CAM 논문 톹아보기
http://cnnlocalization.csail.mit.edu/Zhou_Learning_Deep_Features_CVPR_2016_paper.pdf
사진들은 논문에서 발췌했습니다.
여기서 물체 지역화(localize objetes)이라는 말은 이미지가 입력되었을 때 영역별로 나누어서 탐색하는 것을 말합니다.
코드 구현: 링크텍스트
Abstract
<논문의 목적>
훈련된 이미지 라벨이더라도, global average pooling layer을 통해서 CNN이 효과적인 localization ability을 갖도록 하는 것이 목적입니다.
<목적 달성을 어떻게 할건가>
이 기술은 일전에 regularizing training의 의미로 제안이 되었지만, 이 논문에서는 a generic localizable deep representation을 만드는 용도로 사용이 된다고 합니다.
A generic localizable deep representation은 이미지 내에서 CNN의 명시적 집중포인트를 드러내는 것입니다.
심지어 GAP가 단순하더라도, 이 논문에서는 bounding box(with training)없이 object localization(물체 주변)을 탐색할 때 top-5 error(37.1%)로 달성했습니다.
즉, a generic localizable deep representation의 기술로 bounding box없이도 주변부 탐색이 가능해졌다는 것입니다.

<실험을 통한 증명>
다양한 실험들을 통해서 이 논문에서 말한 네트워크가 이미지내에 여러 지역들(배경,사람,사물,기타등등) 을 잘 분별할 수 있고 훈련시 이미지 분류 문제도 해결이 가능하다는 것을 증명했습니다
Introduction
- Zhou분이 쓰신 논문
CNNs는 제공된 물체의 지역적인 학습없이 물체 탐색하는 역할이 가능합니다.
이렇게 눈에 띄는 능력이 분류를 위해서 사용되는 fc layer에서 소멸이 됩니다.
- NIN and GoogleNet논문
high performance가 유지되는 동안 파라미터들의 값을 최소화 하기 위해서 fc layer사용하는 것을 피합니다.
Global average pooling(is a structural regularizer)을 사용하여 훈련시에 일어날 과적합을 방지합니다.
실험을 통해서 GAP layer의 장점을 이야기 합니다,
작은 조정을 하면, 네트워크는 주목할만한 localization ability을 마지막 layer가 진행될 때까지 유지가 됩니다.
이 조정은 이미지 영역들을 쉽게 분류하고 인지할 수 있게 합니다.

위의 이미지를 설명하면, 물체 탐색 훈련이된 CNN은 물체를 분류할 때 뚜렷하게 영역별로 구분을 합니다. 그 물체는 사람과 상호작용하는 것들입니다.(칫솔,자전거,나무)
끝으로, 이 논문은 localizability of deep features는 쉽게 다른 인지 데이터셋에 전달이됩니다.
*인지 데이터셋: generic classification, localization, concept discovery
Related Work
CNNs은 시각적 인지 테스크의 다양한 분야에 인상적인 영향을 끼칩니다.
앞에서 말했다시피, 요즘 연구에서 CNNs는 물체를 지역화하는 능력이 뛰어나서 아무리 훈련된 label이 들어와도 효과를 냅니다.
이 논문에서, 적절한 아키텍처를 사용하여 localizing objets능력을 키우고, 이미지 영역을 인지하기 시작하도록합니다.
논문에서 논의되는 내용은 두 가지입니다.
-
weakly supervised object localization
-
Visualizaing the internal representation of CNNs
Weakly-supervised onject localization
- Beragmo 논문
요즘은 CNNs와 약지도학습이 결합된 형태가 연구되는 중입니다.
저자는 자기주도 학습 대상을 위한 기술을 제안합니다.최대 활성화를 유발하는 영역을 식별하기 위해 영상 영역을 마스킹하는 것을 포함하는 로컬라이제이션 사물을 국소화합니다.
- Cinbis 와 Pinheiro논문
localize objects을 위해서 CNN특징과 multople-instance learning결합합니다.
- Oquab논문
저자가 제안한 것은 중간값 수준의 이미지 표현들을 보내고 여러 patch로 겹치는 CNNs의 결과물을 바탕으로 object localization이 잘되는지 보여줍니다.
그러나 저자는 localization ability를 보여주지는 않는다고 합니다.
