보다 크거나 같기에 루트 노드는 트리의 최댓값입니다.최소 힙: 부모 노드의 값은 항상 자식 노드보다 작거나 같기에 루트 노드는 트리의 최솟값입니다.최대/최소를 기준으로 데이터를 찾는 연산을 빠르게 할 수 있다 O
22.알고리즘
\*정의주어진 문제에 대해서 문제를 해결하기 위한 방식을 순차적으로 나열한 것입니다.\*특징입력(input): 입력값을 가진다출력(output): 출력값을 가진다유한성(finiteness): 유한 시간 내에 종료 되어야 한다정확성(precision): 각각 중간과정은
23.python300도전기
파이썬 300제를 공부하는 주소로 포기하지 않고 300제를 완주할 것입니다.https://github.com/qsdcfd/Year-dream/tree/TIL/Theory/Python/Questions
24.toy project
참고 링크: 링크텍스트날짜: 2022.04.21데이터셋: Boston housing.csv
25.백준 2480풀이
26.파이썬 문제풀이
링크:링크텍스트링크:링크텍스트
27.Toy_project2
링크텍스트
28.프로그래머스 체육복

Code `
29.이것이 코팅테스트다 그리디: 1이 될 때까지
30.프로그래머스 고득점SQL -Kit
31.프로그래머스 역순 정렬하기
문제 : 링크텍스트
32.프로그래머스 어린 동물 찾기
SELECT ANIMAL_ID, NAMEFROM ANIMAL_INSWHERE INTAKE_CONDITION <> 'Aged'
33.프로그래머스 k번째 수
풀이1풀이2
34.프로그래머스
동물의 아이디와 이름
35. 프로그래머스 여러 기준으로 정렬하기
36.수학 스터디
Q11) 중심극한 정리는 왜 유용한가?Intro정규분포는 중앙치에 사례 수가 모여있는 형태입니다.정의동일한 확률 분포를 가지면서 독립 확률인 n개의 확률변수의 평균 분포가 점점 커지면 정규 분포에 가까워집니다.\*이미지로 보는 중심극한 정리 모습개인적인 질문) 왜 이게
37.수학스터디(2주차)
기간:2022.04. 26 ~ 2022.05.03공분산은 X와 Y의 선형관계를 이룬다고 했을 때, X의 증감이 Y의 증감 경향을 측정하는 것으로 쉽게 말하면, 확률변수의 흩어진 정도를 말할 수 있습니다. 즉, 두 변수간의 양의 상관관계가 있는지 음의 상관관계가 있는지
38.이코테 chapter06_03
문제N명의 학생 정보가 있다. 학생 정보는 학생의 이름과 학생의 성적으로 구분된다. 각 학생의 이름과 성적 정보가주어졌을 때 성적이 낮은 순서대로 학생의 이름을 출력하는 프로그램을 작성하시오.입력 조건1\. 첫 번째 줄에 학생의 수 N이 입력된다. (1<= N &
39.이어드림 스쿨 데이터
현재, 이어드림 스쿨에서 진행 중인 대회에서 결측치 관련으로 정리한 코드입니다.결측치 : 링크텍스트그리고, 시각화한 것입니다. 링크텍스트
40.L1, L2, 코사인 유사도
이어드림스쿨에서 회귀분석 관련한 강의를 수강한 후에 값으로만 되어있는 것이 아쉬워서 직접 시각화 코드를 구현한 후 세 가지를 비교했습니다.링크텍스트
41.이산확률변수
