목차
- 머신러닝 알고리즘
- 사이킷런에서 알고리즘
- Scikit-Learn
-데이터 표현법
-회귀 모델 실습
-datasets모듈
머신러닝
- 정의: 컴퓨터가 학습 능력을 갖추게 하는 행위
- 간략한 시스템
training set -> 학습 ->validation set-> test set -> accuracy측정.
-데이터 마이닝(data mining):대용량의 데이터 분석하면 겉으로 보이지 않던 패턴 발견.
머신러닝 사례
-
생산 라인에서 제품 이미지를 분석해 자동 분류: 이미지 분류 작업.CNN사용
-
뇌를 스캔하여 종양 진다: 시맨틱 분할 작업.CNN->이미지의 각 픽셀 분류
-
자동으로 뉴스 기사 분류: NLP작업. 텍스트 분류. RNN, CNN, Transformer사용
-
부정적인코멘트 자동 구분: NLP작업. 텍스트 분류
-
긴 문서 자동 요약: 텍스트 요약. NLP작업
-
챗봇 또는 개인 비서 만들기: 자연어 이해(NLU) 와 Q & A 모듈 사용
-
내년도 수익 예측: 회귀 작업. SVM사용. 인공NN사용. 지난 성능 시퀀스를 고려할 때는 RNN, CNN 또는 트랜스포머 사용
8.음성 명령에 반응 앱: 음성 인식 작업. 오디오 샘플 처리. RNN, CNN , Transformer사용
-
신용카드 부정 거래 감지: 이상치 탐지 작업
-
구매 이력 기반 마케팅 전략: 군집 작업
-
의미 있는 그래프 표현: 데이터 시각화 및 차원 축소 기법
12.과거 구매 이력 기반으로 상품 추천: 추천 시스템.인공 신경망이용.
- 지능형 게임 봇 만들기: 강화학습(RL)으로 해결
어떤 알고리즘을 써야하는지 판단 요인
1.데이터의 크기, 품질, 특성
2.가용 연산(계산) 시간
3.작업의 긴급성
4.데이터를 이용해 하고 싶은 것
머신러닝 알고리즘 차트 시트 이용
1.정의: 특정문제에 적합한 알고리즘 선택 도움을 줌(물론 정확하게 맞진 않음)
사용방법
i)차트의 경로와 알고리즘 레이블 읽기 if then use :(만약 <경로 레이블>이면 <알고리즘>을 사용한다.)
ii)ex]
If you want to perform dimension reduction then use principal component analysis.
(차원 축소를 수행하고 싶으면 주성분 분석을 사용한다.)
-주성분 분석: 고차원 데이터 ->저차원 데이터 (환원)
If you need a numeric prediction quickly, use decision trees or logistic regression.
(신속한 수치 예측이 필요하면 의사결정 트리 또는 로지스틱 회귀를 사용한다.)
-사건의 발생 가능성을 예측할 때 도움되는 통계 기법
If you need a hierarchical result, use hierarchical clustering.
(계층적 결과가 필요하면 계층적 클러스터링을 사용한다.)
-여러개의 군집 중에서 가장 유사도가 높은 혹은 거리가 가까운 군집 두 개를 선택하여 하나로 합치면서 군집 개수를 줄여 가는 방법을 말한다.
머신러닝 종류
0.0
-
사람의 감독하에 훈련하는 것인지 아닌지(지도, 비지도, 준지도, 강화학습)
-
실시간으로 점진적 학습인지 아닌지( 온라인 학습과 배치 학습)
-
알고 있는 포인터와 새 포인터 비교인지 아니면 훈련데이터 셋을 통해 패턴발견하여 예측 모델을 만드는 것인지(사례 기반 학습과 모델 기반 학습)
0.아래 세 가지가 합쳐서 사용될 때도 있고 전환될 때도 있다. 즉 유기적 시스템이라는 것에만 유의하자.
1.지도학습(Supervised Learning)
: 훈련 데이터에 원하는 답이 포함(label)
-
분류(classification)가 전형적인 지도 학습 작업.