Visualizing CNNs
[현재 연구(CNNs)]
CNNs로 학습이 된 internal representation는 여러 부분들을 더 이해하기 위한 시도들을 합니다.
Zeiler은 각각의 활성화된 패턴이 무엇인지 시각화하기 위해서 deconvolutional networks를 이용합니다.
Zhou는 CNNs가 장면 인식 훈련을 하는 동안 물체 탐색 기법을 배우는 것을 보여주고, 단일 forward-pass에서 동일 네트워크로 장면 인식과 물체 지역화를 수행하는 것 또한 증명해냈습니다.
Mahendran and Dosovitskiy는 다른 레이어에서 deep features를 전환을 통해서 visual encoding을 분석합니다.
위의 접근들은 fc layer을 전환하여 deep features(연관정보의 highlight없이 )를 표현하는 것을 원합니다.
허나, 논문은 중요하게 분류되는 지점을 정확하게 highlight를 하여 CNNs의 soul로 들어가서 다른 부분들을 보게 합니다.
[현재 연구(layer)]
Conv_layer는 분석을 하고, 불확실한 이미지를 표현하는 fc layer에 관한 것은 무시 합니다.
이를 통해, fc layer은 제거하면서 수행 능력의 지속성이 처음부터 끝까지 지속되기를 원합니다.
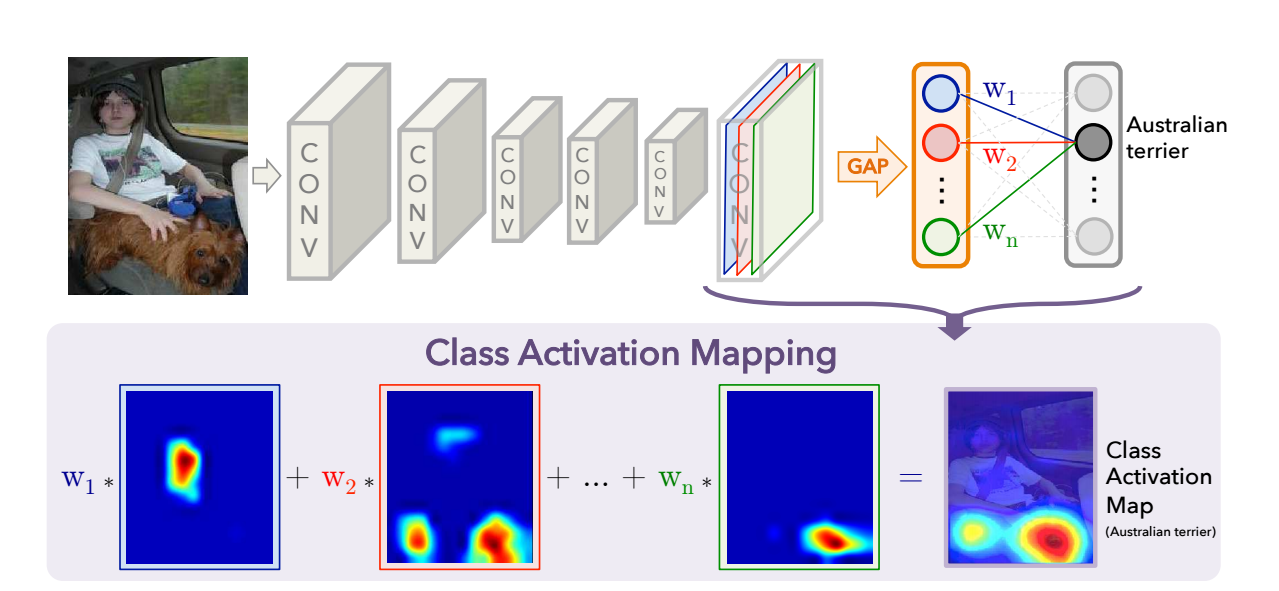
Class Activation Mapping
CNNs에서, GAP를 사용하여 CAM 생성하는 과정에 대해서 서술이 되는 부분입니다.
특정 category위한 CAM은 이미지 영역들을 구분하여 나타냅니다.
