논문 링크:링크텍스트
StyleGAN
-
고화질 이미지 생성에 적합한 아키텍처
- PGGAN 베이스라인 아키텍쳐 성능 향상
- Disentanglement 특성 향상
- 고해상도 얼굴 데이터셋(FFHQ) 발표

관련 연구
GAN
-
생성자와 판별자 두 개의 네트워크 활용한 생성 모델
-
목적 함수를 통해 생성자는 이미지 분포 학습 가능
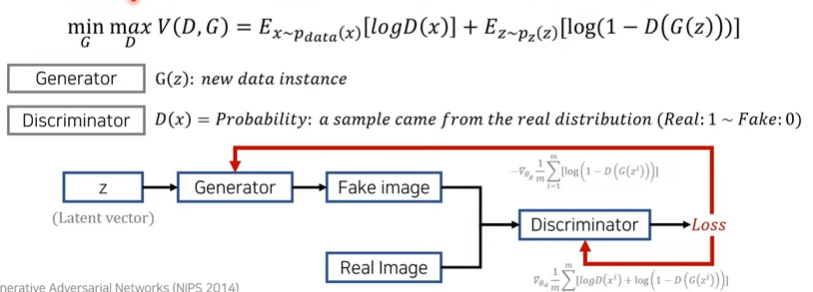
DCGAN
- Deep Convolutinoal Layers이용하여 이미지 도메인에서의 높은 성능 보임
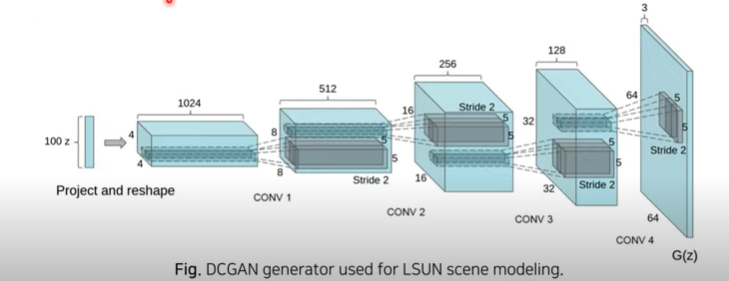
- Convolutional filters
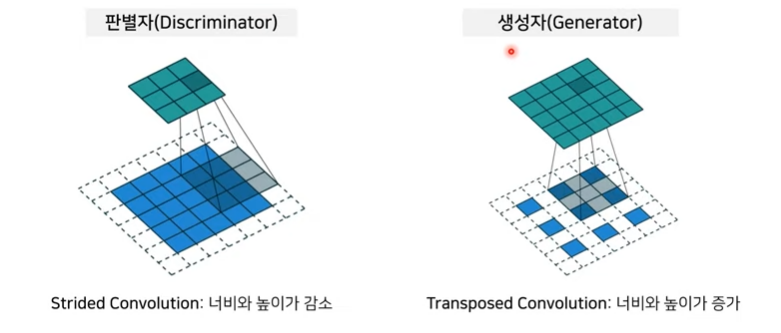
- 벡터 연산

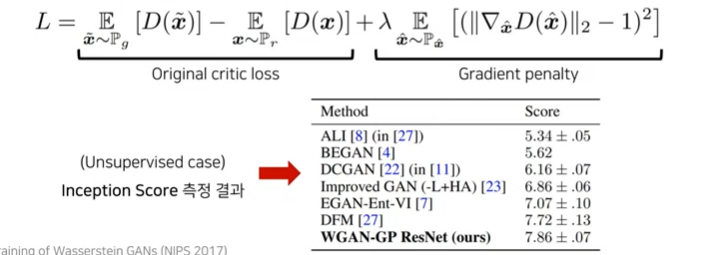
WGAN-GP
- WGAN, 함수가 1-Lipshichtz조건 만족하여 안정적 학습 유도
- weight clipping을 이용하여 제약 조건 만족
- WGAN-GP, gradient penalty이용하여 WGAN의 성능 개선
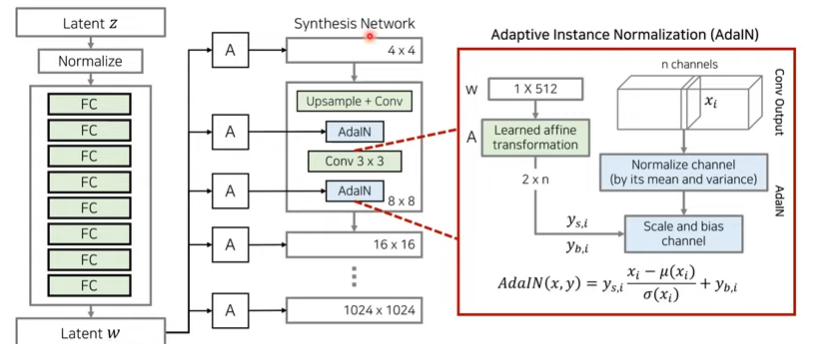
ADaIN
-
AdaIN이용 시 다른 원하는 데이터로부터 스타일 정보 가져와서 적용
-
학습시킬 파라미터가 필요하지 않음
-
정규화 후 별도의 스타일 데이터를 받아 feature상에 적용
-
다양한 스타일이 반영되게 만든 후 합성을 한다
-
feed-forward방식의 style transfer 네트워크에서 사용되어 좋은 성능 보임
-