확률변수를 이해하려면 필요한 것은?통계분석을 위한 기초 수학Python 라이브러리를 활용한 데이터 분석이산형과 연속형이산형은 셀 수 있는 데이터고 연속형은 값들 사이에서 무수히 많은 값들이 존재할 수 있기에 셀 수 없는 데이터이다.확률변수변수가 취할 수 있는 값과 그
42.기대값과 분산
확률변수의 평균이상적인 기대값 계산 방법확률 변수를 무제한으로 시행하여 얻어진 실현값의 평균이산형 확률변수의 평균(기대값)확률변수가 취할 수 있는 ㄱ밧과 그 확률의 곱의 총합 정의sum of xk x f(xk)기대값이 기호로 표현될 때 E(X)라는 표기 주로 사용2X+
43.결합확률분포와 주변확률분포
2차원 확률변수에서는 1차원 확률분포 2개(X,Y)를 동시에 다룬다.각 확률변수가 취할 수 있는 값의 조합으로 이뤄진 집합과 그 확률에 의해 정의된다.(X,Y)가 취할 수 있는 값의 조합으로 이뤄진 집합을 {(xi,yk)|i=1,2,...; j=1,2,...}각각 조합
44.프로그래머스 가장 큰 수
45.프로그래머스 상위 n개 레코드
46.베르누이분포
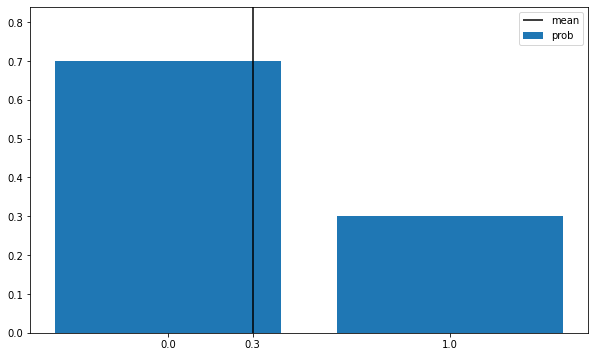
비모수적 기법모집단의 확률 분포에 대한 특별한 가정없이, 평균과 분산이라는 지표를 추정모수적 기법모집단의 성질에 따라 확률 분포의 형태인지를 미리 가정한 후, 기댓값 혹은 분산을 결정하는 소수의 파라미터 추정가장 기본적인 이산형 확률 분포변수의 확률값이 동일성공/실패와
47.이항분포
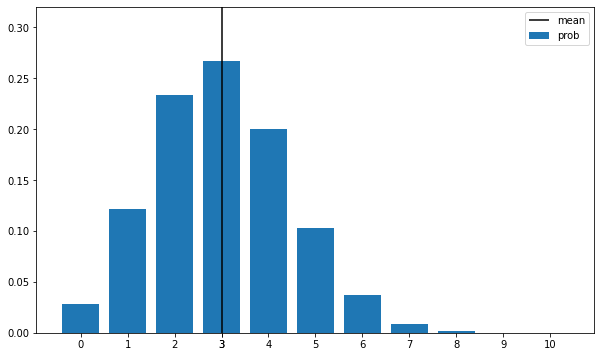
성공 확률이 p인 베르누이 시행을 n번 했을 때의 성공 횟수를 나타내는 분포취할 수 있는 값: 0,1,...,n파라미터: 성공확률 p, 시행 횟수 n0<=p<=1, n은 1이상인 정수라는 조건을 만족해야한다Bin(n,p)로 표기확률함수 공식f(x) = (n
48.2차원 연속형 확률변수의 정의와 지표
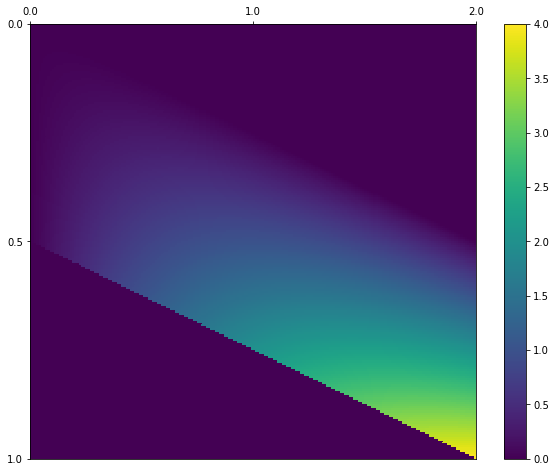
결합확률밀도함수2차원 연속형 확률변수(X,Y)는 확률변수가 취할 수 있는 값의 조합{(x,y)|a<=x<=b; c<=y<=d}정의역으로하는 결합확률밀도함수(f(x,y))에 의해 정의2차원 연속형 확률변수의 확률 정의x0<=X<=x1 및
49.독립성
서로 독립인 다차원 확률변수2개 이상의 확률변수가 서로 영향을 끼치지 않으면서 관계가 없을 나타내는 개념2차원 확률변수(X,Y)의 경우, 다음과 같은 관계식이 성립할 때 독립fX,Y(x,y) = fX(x)fY(y)독립: 확률변수가 다른 확률변수에 서로 영향을 미치지 않
50.합의 분포
특징합의 분포의 이산형 확률함수, 연속형 확률밀도함수를 직접 유도하는 것은 어렵다따라서 합의 분포의 기대값과 분산에 대해 파악하기필요성표본 평균에 대한 이해도를 높이기 위한 사전 준비를 하는 차원에서 합의 분포에 대한 파악이 필요그 후, n으로 나눈 표본평균에 대해서
51.h-index 프로그래머스
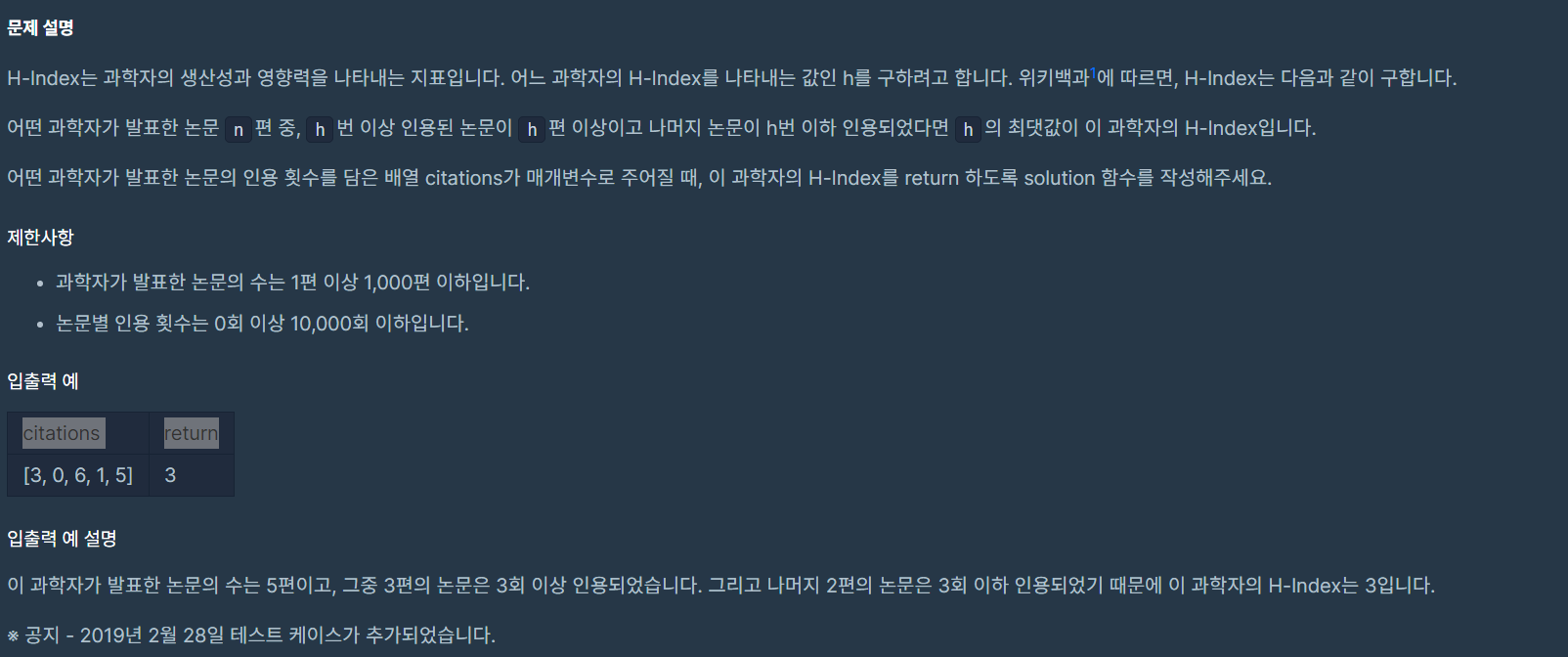
문제 설명
52.모의고사
53.최댓값 구하기
54.최솟값 구하기
업로드중..