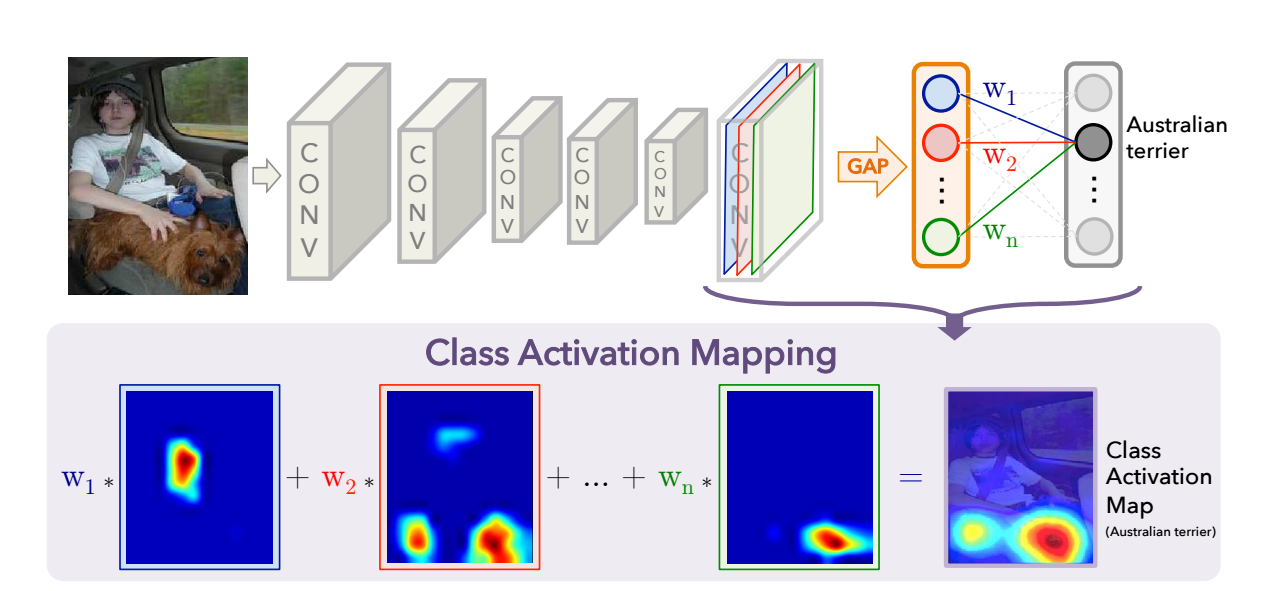
논문에서 사용되는 네트워크 아키텍처는 NIN and GoogleNet이고, 이것들은 크게 convolution layers로 구성이 되어있습니다.
추가적으로, 마지막 output layer(softmax)전에 GAP를 하여서 conv feature maps을 수행하고 fc layer의 features를 사용하여 원하는 output을 갖게 됩니다.
이런 단순한 구조로 인해, 우리는 conv 특성맵에서 output 레이어의 가중치가 집중되는 부분을 통해서 이미지 영역들의 중요도를 알고 명시할 수 있습니다
이러한 이유로, 이 기술은 class activation mapping(CAM)이라고 불립니다.
*그림에 대한 설명 진행하려고 합니다
GAP는 마지막 Con layer에 각 unit의 특성 맵 부분적 평균을 결과물로 갖게 됩니다.
이러한 값들의 가중합은 최종 output을 산출합니다.
비슷하게, 우리는 CAM을 얻기 위해서 마지막 conv layer의 특성맵의 가중합을 이용합니다.
[수식 정보]
*수식

Sc 와 Mc(x,y)는 이미지 분류를 통해서 class c를 알고, 이 부분에서 activation의 중요도를 명시합니다.
이전의 연구에선, 우리는 각 유닛들이 receptive field에서 시각적 패턴에 의해서 활성화가 된다는 걸로 알게 되었습니다.
그러므로 fk는 시각적 패턴의 존재을 보여주는 map입니다.
CAM은 단순히 다른 부분적 locations에서 시각적 패턴의 존재의 가중합산입니다.
CAM을 이용하여 입력 이미지의 사아지를 upsampling, 우리는 이미지의 지역과 가장 유사한 특정 category(위에서 말했던 것 입니다) 로 가리킬 수 있습니다.

위의 사진은 CAMs 결과물들의 예시입니다.
이미지의 다양한 클래스로 분별된 지역들은 highlighted됩니다.