:한 세트의 사례들을 기반으로 예측 수행
:입력변수&출력변수
: 학습용 데이터 기반.
:학습용 데이터 일반화->새로운 사례 매핑, 미래예측.
:자료가 방대할 때 주로 사용(고로, 시간 소요 큼) -분류(Classification):데이터가 범주형 변수(이미지,레이블,지표) 예측.
:레이블이 두 개면 이진 분류
:범주가 두 개 이상이면 다중 클래스 분류.
-회귀(Regression): 특성을 사용해 타깃 수치 예측. 주어진 입력 특성으로 값 예측
-예측(Forecasting):과거 및 현재 데이터-> 미래 예측. (동향 분석)
ex)
스팸 필터
- 지도학습 알고리즘
- k-최근접 이웃(k-nearest neighbors)
- 선형 회귀(linear regression)
- 로지스틱 회귀(logistic regression)
- 서포트 벡터 머신(support vector machine[SVM])
- 결정 트리(decision tree) 와 랜덤 포레스트(random forest)
- 신경망(neural networks)
- k-최근접 이웃(k-nearest neighbors)
2.준지도 학습(Semi-supervised learning)
:일부만 레이블이 있는 데이터 다룸
:분류된 자료가 한정적일 때, 지도학습 개선위해 미분류(unlabeled)사례 이용. (=기계가 온전한 지도X )
:미분류 사례+ 소량분류--> 학습 정확성 개선
ex)
1. 구글 포토 호스팅 서비스(by 군집)
-
심층 신뢰 신경망(DBN)
:제한된 볼츠만 머신(RBM)에 의해 세밀하게 조정
3.비지도학습(Unsupervise Learning)
: 훈련데이터에 레이블이 없어 시스템이 아무런 도움없이학습
:미분류 데이터만 제공 받는다.
-군집(Clustering): 특정 기준->유사 데이터 그룹화 -->여러 그룹 분류-->고유 패턴 찾고 개별 그룹 차원에서 분석 수행이 가능함 . 비슷한 것들을 그룹하여 더 작은 그룹으로 세분화.
ex)
1. K- means(K-평균)
- DBSCAN
- HCA( 계층 군집 분석)
- 이상치 탐지(outlier detection) 와 특이치 탐지(novelty detection)
- 원-클래스 (one-class SVM)
- 아이솔레이션 포레스트(isolation forest)
-차원 축소(Dimension Reduction): 비슷한 작업으로 너무 많은 정보를 잃지 않으면서 데이터 간소화. 방식은 상관관계가 있는 여러 특성을 마모의 정도를 기반으로 하나로 합치면 된다.(=특성 추출)
-시각화(visualization) : 레이블이 없는 대규모의고차원 데이터를 넣으면 도식화가 가능한
2D 나 3D로 표현. 공간이 떨어져도 겹치지 않게 유지되어있다.
ex) 시각화 와 차원 축소
- 주성분 분석(PCA)
- 커널 PCA
- 지역적인 선형 임베딩(LLE)
- t-SNE
-
이상치 탐지(outlier detection): 데이터셋에서 이상한 값을 자동 제거
-
특이치 탐지(novelty detection): 훈련 세트에 있는 것과 다른 샘플 탐지
-
연관 규칙 학습(association rule learning): 대량의 데이터에서 특성간의 관계 찾기
ex)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
-저차원 다양체 (low-dimensional manifold) -희소 트리 및 그래프(a sparse tree and graph)
-위의 것들로 인해 같은 데이터의 고유 패턴 발견.
4.강화학습(Reinforcement Learning)
:환경으로부터의 피드백-->행위자 행동 분석.최적화
-시행착오(Trial-and-error)
-지연 보상(delayed reward)
:지도학습과 다른 알고리즘으로 특정 보상을 최대화 하도록 학습.
<용어 정리>
-에이전트(Agent): 학습 주체 (혹은 actor, controller)
-환경(Environment): 에이전트에게 주어진 환경, 상황, 조건
-행동(Action): 환경으로부터 주어진 정보를 바탕으로 에이전트가 판단한 행동
-벌점(penalty): 부정적인 보상.