55.동물 수 구하기
56.중복 제거하기
업로드중..
57.고양이와 개는 몇 마리 있을까?
58.bytes와_str의_차이_알기
파이썬 코딩의 기술 batter_way03입니다. 앞으로 batter_way90을 공부할 때까지 블로그 포스팅을 진행할 것입니다.부호가 없는 8바이트 데이터 들어감.아스크 인코딩을 활용하여 내부 문자 표시대응하는 텍스트 인코딩 없음decode메서드: 이진 데이터를 유니
59.도우미함수 작성
가독성 저해해석 어려움red_str = my_values.get('빨강','')if red_str0: red =int(red_str0) else: red = 0def get_first_int(values, key, default=0): found =
60.언패킹
tuple: 불변의 순서쌍을 만들어내는 내장 타입숫자 인덱스를 사용하여 튜플 값 접근튜플은 변경이 불가 by 인덱싱언패킹 구문 사용 시 한 문장 안에서 여러 값을 대입튜플이 쌍일 경우 인덱스 대신 두 변수의 이름으로 이뤄진 튜플에 대입튜플 인덱스를 사용하는 것보다 시각
61.enumerate사용
range함수이터레이션할 대상 데이터 구조가 있다면 이 시퀀스에 대해 바로 루프를 돈다.이터레이션하면서 리스트의 몇 번째 원소를 처리 중인지 알 수 있다.인덱스를 사용하기에 배열 원소에도 접근해야한다.단계가 여러 개가 되면 가독성이 떨어지게 된다.
62.zip함수
리스트 컴프르헨션을 사용하면 소스 list에서 새로운 list를 파생되기 쉽다두 리스트를동시에 이터레이션할 경우 names 소스 리스트의 길이를 사용해서 이터레이션할 수 있다.(with 인덱싱)시각적 잡음이 많다.인덱스를 사용해 names와 counts의 원소를 찾는
63.루프_뒤에_else_블록을_사용하지_말라
빈 시퀀스에 대한 루프를 실행하면 else블록이 바로 실행whlie 루프의 조건이 처음부터 False인 경우에도 else 바로 실행핵심파이썬에서 루프와 같은 간단한 구성 요소는 그 자체로 의미가 명확해야 하므로 루프 뒤에 else를 사용하지 말라이유루프 뒤에 오는 el
64.반복을 피해라
대입식: 왈러스 연산자코드 중복 문제를 해결파이썬 3.8에서 새롭게 도입된 구문a :=b대입문이 쓰일 수 없는 위치에서 변수에 값을 대입할 수 있기에 유용하다왈러스 사용 전필요 이상으로 시각적 잡음이 많다else 구문이나 그 이후 블록에게 count변수에 접근을 해야할
65.시퀀스
슬라이싱 구문리스트시작:끝시작 인덱스에 있는 원소는 포함이 되지만 끝 인덱스에 있는 원소는 포함이 되지 않는다리스트의 맨 앞에서부터 슬라이싱할 때는 시각적 잡음을 없애기 위해서 0을 생략리스트의 끝까지 슬라이싱할 때는 쓸데없이 끝 인덱스를 적지 말라리스트를 슬라이싱한
66.스트라이드와_슬라이스
스트라이드일정한 간격을 두고 슬라이싱리스트시작:끝:증가값매 n번째 원소만 가져올 수 있다.x = b'mongoose'y = x::-1print(y)y = x::2z = y1:-1
67.언패킹
기본 언패킹의 한계점언패킹할 시퀀스의 길이를 미리 알아야한다.기본 언패킹으로 리스트 맨 앞에서 원소를 두 개 가져오면 실행 시점에서 예외가 발생한다.해결시각적 잡음이 많다.1차이 나는 인덱스로 인한 오류를 만들기 쉽다.한 줄에서 범위를 변경했는데 모르고 못 고치면 결과
68.key_파라미터
sort는 여러 가지 순서를 지원하는 경우에는 사용할 수 없다.호출하는 객체 비교 특별 메세드가 정의되지 않기에 위와 같은 타입은 정렬할 수 없다.key함수sort의 이러한 단점을 해결.정렬에 사용하고 싶은 애트리뷰트가 객체에 들어 있는 경우 지원하기 위해서 sort의
69.딕셔너리_삽입_순서

파이썬은 타입 지정언어가 아니기 때문에 객체의 동작이 객체의 실질적인 덕 타입핑에 의존한다.요구사항 변경 시 어려운 함정에 빠질 수 있다.변경 시 UI 요소에서 결과를 보여줄 때는 등수가 아닌 알파벳 순서로 표시해야한다.collections.abc모듈 사용알파벳 순서대
70.__ missing__을 사용해 키에 따라 다른 디폴트 값을 생성하는 방법을 알아두라

예시: 파일 시스템에있는 SNS프로필 사진 관리 프로그램위와 같은 방식파일핸들이 딕셔너리 안에 있으면 한 번만 읽는다.없다면 get을 사용하여 딕셔너리 한 번 읽고 try/except블록의 else절에서 핸들 딕셔너리 대입단점딕셔너리를 더 많이 읽게 됨내포되는 블록 깊
71.함수가 여러 값을 반환하는 경우 절대로 네 값 이상을 언패킹하지 말라
위 코드의 문제점호출부분과 반환 값을 언패킹하는 부분이 길다.가독성이 나쁘다
72.None을 반환하기보다는 예외를 발생시켜라
None의 의미유틸리티 함수를 작성할 때 반환 값을 None으로 하면 특별한 의미를 부여하는 경향을 보인다.그로 인해서 아래와 같이 반환 오류가 생긴다.반환값을 2-튜플로 분리첫 번째 부분은 연산의 성공/실패 여부두 번째 부분은 성공한 경우의 실제 결과값을 저장나눗셈
73.클로저
아래 코드의 동작 예상이 되는 이유파이썬 클로저: 자신이 정의된 영역 밖의 변수를 참조하는 함수로 도우미 함수가 sort_priority함수의 group인자 접근자신이 정의된 영역 외부에서 정의된 변수도 참조클로저 내부에 사용한 대입문은 클로저를 감싸는 영역에 영향을