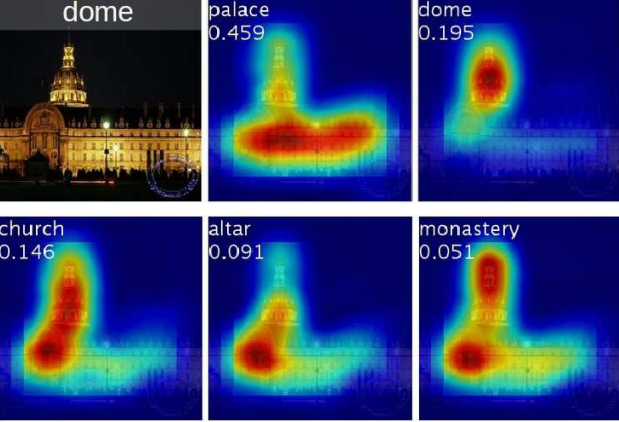
위의 사진은 단일 이미지의 CAMs에서 highlight가 다르게 된 클래스들입니다.
다른 카테고리들을 위해 분별된 지역들은 주어진 이미지로부터 다르게 보입니다.
Global average pooling(GAP) VS Global max pooling(GMP)
이제 이 부분에서 정량적 비교(GAM 와 GAP의 차이)를 설명할 겁니다.
GAP는 물체의 전반적인 부분을 인식하는 반면, GMP는 물체의 뚜렷한 한 부분만 인식합니다.
왜냐하면, GAP는 값이 최대최소로 설정이 되어서 물체의 모든 부분을 찾기에 모든 low activatios는 특정 맵의 결과값을 감소합니다.
허나, GMP는 가장 뚜렷한 한 부분을 제외하고 모든 이미지의 low scores는 최대값에 영향을 주지 못합니다.
위의 과정에 대한 결과에 대한 이유를 다음 챕터에서 ILSVRC dataset을 통해서 설명하겠습니다.
결론적으로, GMP는 GAP과 유사한 분류 성능을 달성하고,
GAP는 localization 측면에서 GMP를 능가합니다.
Weakly-supervised Object Localization
ILSVRC 2014 dataset를 가지고 CAM의 localization ability을 평가할겁니다.
여기서 설명할 것은 experimental setup과 다양한 CNNs의 활용입니다.
우리의 기술이 분류문제에 악영향을 미치지 않는다는 것을 증명하고 약지도학습 바탕으로 세부적인 결과를 제공하는 법과 localize를 배우는 법을 알려줍니다.
Setup
[실험 목적]
다양한 CNNs에서도 CAM효과가 나타나는지
[CNNs]
AlexNet, VGGnet, GoogLeNet
보통, 이런 네트워크들은 최종 결과물이 나오기 전에 fc layer을 제거하고 GAP(followed fc softmax layer)와 대체됩니다.
fc layer을 제거하는 이유는 네트워크의 파라미터를 줄여주기 때문입니다.(ex: 90 % less in VGGnet)
저자는 네트워크의 localization ability가 향상되는 지점을 발견합니다.
그 지점은, GAP가 mapping resolution을 갖기 전 마지막 컨볼루션 레이어입니다.
Mapping resolution을 따르면, 우린 네트워크로부터 여러 개의 conv layer을 제거합니다. 그리고 여러 변형들이 생기는데 이를 위의 CNNs들을 예시로 삼아 설명하겠습니다.
[For AlexNet]
remove layer: conv5이후에
mapping resolution: 13 x 13
[For VGGnet]
remove layer: conv5-3이후
mapping resolution: 14 x 14
[For GoogLeNet]
remove layer: inception4e이후
mapping resolution: 14 x 14
[추가로 논문이 한 것]
이 부분은 논문에서 위의 네트워크에 추가적으로 한 것들에 대한 서술입니다.
-
Add: 3 x 3 convolutional layer, stride =1 , pad 1 with 1024 units (where?: GAP layer and softmax layer)
-
Fine-tuned: ILSVRC의 1.3M 훈련 이미지
-
1000-way object classification resulting.
아래 부분들의 구체적인 내용은 Results에서 보실 수 있습니다.
[For classification]
- 논문에서 제시한 방식과 기존의 CNNs, NIN 들간의 비교입니다.
[For localization]
- 논문에서 제시한 방식과 기존의 GoogleNet, NIN비교와 CAMs대신 역전파를 사용합니다.
- GAM 와 GMP비교합니다
- GMP로 훈련된 GoogleLeNet 제공합니다.