- 구조
-
테크닉
-
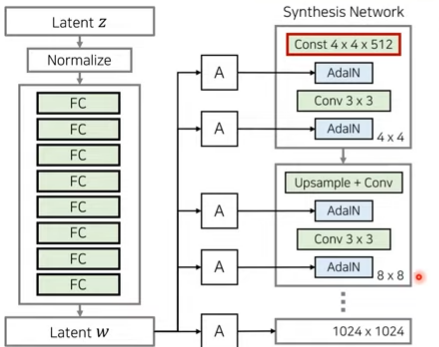
Removing Traditional Input
- 초기 입력을 상수로 대체
- 경험적으로 성능이 향상
-
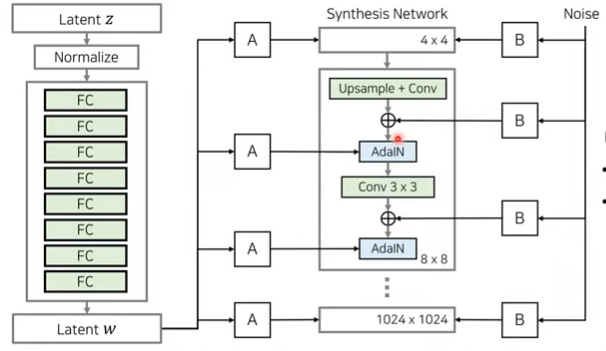
Stochastic Variation(노이즈)
-
다양한 확률적인 측면 컨트롤
-
주근깨, 머리카락의 배치
-
Noise 벡터를 인풋으로 이용
-
Coarse noise: 큰 크기의 머리 곱슬이나 배경
-
Fine noise: 세밀한 곱슬머리, 배경
-
경우의 수

-
a: 모든 레이어에 노이즈 적용
-
b: 노이즈 적용안함
-
c: Fine layer적용
-
d: Coarse layer적용
-
-
-
- 초기 입력을 상수로 대체
-
연구배경
PGGAN(=proGAN)
-
메인 아이디어
- 학습 과정에서 레이어 추가
- 고해상도 이미지 학습 성공
-
한계점
- 이미지의 특징 제어가 어려움 -> Style GAN이 개선함

- 학습 진행 과정, 점진적으로 네트워크의 레이어 붙인다

StyleGAN
-
고화질 이미지 생성에 적합한 아키텍처
- PGGAN 베이스라인 아키텍쳐 성능 향상
- Disentanglement 특성 향상
- 고해상도 얼굴 데이터셋(FFHQ) 발표
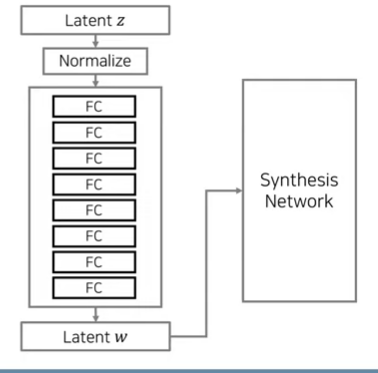
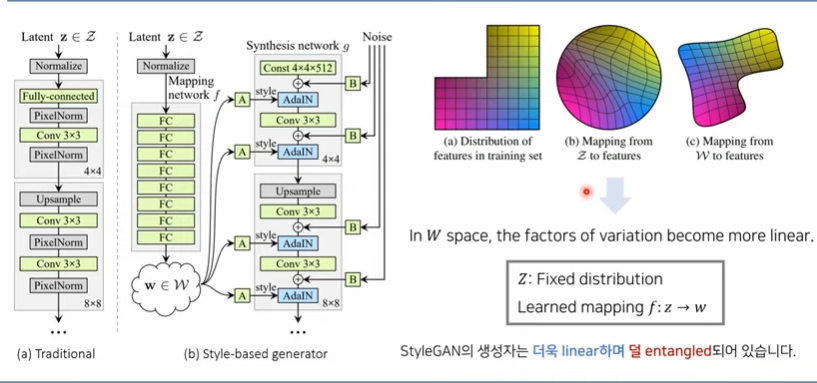
Mapping Network
-
512차원의 z 도메인에서 w도메인으로 매핑 수행
-
가우시안 분포에서 샘플링한 z벡터 직접 사용X
- 계산된 w벡터 사용함
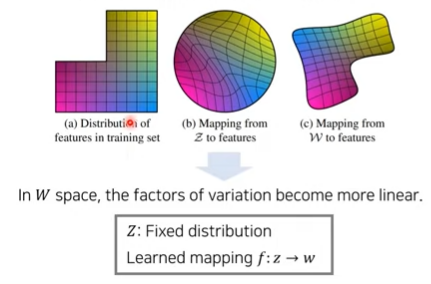
Disentanglement Properties of StyleGAN
Latent Vector Meanings of StyleGAN