74.시각적인 잡음줄이기
위치 인자(가변 인자(varargs), 스타인자(star args)함수의 호출이 깔끔해진다.시각적 잡음이 줄어든다.활용 예시가변적인 위치 인자의 단점선택적인 위치 인자가 함수에 전달되기 전에 항상 튜플로 변환함수를 호출하는 쪽에서 제너레이터 앞에 \* 연산자를 사용하여
75.키워드인자
파이썬이 딕셔너리에 들어있는 값을 함수에 잔달하면서 각 값에 대응하는 키를 키워드 사용첫 번째키워드 인자를 사용하면 코드를 처음보는 사람들에게 함수 호출의 의미를 명확히 알려준다.위의 예시처럼 어떤 파라미터를 어떤 목적으로 쓰는지 명확해진다.두 번째키워드 인자의 경우
76.디폴트인자
함수 호출 시간 포함 with 독스트링def log(message, when=None): """메시지와 타임스탬프를 로그에 남긴다.log('안녕!')log('다시 안녕!') \`\`\`인자가 가변적인 경우 디폴트값으로 None을 사용하는 것이 중요하다인코딩 값을
77.함수 호출 명확
키워드인자 사용 전키워드인자 사용 후선택사항이므로 예전 방식으로도 호출이 가능복잡한 함수 속 키워드 인자 사용호출자가 키워드만 사용하는 인자를 통해 의도 명목화키워드만 사용하는 인자는 반드시 사용지정절대위치를 기반으로 지정 안됨
78.functools_wrap_함수_데코레이터
데코레이터함수의 호출 전과 후의 코드를 추가로 실행 가능함수의 입력 인자, 반환 값, 함수에서 발생한 오류 접근함수의 의미 강화, 디버깅, 함수 등록의 기능에 유용하다.기호@데코레이터 호출 후 원래 함수가 속해야하는 영역에 같은 이름으로 등록부작용 해결wraps 도우미
79.제어_하위_식
컴프리헨션의 다중 루프 사용루프를 여러 수준으로 내포 허용행렬로 정의된 원소들을 단일 리스트로 단순화2단계 깊이로 구성된 입력 list구조 복제3개 이상 쓸 경우가독성이 너무 떨어진다.파라미터의 추가로 혼동 모델의 혼동 가능성이 높다대책도우미함수를 활용해라
80.반복작업을 피해라
고객의 요청이 재고 수량을 넘지 않고 배송에 필요한 최소 수량rough codefound = {name: get_batches(stock.get(name,0),8) for name in order if get_batches(stock.get
81.제너레이터 활용
시퀀스를 결과로 만들어내는 함수를 만들기메모리크기를 제한할 수 있다.제네레이터를 사용하면 결과를 리스트에 합쳐서 반환하는 것 보다 깔끔제네레이터가 반환하는 이터레이터는 제너레이터 함수의 본문에서 yield가 반환하는 값들로 이뤄진 집합제너레이터를 사용하면 작업 메모리에
82.방어적이_되어라
객체가 들어있는 리스트를 함수가 파라미터로 받을 때 여러번 이터레이션 하는 것이 중요해결이터레이터를 명시적 소진이터레이터의 전체 내용을 리스트화담아둔 리스트에 대해 원하는 수만큼 이터레이션 수행해결책호출될 때마다 새로운 이터레이터를 반환하는 함수 받기lambda활용더
83.제너레이터 식 활용
입력이 길면 리스트 컴프리헨션으로 인해서 메모리를 상당히 많이 사용제너레이터 식 활용
84.yield from
제너레이터를 사용하여 화면의 이미지 움직이기해결yield from식 사용고급 제너레이터 기능제어를 부모 제너레이터에게 전달 전 까지 내포된 제너레이터가 모든 값 내보냄
85.send
데이터를 지속적으로 변경하고 싶다!!send메서드 이용가독성이 좋지 않다 문제점생각보다 가독성이 좋지도 않고 yield 구문으로 인해서 고려할 점도 많다.해결wave함수에 이터레이터 전달이터레이터에서 next 내장 호출 시 하나씩 돌려줌연쇄적 연결을 통해서 입출력 차
86.제너레이터_안에서_throw상태_변화하지_마라
제너레이터 안에서 throw 호출yield로 평소처럼 실행throw가 제공한 Exception다시 던진다.작동은 잘하지만 가독성이 너무 떨어진다.각 내포 단계별로 throw or 호출로 결정되는데 코드 잡음이 많다.해결책: iterlabel class 사용throw메서
87.클래스 합성
동적(dynamic)어떤 값이 들어올지 미리 알 수 없는 식별자유지위의 코드는 너무 확장을 많이 해서 깨지기 쉬운 코드코드를 변경해도 가독성이 떨어질 확률이 높다.내포 단계가 두 단계 이상일 경우 딕셔너리, 리스트, 튜플 계층 추가하지 말 것클래스로 기능 분리캡슐화 해
88.클래스 대신 함수
API의 함수를 변경하는 것: 훅파이썬은 KEY파라미터를 활용하여 변경이 가능파이썬은 일급 시민 객체이다.함수나 메서드를 다른 함수 혹은 변수로 참조 가능파이썬의 여러 컴포넌트 사이에 간단한 인터페이스가 필요할 때는 클래스를 정의하고 인스턴스화하는 대신 간단한 함수 사
89.다형성 활용
파이썬은 객체뿐만 아니라 클래스도 다형성 지원다형성을 사용하면 계층을 이루는 여러 클래스가 자신에게 맞는 유일한 메서드 버전 구현서로 다른 기능을 제공
90.super
첫 번째 부모 클래스 순서에 따른 값은 (5\*2) + 5 = 15두 번째 부모 클래스 순서에 따른 값은 (5\*2) + 5 = 15<class 'main.GoodWay'><class 'main.TimesSevenCorrect'><class 'main.
