빅데이터
역사
-
2004년, MapReduce on Simplified Data Processing on Large Clusters
- GFS와 같은 분산 처리 파일 시스템 모델
- 맵 함수와 리듀스함수의 2가지 작업을 나누어 처리
- 맵: 키-값 쌍을 처리해서 중간의 생성
- 리듀스: 동일 키와 연관된 모든 중간 값들 병합
-
2004~2005년, NDFS Project
- 검색엔지의 효과적인 분산처리 위한 프로젝트
-
2006~2007년, Apach Hado
- HDFS 와 MapReduce 두 기술에 집중
-
2007~2008년, 폭발적 성장
- 하둡 사용으로 인해 빨라짐
-
2009~2013년, Apache Spark
- 메모리 기반의 데이터 처리 방법
- RDD프로그램 발표
-
2014~2020년, Databricks 와 Apach Spark
- 데이터 분석 및 클라우드 환경 제공
Hadoop Ecosystem
- 역사: 맵리듀스 HDFS + 컴포넌트 = Large SW
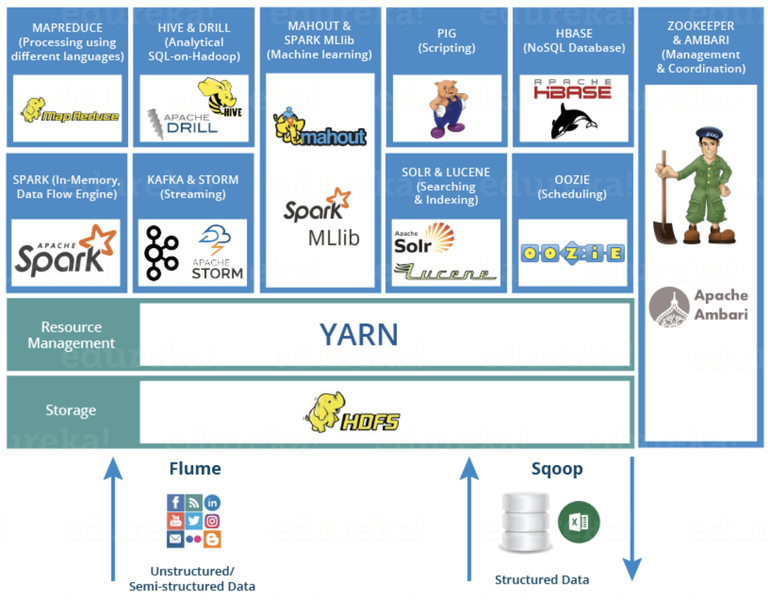
- 컴포넌트
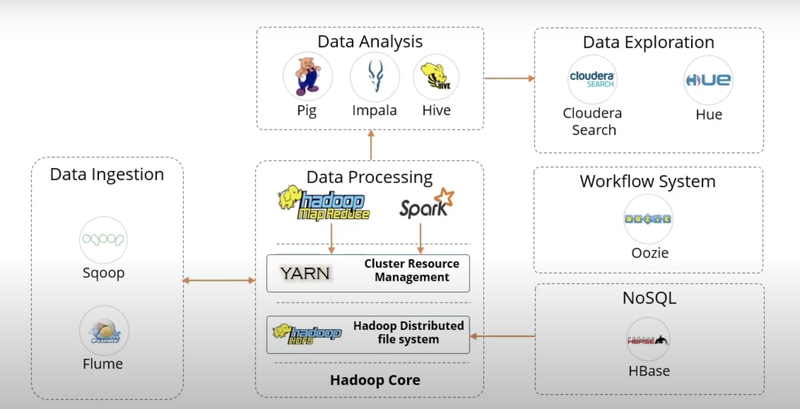
데이터 수집(Data ingestion)
-
스쿱(Squoop): RDBMS(오라클,Mysql)~하둡 (데이터 이동)
-
플럼(Flume): 분산 환경에서 데이터 수집하여 병합한 후에 전송
데이터 처리(Data Processing)
-
HDFS: 분산 처리 파일 시스템
-
MapReduce: 자바 기반의 프로그래밍 모델
-
Yarn: 하둡 클러스터 자원 관리
-
Spark: In-memory기반의 클러스터링 컴퓨터 데이터 처리