[평가하는 법]
-
Same error matrics(top-1, top-5)
-
ILSVRC
-
Classification: ILSVRC validation set
-
Localization: ILSVRC validation set and test sets
Results
첫 보고서 결과, 물체 분류는 엄청 분류를 수행하는 부분을 고려하지 않습니다.
그러므로 논문은 그저 약지도학습이 object localization에 효과적인지에 대해서 증명합니다
Classification

*위의 그림은 GAPn과 original의 분류 수행능력 요약입니다.
-
drop 1~2%(추가적인 레이어 제거 시)
-
AlexNet이 가장 큰 영향을 받았다.
-
GAP를 AlexNet에 보충하니 기존과 비교못할 정도로 효과가 좋아졌습니다.(GAP효과 있음을 증명)\
-
GoogLeNet-GAP and GoogLeNet-GMP의 분류 성능은 비슷합니다.
-
네트워크가 분류에서 잘 수행되는 것이 중요합니다.
localization에 대한 높은 성능을 달성하기 위해
개체 범주와 경계 상자 위치를 모두 정확하게 식별하는 작업이 포함됩니다.
Localization
바운딩 박스 생성과 바운딩박스와 관련된 물체 category가 필요합니다.
Thresholding technique는 CAMs로부터 바운딩 박스를 생성하기 합니다.
그리고, 첫 segment regions의 값은 CAM의 최댓값 * 0.2한 값 이상입나디.
Top-5 예측된 클래스(for top 5 localization 평가 행렬)

*thresholding 기술로 인해서 생긴 바운딩 박스 예시
*ILSVRC validation set

*예시의 결과값
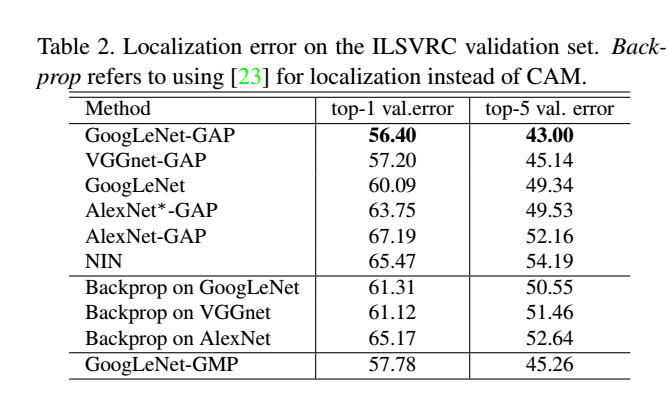
[실험결과 GoogLeNet]
GoogLeNet-GAP는 TOP-5에서 가장 낮은 에러인 43%를 달성했습니다.
GoogLeNet(7x7)는 정확한 localization이 얻어지는 것을 막아줍니다.
GoogLeNet-GAP는 GoogLeNet-GMP보다 물체의 전반전인 부분들을 인식하는 수행력이 좋습니다.
[약지도학습과 지도학습 IN CNN 비교]
- 평가: GoogLeNet-GAP on the ILSVRC test set.
-
다른 바운딩 박스 선택 전략
- Select Two bounding box
- One tight: the top 1st~2nd predicted class
- One loose: the top 3rd predicted class
이로 인해, 분류 정확성과 localization 정확성 사이의 trade off가 일어납니다.
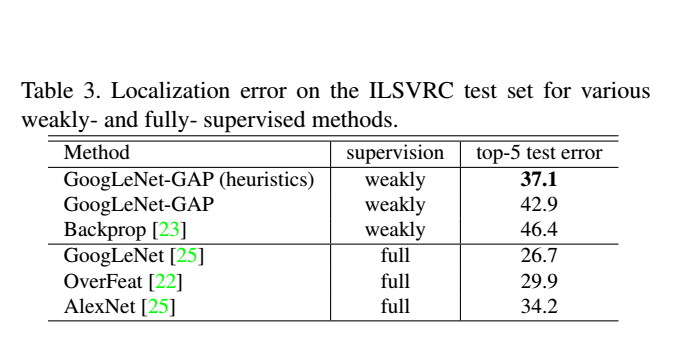
GoogLeNet-GAP : 37.1%(약지도학습)
AlexNet : 34.2%(지도학습)
Deep Features for Generic Localization
CNN의 higher lever layers들의 반응들은 SOTA수행능력을 보이는 generic features가 다양한 데이터셋에서 효과적이라는 것을 증명합니다.