91.믹스인_클래스
파이썬은 다중 상속(편의와 캡슐화)을 처리할 수는 있지만 골치 아픈 경우를 피하기 위해선 mix-in을 사용할지 고려하라믹스인은 자식 클래스가 사용할 메서드 몇 개만 정의하는 클래스믹스인 클래스는 자체 애트리뷰트 정의가 없기에 믹스인 클래스의 init메서드를 호출할 필
92.공개_애트리뷰트_사용
• 파이썬 컴파일러는 비공개 트리뷰트를 자식 클래스나 클래스 외부에서 사용하지 못하도록 엄격히 금지하지 않는다.• 여러분의 내부 AP 에 있는 클래스의 하위 클래스를 정의하는 사람둘이 여러분이 제공하는 클래스의 애트리뷰트를 사용하지 못하도록 막기보다는 애트리뷰트를 사용
93.collections_abc
컨테이너: 함수와 애트리뷰트를 함께 캡슐화데이터 관리리스트튜플집합딕셔너리추가 사항올바른 시퀀스를 형성하기 위해서 getitem과 len으로는 부족하다.즉, 자신만의 컨테이너 타입을 직접 정의하는 것은 그만큼 어렵다.
94.평범한 애트리뷰트 사용
새로운 클래스 인터페이스를 정의할 때는 간단한 공개 애트리뷰트에서 시작하고, 세터나 게터 메서드를 가급적 사용하지 말라객체에 있는 애트리뷰트에 접근할 때 특별한 동작이 필요하면 @property로 이를 구현@property 메서드를 만들 때는 최소 놀람의 법칙을 따르고
95.공간복잡도
알고리즘 계산 복잡도는 다음 두 가지 척도로 표현될 수 있음시간 복잡도: 얼마나 빠르게 실행되는지공간 복잡도: 얼마나 많은 저장 공간이 필요한지좋은 알고리즘은 실행 시간도 짧고, 저장 공간도 적게 쓰는 알고리즘통상 둘 다를 만족시키기는 어려움시간과 공간은 반비례적 경향
96.애트리뷰트_리팩터링_대신_property사용
지능적인 로직을 수행하는 애트리뷰트 정의가 가능요청에 맞게 애트리뷰트를 바꿀 수 있다.클래스의 내 코드를 바꾸지 않고 동작 변경이 가능이 알고리즘은 시간을 일정한 간격으로 구분하여 가용 용량을 소비할 때마다 시간을 검사주기가 달라질 경우 이전 주기에 미사용한 가용 용량
97.지연 계산 애트리뷰트
파이썬 object훅을 사용하면 제너릭코드를 쉽게 작성getattr과 setattr을 사용해서 객체의 애트리뷰트를 지연해 가져오거나 저장getattr은 애트리뷰트가 존재하지 않으 때만 호출getattribute는 애트리뷰트를 읽을 때마다 항상 호출재귀를 피하려면 sup
98.지연 계산 애트리뷰트
파이썬 object훅을 사용하면 제너릭코드를 쉽게 작성getattr과 setattr을 사용해서 객체의 애트리뷰트를 지연해 가져오거나 저장getattr은 애트리뷰트가 존재하지 않으 때만 호출getattribute는 애트리뷰트를 읽을 때마다 항상 호출재귀를 피하려면 sup
99.동적계획법과_분할정복_
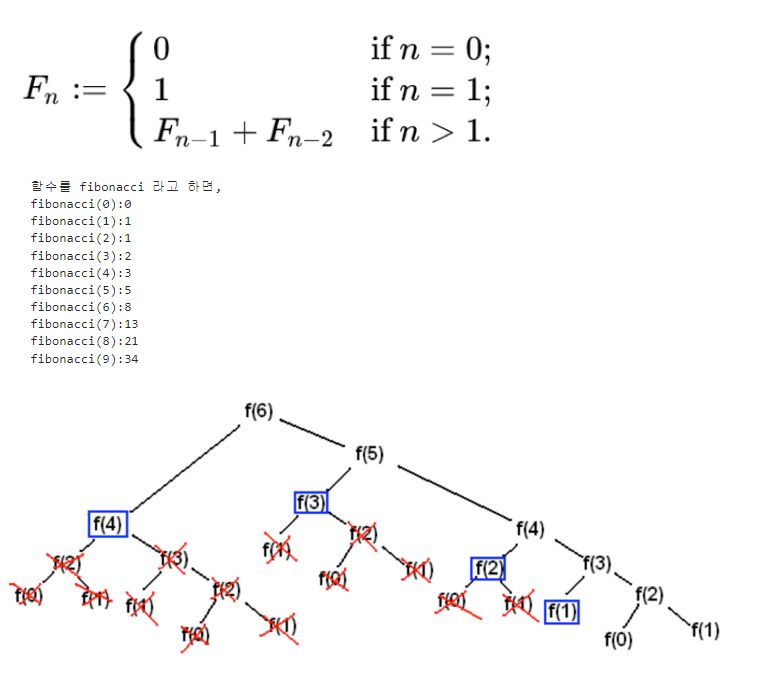
1\. 정의동적계획법 (DP 라고 많이 부름)입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘상향식 접근법으로, 가장 최하위 해답을 구한 후, 이를 저장하고, 해당
100.하위_클래스를_검증
메타클래스를 활용하여 새로운 하위 클래스가 정의될 때마다 검증 코드를 수행하는 신뢰성 있는 방법 제공메타클래스를 구현하는 게 시각적으로 코드의 복잡성을 늘린다.그래서, 파이썬 3.6부터는 init_subclass 특별 클래스 메서드 정의메타클래스의 new 메서드는 cl
101.백준_동적계획법
실전 코딩 테스트 - 동적 계획법 하나하나 해보기
102.클래스 애트리뷰트를 표시하라
메타클래스 기능클래스가 정의된 후 클래스가 실제로 사용 전 프로퍼티 변경 혹시 표시디스크립터 활용애트리뷰트가 포함된 클래스 내부 깊이 살피기set_name 특별 메서드 활용버전: 파이썬 3.6이상메타클래스를 사용하면 어떤 클래스가 완전히 정의되기 전에 클래스의 애트리뷰
103.합성_가능한_클래스_확장
메타클래스를 사용하면 클래스 생성을 다양한 방법으로 커스텀화할 수 있지만, 여전히 메타클래스로 처리할 수 없는 경우가 있다.new((<class 'main.TraceDict'>, ('안녕', 1)), {}) ->{}getitem(({'안녕': 1, '거기': 2}
104.자식 프로세스를 관리하기 위해서 subprocess 사용
동시성컴퓨터가 같은 시간에 여러 다른 작업을 처리하는 것처럼 보이게 하는 것CPU 코어가 하나일지라도 여러 프로그램이 번갈아가면서 실행되면 동시에 수행하는 것 같은 착각을 부른다.어떤 특정 유형의 문제를 해결하기 위한 도구여러 다양한 실행 경로나 다양한 I/O 흐름을
105.큐
대표적인 데이터 구조4: 큐 (Queue)1\. 큐 구조줄을 서는 행위와 유사가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조음식점에서 가장 먼저 줄을 선 사람이 제일 먼저 음식점에 입장하는 것과 동일FIFO(First-In, First-Out) 또는 LILO(L