-보상(Reward): 행동에 대한 보상
-정책(policy): 가장 큰 보상을 얻기 위한 최상의 전략. 주어진 상황에서 에이전트의 행동 선택 및 정의
<대표 알고리즘 정리>
-Monte Carlo methods
-Q-Learning
-Policy Gradient methods
-알파고
특정 알고리즘을 사용하는 시점
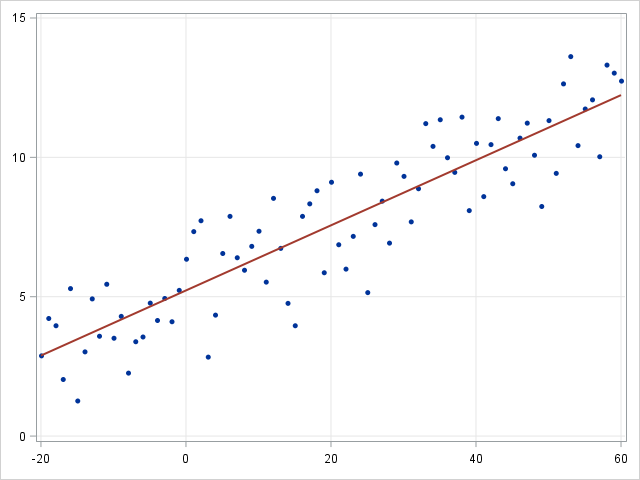
1.선형 회귀(Linear regression)와 로지스틱 회귀 https://blogs.sas.com/content/saskorea/files/2017/08/linearregression.png https://blogs.sas.com/content/saskorea/files/2017/08/logisticregresion.png
{kind=link}
{kind=link}
1-1.선형 회귀:연속적인 종속 변수y와 한 개 이상의 예측 변수인 x사이의 관계 모델링 접근법.(일차함수로 그려짐)
1-2 로지스틱 회귀: 종속 변수가 범주형이라면 로짓 연결 함수를 이용해 선형 회귀에서 변환된 것 시그모이드 함수--> 매개 변수값 극대화.
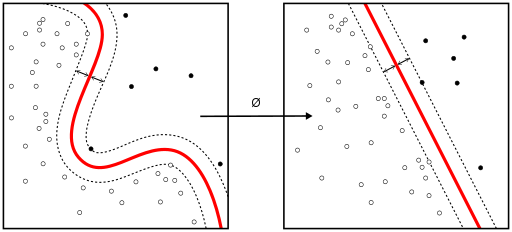
2.선형(Linear)SVM 및 커널(Kernel)SVM
2-0:서포트 벡터머신(SVM)학습 알고리즘은 초평면의 법선 벡터 와 편향값으로 표현되는 분류기 찾는다.
--> 경계를 가능한 최대 오차로 분리하여 최적화 문제로 변화.
2-1:커널 트릭(기법)은 분리 가능한 비선형 함수-->고차원의 분리 가능한 함수로 매핑.
https://blogs.sas.com/content/saskorea/files/2019/03/%EC%B9%98%ED%8A%B85.png
{kind=link}
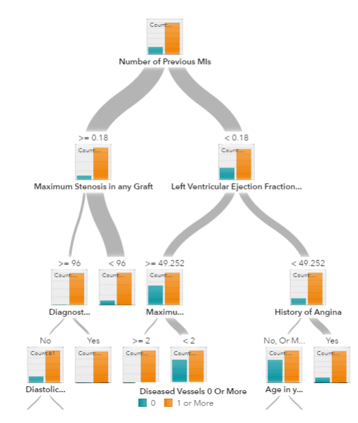
3.트리와 앙상블 트리(ensemble tree) https://blogs.sas.com/content/saskorea/files/2019/03/%EC%B9%98%ED%8A%B86.png
{kind=link}
-의사결정트리 기반 알고리즘 :의사결정 트리, 램덤 포레스트, 그래디언트 부스팅
:다양해 보이지만 동일 작업 수행 ->특정 공간을 거의 같은 레이블로 구별되어 분리
:이해와 구현은 쉬우나 데이터 overfit 가능성O[의사결정트리] ->해결
: 랜덤 포레스트와 그래디언트 부스팅
{kind=link}
:병렬 분산 처리 능력
:SVM
:비지도 사전학습 과 계층별 탐욕 학습
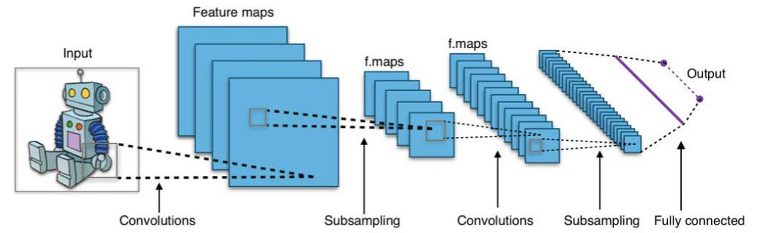
:GPU 와 MPP 위의 4가지 이유 덕분에 신경망->딥러닝 신경망으로 발전
:인간 개입이 줄고 원시 이미지나 음성 추출
:신경망 계층 -입력,출력
:학습 표본 정의하고 범주형 변수 일 때 분류문제 해결.