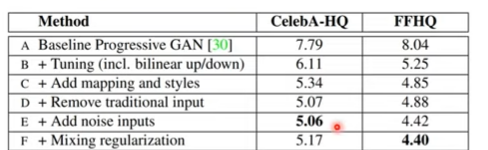
Evaluation : FID 값 비교/ 분석
-
A: PGGAN 베이스 라인
-
B: Bilinear up/downsampling operations
-
C: Mapping Network+AdaIn
-
D: Input 레이어로 학습된 4 4 512 상수 텐서 사용
-
노이지 입력
-
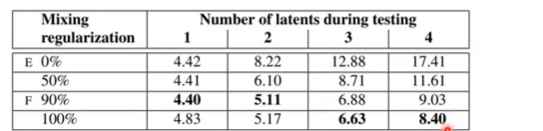
Mixing Regularization
Style Mixing(Mixing Regularization)
-
인접한 레이어 간의 스타일 상관관계 줄인다
-
구체적인 Mixing Regularization 방법
- 두 개의 입력 벡터 준비
- 크로스오버 포인트 설정
- 크로스오버 이전은 w1, 이후는 w2를 사용한다

- 스타일은 각 레이어에 대해 지역화가 된다
Latent Vector Meanings

Disentanglement 관련 두 가지 성능 측정 지표 제안
-
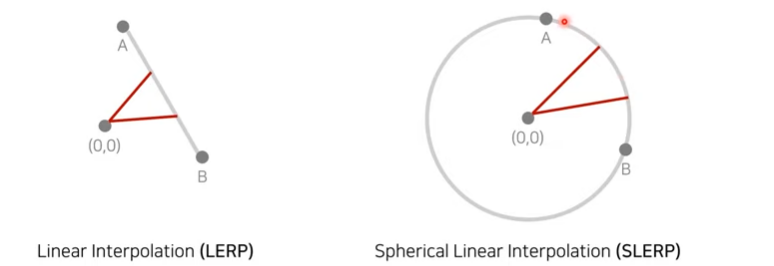
Path Length: 두 벡터를 보간, 얼마나 급격하게 이미지 특징 바뀌는지 확인
- 지점 t와 t+e사이에서의 VGG특징의 거리가 얼마나 먼지 계산
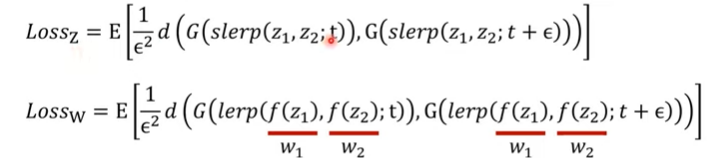
-
Separability: latent space에서 attributes가 얼마나 선형적 분류되는지 평가
-
CelebA-HQ: 얼굴마다 성별등의 40개의 binary attributes가 명시되어 있는 데이터셋으로 분류 모델을 학습한다
-
하나의 속성마다 200,000개의 이미지 생성 및 분류 모델에 넣기
- 이후, confidence가 낮은 절반은 제거하여 100,000개의 레이블이 명시된 latent vector 준비
- 100,000개의 데이터를 학습데이터
-
매 속성마다 linear SVM모델 학습
- 전통적인 GAN에서는 z, Style GAN- w 사용한다
-
각 linear SVM모델 활용하여 다음값 계산 (i= 각 속성의 인덱스)

-
-
W공간이 Z공간보다 이상적이다
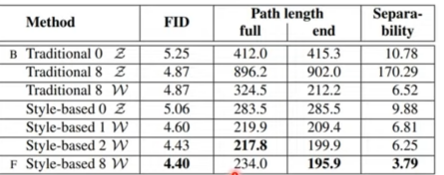
Latent Vector Interpolations
추가적인 실험 결과

-
동일한 세팅으로 추가 실험
- LSUN Bedroom 데이터 셋
- LSUN Car 데이터 셋
-
Coarse styles 변화
- 카메라 구도
-
Middle styles 변화
- 특정 가구
-
Fine styles 변화
- 세밀한 색상, 재질