106.블로킹 I/O의 경우 스레드를 사용하고 병렬성을 피하라
신기하게도, CPU가 많아도 스레드를 사용하면 속도가 느려지기도 한다. 왜냐하면, 표준 CPython 인터프리터에서 프로그램을 사용할 때 GIL(락 충돌과 스케줄링 부가비용)이 미치는 영향을 보여준다.위와 같은 문제가 있어도 파이썬이 스레드를 지원하는 이유다중 스레드를
107.스레드에서 데이터 경합을 피하기 위해서 Lock를 사용하라
GIL은 동시 접근을 보장해줄 순 있어도 보호는 하지 못하므로 프로그램의 상태가 오염될 수 있으니 주의해야한다.파이썬에는 GIL이 있지만, 파이썬 프로그램 코드는 여전히 여러 스레드 사이에서 일어나는 데이터 경합으로부터 자신을 보호해야 한다.코드에서 여러 스레드가 상호
108.큐

줄을 서는 행위와 유사가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조음식점에서 가장 먼저 줄을 선 사람이 제일 먼저 음식점에 입장하는 것과 동일FIFO(First-In, First-Out) 또는 LILO(Last-In, Last-Out) 방식으로 스택과 꺼내는
109.Queue를_사용해서_스레드_사이의_작업_조율하라
Queue 사용 X모든 작업이 다 끝났는지 검사를 하기 위해서 추가로 done_queue에 대해 바쁜 대기(busy waiting)를 수행run메서드가 루프를 무한히 반복작업자 스레드에게 루프를 중단할 시점을 알려줄 방도가 없다.파이프라인 진행이 막힐 경우 프로그램이
110.동시성
프로그램의 영역이 커질수록 복잡도가 증가하게 되는데, 이때 프로그래머는 프로그램의 명확성, 테스트 가능성, 효율성을 유지하면서 늘어나는 요구를 만족시켜야 한다. 그 중에서, 가장 어려운 것은 단일 스레드 프로그램을 동시 실행되는 여러 흐름으로 이뤄진 프로그램 바꾸기프로
111. 병합 정렬 (merge sort)
재귀용법을 활용한 정렬 알고리즘리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.직접 눈으로 보면 더 이해가 쉽다: https://vi
112.요구에 따라 팬아웃을 진행하려면 새로운 스레드를 생성하지 말라
파이썬에서 병렬 I/O를 실행하고 싶을때, 자연스럽게 스레드 사용을 고려하지만 팬아웃을 수행하고자 할 때 스레드를 사용할 경우 큰 단점을 마주하게된다.Thread 인스턴스를 서로 안전하게 조율하려면 특별한 도구가 필요하다스레드는 메모리를 많이 사용하며, 스레드 하나당
113.동시성과 Queue를 사용하기 위해 코드를 어떻게 리팩토링해야 하는지 이해하라
queue 내장 모듈의 Queue 클래스를 사용해서 파이프라인을 스레드로 실행하게 구현아래와 같은 문제 해결Simulate_thread 함수의 방식보다 simulate pipeline함수가 더 따라가기 어렵다코드의 가독성을 개선하려면 ClosableQueue와 Stop
114.I/O를 할 때는 코루틴을 사용해 동시성을 높여라
요구사항마다 팬아웃 팬인을 하면 안된다.!!!!해결: 코루틴을 사용한다.동시성을 활용하는 함수 사용async와 await 키워드를 사용하여 구현제너레이터 실행을 위한 인프라 구축코루틴 시작 비용은 함수 호출해결 후 async함수로부터 실행 재개step_cell을 호출해
115.링크드_리스트

연결 리스트라고도 함배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조링크드 리스트는 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조본래 C언어에서는 주요한 데이터 구조이지만, 파이썬은 리스트 타입이 링크드 리스트의 기능을 모두 지원링크
116.탐욕_알고리즘의_이해
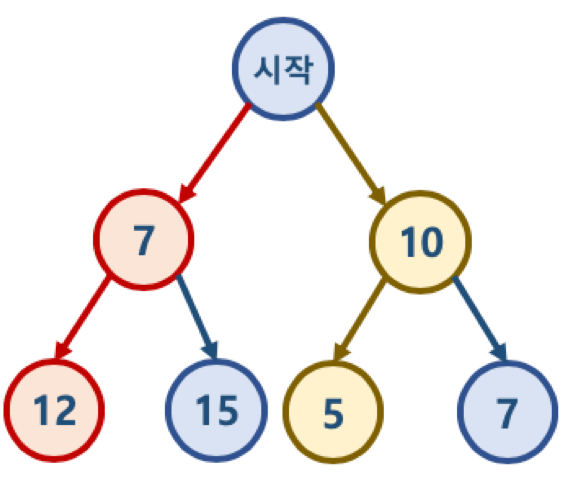
Greedy algorithm 또는 탐욕 알고리즘 이라고 불리움최적의 해에 가까운 값을 구하기 위해 사용됨여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식지불해야 하는 값이 4720원 일
117.백트랙킹
백트래킹 (backtracking) 또는 퇴각 검색 (backtrack)으로 부름제약 조건 만족 문제 (Constraint Satisfaction Problem) 에서 해를 찾기 위한 전략해를 찾기 위해, 후보군에 제약 조건을 점진적으로 체크하다가, 해당 후보군이 제약
118.순차탐색
탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법임의 리스트가 다음과 같이 rand_data_list로 있을 때, 원하는 데이터의 위치를 리턴하는 순차탐색 알고리즘 작성해보기가장
119.스레드와_코루틴을_함께_사용