GAP CNNs로 학습이된 특징들은 또한 generic features를 잘 수행하고, 이미지 영역을 또렷하게 인식합니다.
본래의 softmax layer과 비슷한 가중치를 얻기 위해서, 우리는 GAP 레이어의 결과부분 선형SVM으로 훈련합니다.

*Compare the performance of features
-
GoogLeNet-GAN and GoogLeNet는 AlexNet보다 수행력이 좋습니다.
-
GoogLeNet-GAN and GoogLeNet는 convolutional layer이 몇 개 없지만 비슷하게 수행합니다.
전반적으로, GoogLeNet-GAP특징들은 SOTA(generic visual features)에서 경쟁력을 보입니다.
더 중요한 것은 CAM 기술(with GoogLeNet-GAP)을 사용하여 생성된 localization 맵이 시나리오에서도 유익합니다.

위의 그림은 다양한 데이터 세트에 대한 몇 가지 예시 맵을 보여줍니다.
가장 구별되는 영역이 모든 데이터 세트에서 강조 표시되는 경향이 있음을 관찰합니다.
전반적으로 우리의 접근 방식은 효과적입니다
Fine-grained Recognition
-
Generic localizable deep features
-
CUB-200데이터셋
-
200여종의 새 인식
-
Training image: 5,994장
-
Test image: 5,794장
-
-
GoogLeNet-GAP: 63.0%정확성(without bounding box)
GoogLeNet-GAP: 70.5%정확성(With bounding box)
localization 능력은 fine-grained recognition을 위해서 매우 중요합니다.
*fine-grained recognition은 더 좋은 분류를 위해서 이미지가 짤린 부분 과 카테고리 사이의 미묘한 차이를 말합니다.
 g
g
- GoogLeNet-GAP가 새를 localization을 할 때, IoU는 0.41이 나왔습니다.
Pattern Discovery
논문의 기술이 이미지의 패턴이나 흔한 요소를 인식할 수 있습니다.
흔한 개념을 유지하는 이미지 셋이 주어진다면, 우리는 입력패턴과 중요하게 인색이 되는 영역을 인식하기를 원합니다
논문에서, GoogLeNet-GAP 네트워크의 GAP 계층에서 선형 SVM을 훈련하고 CAM 기술을 적용하여 중요한 영역을 식별합니다.
우리는 심층 기능을 사용하여 세 가지 패턴 발견 실험을 수행했습니다. 결과는 아래에 요약되어 있습니다.
이 경우 훈련 및 테스트 분할이 없다는 점에 유의하고,시각적 패턴 발견을 위해 CNN을 사용합니다.
Discovering informative objects in the scenes
-
SUN dataset
- 10 scene categories
- containing: 200 fully annotated images
- resulting: 4675 fully annotated images

CAM을 플롯예측 장면 범주에 대해 상위 6개 개체 나열해서 높은 CAM 활성화와 가장 자주 겹치는 항목이
두 장면 범주에 대한 영역입니다.
우리는 높은활성화 영역은 종종 특정 장면 범주를 나타내는 객체에 해당합니다.
Concept localization in weakly labeled images
하드 네거티브 마이닝 알고리즘을 사용하여 다음을 학습합니다.
개념 감지기를 사용하고 CAM 기술을 적용하여 이미지의 개념을 localization합니다.
이에 대한 개념 탐지기를 훈련하려면 짧은 문구, positive 세트는 텍스트 캡션에 짧은 문구가 포함된 이미지로 구성되며, negativ 세트는 아무 것도 없이 무작위로 선택된 이미지로 구성됩니다.
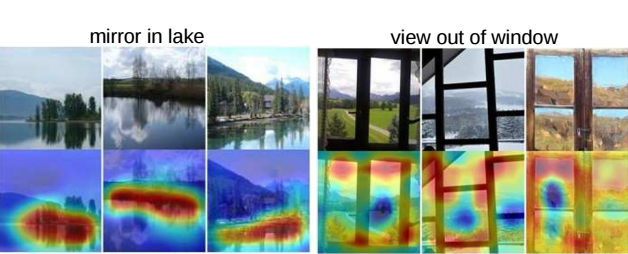
*텍스트 캡션의 관련 단어를 시각화합니다.