연속 변수일 회귀 작업 사용 입력계층=출력계층일 때 고유 특징 추출 은닉계층 수는 모델 복잡성과 모델링 수용력 결정
5.K-평균/K-모드(k-means/k-modes),가우시안 혼합모델(GMM; Gaussian mixture model)클러스터링
https://blogs.sas.com/content/saskorea/files/2019/03/%EC%B9%98%ED%8A%B89.png
{kind=link}
목표: n개의 관측 값을 n개의 그룹으로 나눈다.
K-평균:하드 할당(표본을 하나의 클러스터에만 결속)
GMM:소프트 할당(각 표본이 확률값을 가지고 하나에만 결속 X)
:두 알고리즘 모두 클러스터K의 수가 주어질 떄 빠름.
6.DBSCAN
:클러스터 k의 수가 주어지지 않을 때 밀도 확산 -->표본 연결하여 사용
https://blogs.sas.com/content/saskorea/files/2019/03/%EC%B9%98%ED%8A%B810.jpg
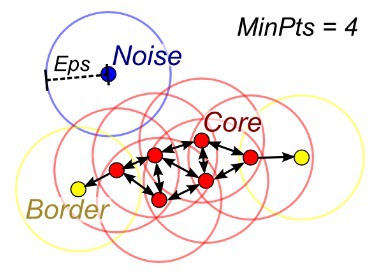{kind=link}
7.계층적 군집화(Hierarchical clustering)
https://blogs.sas.com/content/saskorea/files/2019/03/%EC%B9%98%ED%8A%B811.png
{kind=link}
계층적 분할은 덴드로그램을 이용하여 시각화.
각기 다른 K->클러스터 정제 OR 조대화
-->세분화-->입력과 분할 결과 확인(클러스터의 개수 필요 없음)
8.PCA, SVD, LDA
:일반적으로 직접 고차원 데이터가 입력이 되면 필요없는 값이나 중복값이 들어가므로 선호하지 않아.
:차원 축소를 한다
-주성분 분석(PCA)
:고차원 공간-> 저차원 공간 매핑
-->가능한 많은 정보 보존하는 비지도 클러스터링방식
-->데이터 분산-->하위 공간 찾고
하위공간은 공분산 매트릭스의 지배적인 고유벡터정의
-특이값 분해(SVD)
:PCA와 하는 일이 비슷하나 자연어처리(NLP)에서 잠재 의미 분석으로 알려진 주제 모델링 도구
-잠재 디리클레 할당(LDA)
:자연어 처리(NLP)로 주로 쓰이고 확률적 주제 모델로
GMM이랑 비슷한 방식이나 LDA는 이산데이터 모델링하고 연역적으로 분포가 되어 있어야 가능
머신러닝 알고리즘 BY 사이킷런
- 사이킷런: 파이썬으로 머신러닝 개발 시 사용되는 라이브러리 , 어떤 기준과 조건에 따라서 알고리즘 방식 선택
사이킷런의 알고리즘은 파이썬 클래스로 구현되어 있고,
데이터셋은 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 이용해
나타낼 수 있습니다
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
https://scikit-learn.org/stable/index.html
-의존성(Dependencies)
:사이킷런은 파이썬 기반 머신러닝 라이브러리로 파이썬과 라이브러리에 의존성을 갖는다.