TDD를 가능하게 하려면, 코드베이스에서 블로킹 I/O에스레드를 사용하는 부분과 비동기 I/O에 코루틴을 사용하는 부분이 서로 호환되고 공존해야한다.스래드 기반 구현으로부터 점진적으로 asyncio 와 코루틴 기반을 바꾸기main 진입점처럼 코드베이스에서 가장 높은 구
120.asyncio_이벤트_루프
문제점출력 파일 핸들에 대한 open, close, write 호출이 주 이벤트 루프에서 이뤄진다.운영체제의 시스템 콜을 사용하므로 이벤트 루프를 상당히 오랫동안 블록할 수 있다.동시성이 아주 높은 서버에서는 응답 시간이 늘어날 수 있다.시스템 콜(블로킹 I/O와 스레
121.진정한 병렬성을 살리려면 concurrent.futures를 사용하라
파이썬 프로그램을 작성하다보면 성능의 벽에 부딪히게 되는데 코드 최적화를 수행해도 필요 수준보다 느릴 수 있다.그렇다고, C언어로 작성하기에 코드 복잡도가 올라가고 한 부분만 C로 작성하는 것도 쉬운 것은 아니다.그래서, CPython or SWIG or CLIF와 같
122.try/except/else/finally의 각 블록을 잘 활용하라
try/ finally블록예외가 발생해도 정리코드를 실행해야할 때 사용파일 핸들을 안전하게 닫기else 블록전달할 예외를 명확히 구분try 블록에 들어가는 코드가 줄어들게 되어서 가독성이 늘어남모든 요소를 한꺼번에 사용하기try/finally 복합문을 사용하면 try블
123.contextlib와_with_문을_사용하라
with문은 코드가 특별한 컨텍스트 안에서 실행되는 경우 표현컨텍스트 매니저를 정의하면 함수의 로그 수준을 일시적으로 높임도우미 함수는 with 블록을 실행하기 직전에 로그 심각성 수준을 높이고, 블록을 실행한 직후에 심각성 수준을 이전 수준으로 회복@contextma
124.지역_시간에는_time보다는_datetime을_사용하라
localtime함수를 사용하여 유닉스 타임스탬프를 호스트 컴퓨터의 시간대에 맞는 지역 시간으로 변환지역 시간은 strftime함수를 사용하여 이해하기 슆게 표현여러 시간대를 다뤄야하는 경우 사용여러 시간대에 속한 시간을 상호 변환여러 다른 시간대를 변환할 때는 tim
125.copyreg
pickle직렬화 형식이 안전하지 않다.악의적인 pickle데이터가 자신을 역직렬화하는 파이썬 프로그램의 일부를 취약하게 만들 수 있다.Json설계상 안전하다객체 계층 구조를 간단하게 묘사한 값이 들어있다.역직렬화해도 추가적인 위험에 노출될 일이 없다.서로 신뢰할 수
126.decimal
디폴트로 소수점 이하 28번째 자리까지 고정소수점 수 연산을 제공자릿수를 더 늘릴 수도 있다.반올림 처리 정확성도 증가숫자가 들어있는 str을 Decimal 생성자에 전달내장 함수를 활용하여 반올림
127.최적화_전_프로파일링
빠를 것 같은데 느리고 느릴 것 같은데 빠른 언어 기능들이 있다. 이러한 것을 직관보단 직접 성능을 측정하는 것을 추천하고 이를 프로파일러라고 한다.암달의 법칙: 프로파일러가 있으므로 프로그램에서 가장 문제가 되는 부분을 집중적으로 최적화하고 프로그램에서 속도에 영향을
128.생산자-소비자 큐로 deque를 사용하라
선입선출(FIFO)처음 들어온 데이터를 더 먼저 사용하는 구조First-In First-Out함수가 처리할 값을 수집하고, 이렇게 수집된 값들을 다른 함수로 처리해야 할 때 도착 순서대로 사용파이썬 내장 리스트 타입을 FIFO로 사용하곤 한다.생산자 함수는 전자우편을
129.biset사용
메모리에 정렬된 리스트로 존재하는 커다란 데이터를 검색프로그램이 구체적으로 처리해야 하는 정보의 유형이 무엇이든, 리스트에서 index함수를 사용해서 특정 값을 찾아내려면 리스트 길이에 선형으로 비례하는 시간이 필요찾는 값이 리스트 안에 들어 있는지 모르다면, 원하는
130.우선순위 큐로 heapq를 사용하는 방법 알기
파이썬이 제공하는 다른 큐 구현들은 선인선출이라는 제약이 있다.그러나, 우선순위 큐는 원소간의 상대적인 중요도에 따라서 원소를 정렬합니다.리스트에서 연체된 책이 있으면 그런 책을 한 권 찾아 큐에서 제거하고 돌려주는 함수를 정의연체된 책들을 찾고, 연체 기간이 가장 긴
131.bytes_복사하지_않고_다루기
파이썬이 CPU 위주의 계산 작업을 추가적인 노력 없이 병렬화는 불가하지만 스루풋이 높은 병렬 I/O를 다양한 방식으로 지원할 수 있다.그러나, 그럼에도 불구하고 I/O 도구를 잘못 사용하여 과부화가 걸려서 속도가 느려질 수 있다.코드로 보는 예시영화나 드라마를 스트리
132.hear
파이썬이 제공하는 다른 큐 구현들은 선인선출이라는 제약이 있다.그러나, 우선순위 큐는 원소간의 상대적인 중요도에 따라서 원소를 정렬합니다.리스트에서 연체된 책이 있으면 그런 책을 한 권 찾아 큐에서 제거하고 돌려주는 함수를 정의연체된 책들을 찾고, 연체 기간이 가장 긴