데이터 분석(Data Analysis)
-
Pig: 어려운 데이터 처리 과정으로 filter, join,query등 실행
-
Impala: 고성능의 SQL엔진
-
Hive: sql기능 제공
데이터 검색(Data Exploration)
-
Cloudera Search: real-time을 통해 데이터 검색
-
Hue: 웹 인터페이스 제공
기타
-
우지(Oozie): 워크플로우 관리 및 Job 스케줄러
-
HBase: NoSQL기반으로 HDFS로 인해 처리된 데이터 저장
-
Zeppelin : 데이터 시각화
-
SparkMLlib: 머신러닝 관련 라이브러리
Spark Ecosystem
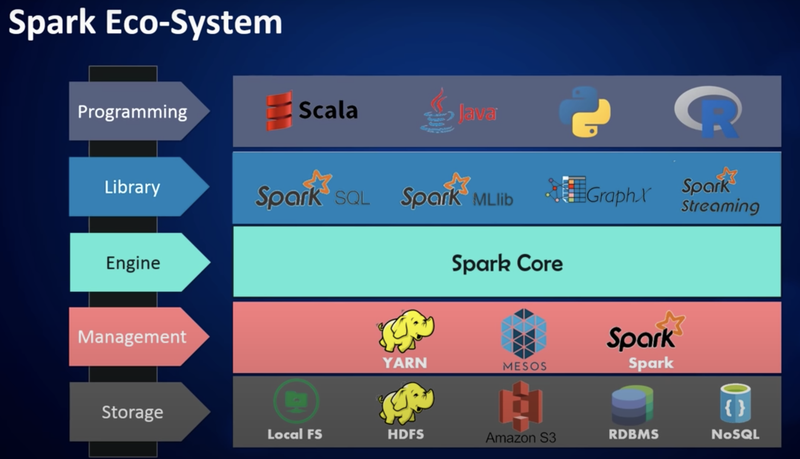
-프로그래밍언어: Java,Python, SQL, Scala,R
-
자원 관리: 하둡의 Yarn, Mesos사용 혹은 자체 기능 사용
-
데이터 저장: Local FS, HDFS이용, AWS의 S3인스턴스 이용등을 이용하여 유연한 확장성 강조
-
주 언어: Scala(Spark)
-
환경: 클러스터
라이브러리
-
Spark SQL: SQL 관련 작업
-
Streaming: Streaming 데이터 처리
-
MLlib: ML라이브러리
-
GraphX: Graph Processing
RDD(데이터처리)
- 배경: 하둡을 이용할 시, 입/출력 바운드로 인한 병목현상이 일어나 시간이 오래 걸린다.그로 인해, 스파크가 하드 디스크에서 파일을 가져온 후 연산단계에서 데이터 메모리 저장하면 속도가 빨라진다.
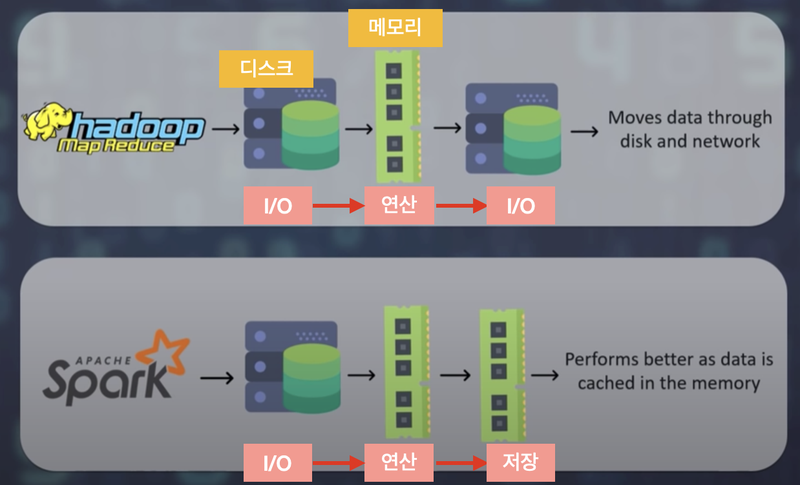
- 정의:클러스터의 여러 메모리에 분산하여 저장하는 데이터의 집합