2개의 개념 감지기에 대한 최상위 이미지 및 CAM. CAM은 정보 영역을 localization을 하면 구문이 일반적인 개체 이름보다 훨씬 더 추상적임에도 불구하고 개념이 딱 보이게 됩니다.
Weakly supervised text detector
-
SVT dataset
-
약지도학습
-
positive set: 350 Google StreetView images text
-
negativee set: 무작위로 샘플이미지(from 외부 풍경 이미지)
-
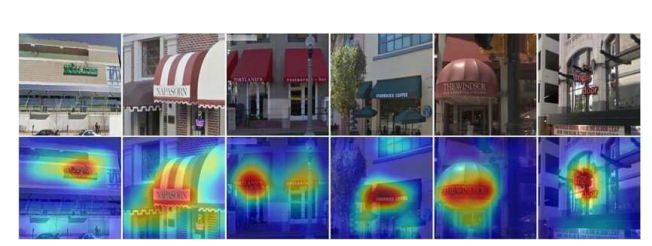
*바운딩 박스 없이 text에 highlights를 합니다
Interpreting visual question answering
시각적 질문 답변을 위해 제안한 기준선의 접근 방식 및 지역화 가능한 심층 기능이고 테트 표준의 정확도 55.89%가 나오게 됩니다.

*예측된 답변과 관련된 이미지 영역을 강조 표시합니다.
Visualizing Class-Specific Units
Zhou은 컨볼루션 단위가 CNN의 다양한 레이어는 시각적 개념 감지기 역할을 하여 textures or materials 와 같은 높은 수준의 개념으로 식별합니다.
더 깊게 네트워크에 들어가면 단위가 점점 더 구별됩니다. 그러나 많은 계층에서 완전히 연결된 레이어를 고려할 때
네트워크의 중요성을 식별하기 어려울 수 있습니다.
다른 범주를 식별하기 위해서 여기서 GAP와 순위가 매겨진 softmax 가중치를 사용하여 직접 주어진 것에 대해 가장 구별되는 단위를 시각화합니다.
여기서 우리는 그것들을 CNN의 클래스별 단위라고 부릅니다.

*AlexNet-GAP클래스별 단위를 보여줍니다. 객체 인식을 위한 ILSVRC 데이터 세트(상단) 및 장면 인식을 위한 장소 데이터베이스(하단).
수용 필드 추정 및 각 유닛의 상위 활성화 이미지를 분할하는 단계인 최종 컨볼루션 레이어 와 비슷한 절차가 따릅니다.
그런 다음 우리는 단순히 softmax 가중치를 사용하여 주어진 클래스에 대한 단위의 순위를 지정합니다.
그림에서 분류를 위해 가장 구별되는 물체의 부분과 정확히 어떤 단위가 감지하는지 식별할 수 있습니다
이러한 부분. 예를 들어 개의 얼굴을 감지하는 장치와
레이크랜드 테리어에게 몸의 털은 중요합니다. 소파, 테이블 및 벽난로를 감지하는 장치는 거실에 중요합니다.
따라서 우리는 CNN이 실제로 다음과 같이 학습한다고 추론할 수 있습니다. 여기서 각 단어는 클래스별로 구별되고 이러한 클래스별 단위의 조합은 다음을 안내합니다.
그로 인해, CNN은 각 이미지를 분류합니다.
Conclusion
이 작업에서 우리는 클래스라는 일반적인 기술을 제안합니다.
GAP 사용하는 CNN용 CAM(활성화 매핑)풀링을 통해 분류 훈련된 CNN이 학습할 수 있습니다.
경계를 사용하지 않고 객체 현지화를 수행하기 위해 상자 주석과 클래스 활성화 맵을 통해 시각화할 수 있습니다.
우리 ILSVRC 벤치마크에서 Weakly Supervised Object Localization에 대한 접근 방식을 평가하여 GAP 풀링 CNN은 정확한 객체를 수행할 수 있습니다.
Localization. 또한 CAM 현지화 기술이 다른 시각적 인식으로 일반화됨을 보여줍니다.
즉, 우리의 기술은 일반 지역화 가능한 딥을 생성하고. 다른 연구자가 이해하는 데 도움이 될 수 있는 기능 CNN이 작업에 사용하는 차별화의 근거입니다.