133.bytes
파이썬이 CPU 위주의 계산 작업을 추가적인 노력 없이 병렬화는 불가하지만 스루풋이 높은 병렬 I/O를 다양한 방식으로 지원할 수 있다.그러나, 그럼에도 불구하고 I/O 도구를 잘못 사용하여 과부화가 걸려서 속도가 느려질 수 있다.코드로 보는 예시영화나 드라마를 스트리
134.deque
선입선출(FIFO)처음 들어온 데이터를 더 먼저 사용하는 구조First-In First-Out함수가 처리할 값을 수집하고, 이렇게 수집된 값들을 다른 함수로 처리해야 할 때 도착 순서대로 사용파이썬 내장 리스트 타입을 FIFO로 사용하곤 한다.생산자 함수는 전자우편을
135.디버깅 출력에는 repr 문자열 사용
파이썬은 컴파일 시점에 정적 타입 검사를 수행하지 않는다. 파이썬 인터프리터가 컴파일 시점에 프로그램이 제대로 작동할 것이라고 확인할 수 있는 요소가 전혀 없다. 파이썬은 선택적인 타입 애너테이션을 지원하여 정적 분석을 수행하여 감지 가능하다. 디버깅을 해야 프로그램
136.linked
연결 리스트라고도 함배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조링크드 리스트는 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조본래 C언어에서는 주요한 데이터 구조이지만, 파이썬은 리스트 타입이 링크드 리스트의 기능을 모두 지원링크
137.스레드를 사용한 I/O를 어떻게 asyncio로 포팅할 수 있는지 알아두라
스레드를 사용한 I/O를 어떻게 asyncio로 포팅할 수 있는지 알아두라 Symmary 파이썬은 for 루프, with 문, 제너레이터, 컴프리헨션의 비동기 버전을 제공하고, 코루틴 안에서 기존 라이브러리 도우미 함수를 대신해 즉시 사용할 수 있는 대안 제공 a
138.스레드와 코루프
TDD를 가능하게 하려면, 코드베이스에서 블로킹 I/O에스레드를 사용하는 부분과 비동기 I/O에 코루틴을 사용하는 부분이 서로 호환되고 공존해야한다.스래드 기반 구현으로부터 점진적으로 asyncio 와 코루틴 기반을 바꾸기main 진입점처럼 코드베이스에서 가장 높은 구
139.backtracking
백트래킹 (backtracking) 또는 퇴각 검색 (backtrack)으로 부름제약 조건 만족 문제 (Constraint Satisfaction Problem) 에서 해를 찾기 위한 전략해를 찾기 위해, 후보군에 제약 조건을 점진적으로 체크하다가, 해당 후보군이 제약
140.클래스 애트리뷰트
메타클래스 기능클래스가 정의된 후 클래스가 실제로 사용 전 프로퍼티 변경 혹시 표시디스크립터 활용애트리뷰트가 포함된 클래스 내부 깊이 살피기set_name 특별 메서드 활용버전: 파이썬 3.6이상메타클래스를 사용하면 어떤 클래스가 완전히 정의되기 전에 클래스의 애트리뷰
141.copyreg
pickle직렬화 형식이 안전하지 않다.악의적인 pickle데이터가 자신을 역직렬화하는 파이썬 프로그램의 일부를 취약하게 만들 수 있다.Json설계상 안전하다객체 계층 구조를 간단하게 묘사한 값이 들어있다.역직렬화해도 추가적인 위험에 노출될 일이 없다.서로 신뢰할 수
142.datetime
localtime함수를 사용하여 유닉스 타임스탬프를 호스트 컴퓨터의 시간대에 맞는 지역 시간으로 변환지역 시간은 strftime함수를 사용하여 이해하기 슆게 표현여러 시간대를 다뤄야하는 경우 사용여러 시간대에 속한 시간을 상호 변환여러 다른 시간대를 변환할 때는 tim
143.TestCase

표준적인 방법:unittest내장 모듈을 쓰는 것이다.테스트는 TestCase의 하위클래스로 구성이 되고 어떤 테스트 메서드가 아무런 Exception도 발생시키지 않고 실행이 끝나면 테스트가 성공한 것이고 일부분이 실패해도 최초로 문제가 생긴 시점에서 멈추지 않고 진
144.동시성_
프로그램의 영역이 커질수록 복잡도가 증가하게 되는데, 이때 프로그래머는 프로그램의 명확성, 테스트 가능성, 효율성을 유지하면서 늘어나는 요구를 만족시켜야 한다. 그 중에서, 가장 어려운 것은 단일 스레드 프로그램을 동시 실행되는 여러 흐름으로 이뤄진 프로그램 바꾸기프로
145.스레드 사용
신기하게도, CPU가 많아도 스레드를 사용하면 속도가 느려지기도 한다. 왜냐하면, 표준 CPython 인터프리터에서 프로그램을 사용할 때 GIL(락 충돌과 스케줄링 부가비용)이 미치는 영향을 보여준다.위와 같은 문제가 있어도 파이썬이 스레드를 지원하는 이유다중 스레드를
146.스레드 사용
신기하게도, CPU가 많아도 스레드를 사용하면 속도가 느려지기도 한다. 왜냐하면, 표준 CPython 인터프리터에서 프로그램을 사용할 때 GIL(락 충돌과 스케줄링 부가비용)이 미치는 영향을 보여준다.위와 같은 문제가 있어도 파이썬이 스레드를 지원하는 이유다중 스레드를