Python (>= 3.6)
NumPy (>= 1.13.3)
SciPy (>= 0.19.1)
joblib (>= 0.11)
-fit() , predict() 메소드가 중요
-train_test_split() 함수로 훈련데이터와 테스트 데이터 랜덤하게 섞음
-수학관련 함수 갖고 있음
-Pipeline()으로 묶어 검증한다.
:데이터 가공(ETL) [transformer()이용] -> 모델 훈련 예측하는 과정(fit(),predict())
[사이킷런의 주요 모듈]
https://d3s0tskafalll9.cloudfront.net/media/images/Untitled_8_gdSwRxK.max-800x600.png
{kind=link}
1.데이터 표현법
https://scikit-learn.org/stable/modules/classes.html
https://d3s0tskafalll9.cloudfront.net/media/images/Untitled_sP0AtFE.max-800x600.png
{kind=link}
:훈련과 예측 등 머신러닝 모델을 다룰 때는 CoreAPI라고 불리는
fit(), transfomer(), predict()과 같은 함수들을 이용합니다.
-제공 데이터셋은
NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix
-표현 방식
https://d3s0tskafalll9.cloudfront.net/media/images/Untitled_1.max-800x600.png
{kind=link}
!!특성행렬 X의 n_samples와 타겟벡터 y의 n_samples는 동일해야 합니다
i)특성행렬(Feature Matrix)
-입력 데이터를 의미합니다.
-특성(feature): 데이터에서 수치 값, 이산 값, 불리언 값
으로 표현되는 개별 관측치를 의미합니다. 특성 행렬에서는 열에 해당하는 값입니다.
-표본(sample): 각 입력 데이터, 특성 행렬에서는 행에 해당하는 값입니다.
-n_samples: 행의 개수(표본의 개수)
-n_features: 열의 개수(특성의 개수)
-X: 통상 특성 행렬은 변수명 X로 표기합니다.
-[n_samples, n_features]은 [행, 열]형태의 2차원 배열 구조를 사용하며 이는 NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matrix를 사용하여 나타낼 수 있습니다.
ii)타겟벡터(Target Vector)
-입력 데이터의 라벨(정답) 을 의미합니다.
-목표(Target): 라벨, 타겟값, 목표값이라고도 부르며 특성 행렬(Feature Matrix)로부터 예측하고자 하는 것을 말합니다.
-n_samples: 벡터의 길이(라벨의 개수)
타겟 벡터에서 n_features는 없습니다.
-y: 통상 타겟 벡터는 변수명 y로 표기합니다.
-타겟 벡터는 보통 1차원 벡터로 나타내며,
이는 NumPy의 ndarray, Pandas의 Series를 사용하여 나타낼 수 있습니다.
(단, 타겟 벡터는 경우에 따라 1차원으로 나타내지 않을 수도 있습니다. )
2.회귀 모델 실습
-
from sklearn.linear_model import LinearRegression
-
fit(특성행렬, 타겟벡터) : 모델 훈련 시키는 메소드
-
fit(행렬 형태 입력 데이터, 1차원 벡터 형태의 정답(라벨))
-
입력 데이터를 행렬 형태 유지: reshape()이용한다.
ex)
X = x.reshape(100,1)
- 새로운 데이터 넣고 예측
x_new = np.linspace(-1, 11, 100) # 새로운 데이터 생성
X_new = x_new.reshape(100,1) # 행렬 형태로 변환
y_new = model.predict(X_new) # 예측
-회귀 모델 성능 평가( RMSE 성능)
from sklearn.metrics import mean_squared_error
error = np.sqrt(mean_squared_error(y,y_new))
print(error)
3.datasets모듈(sklearn.datasets)
https://scikit-learn.org/stable/datasets
i)dataset loaders - Toydataset제공
<Toydataset제공>
-datasets.load_boston(): 회귀 문제, 미국 보스턴 집값 예측
-datasets.load_breast_cancer(): 분류 문제, 유방암 판별
-datasets.load_digits(): 분류 문제, 0 ~ 9 숫자 분류
-datasets.load_iris(): 분류 문제, iris 품종 분류
-datasets.load_wine(): 분류 문제, 와인 분류
ii)dataset fetchers - Real World dataset제공
3-1.data
:data는 키값으로 특성행렬(2차원)이다. 파이썬의 딕셔너리와 유사함.
:data.data : 키에 접근하기
:data.data.shape: 모양 확인
:data.data.ndim : 차원 확인
3-2.target
:target는 타겟 벡터로 1차원이다.
:data.target.shape - 타겟 벡터 길이 = 특성 행렬 데이터 개수
3-3.feature_names
:data.feature_names - 특성들의 이름 알기
data.target_names - feature_names 의 갯수 = 특성행렬의 열 숫자
3-4.target_names
:분류하고자 하는 대상
3-5. DESCR
:describe의 약자로 데이터에 대한 설명을 함
print(data.DESCR)
4.분류 문제 실습
4-1. DataFrame으로 나타내기 (EDA할 때 편함)
#!pip install pandas
import pandas as pd
pd.DataFrame(data.data, columns=data.feature_names)
4-2. 머신러닝
: 특성 행렬 - 변수명: X , 타겟 벡터 :y
ex) RandomForestClassifier
i)모델 부르기
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
ii) 모델 훈련
model.fit(X, y)
iii) 모델 예측
y_pred = model.predict(X)
iv)성능 평가( 분류문제 이기에 classification_report 와 accuracy_score를 이용)
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#타겟 벡터 즉 라벨인 변수명 y와 예측값 y_pred을 각각 인자로 넣습니다.
print(classification_report(y, y_pred))
#정확도를 출력합니다.
print("accuracy = ", accuracy_score(y, y_pred))
v)정확도가 1이 나온다
그 이유는 훈련데이터와 테스트 데이터를 분리하지 않았기 때문이다
5.Estimator
:머신러닝 모델의 파라미터 추정하는 객체
: 모든 머신러닝 모델은 Estimator라는 파이썬 클래스로 구현.
:예시-fit(),predict()메소드
:LinearRegression(),RandomForestClassifier()모듈
:비지도학습, 지도학습 관계없이 학습과 예측한다.
6.훈련 데이터와 테스트 데이터 분리하기
https://d3s0tskafalll9.cloudfront.net/media/images/Untitled_6_uWp8wos.max-800x600.png
{kind=link}
-훈련 데이터와 테스트 데이터비율은 8:2
-훈련 데이터 = 테스트 데이터 : 정확성100%(의미X)
코드 실습
-
데이터 가져오기
from sklearn.datasets import load_wine
data = load_wine()
print(data.data.shape)
print(data.target.shape) -
훈련데이터 : 테스트 데이터 = 8:2
X_train = data.data[:142]
X_test = data.data[142:]
print(X_train.shape, X_test.shape)
y_train = data.target[:142]
y_test = data.target[142:]
print(y_train.shape, y_test.shape)
- 훈련과 예측.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
- 정확도 평가
from sklearn.metrics import accuracy_score
print("정답률=", accuracy_score(y_test, y_pred))
- train_test_split() 사용해서 분리
from sklearn.model_selection import train_test_split
result = train_test_split(X, y, test_size=0.2, random_state=42)
훈련 데이터용 특성 행렬, 테스트 데이터용 특성 행렬, 훈련 데이터용 타겟 벡터, 테스트 데이터용 타겟 벡터 나뉘게 됨
- unpacking 쓰기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- 코드 합치기
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
#데이터셋 로드하기
data = load_wine()
#훈련용 데이터셋 나누기
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=11)
#훈련하기
model = RandomForestClassifier()
model.fit(X_train, y_train)
#예측하기
y_pred = model.predict(X_test)
#정답률 출력하기
print("정답률=", accuracy_score(y_test, y_pred))