-
특징
- In-Memory
- Fault Tolerance
- Immutable(Read-Only): 결함 시, 메모리를 읽기 모드로 전환
- Partiton
생성(Creation)
- parallelize()함수: 내부에서 만들어진 데이터 집합 병렬화
from pyspark import SparkConf, SparkContext
sc = SparkContext()
rdd = sc.parallelize([1,2,3])
rdd- .textFile()함수: 외부의 파일 로드
동작(Operation)
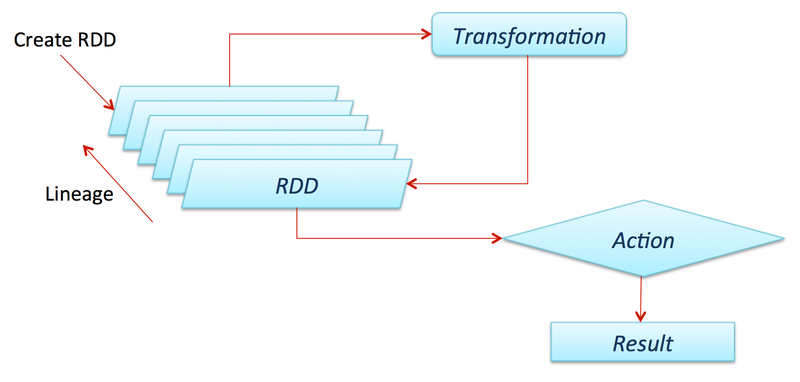
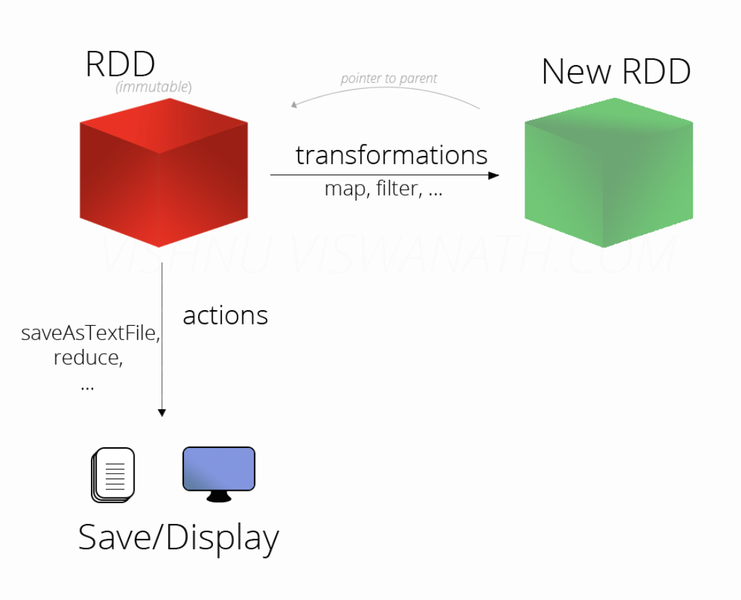
- Transformations : 변향 방법을 알려줘서 New ADD 만든다
- Actions: 실제 연산(결과값 생성 및 저장), Transformations연산 지시
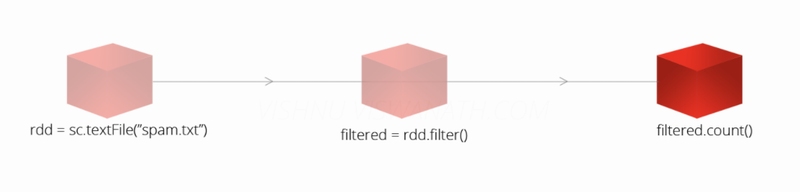
- sc.textFile()통해 RDD 생성(그저 계보만 만든다, 객체 함수 생성 X)
import os
file_path = os.getenv('HOME')+'/aiffel/bigdata_ecosystem/test.txt'
with open(file_path, 'w') as f:
for i in range(10):
f.write(str(i)+'\n')
print('OK')
rdd2 = sc.textFile(file_path)
print(rdd2)
print(type(rdd2))
- take(개수 입력): RDD원소 반환
rdd.take(3) 
- counts()실행: RDD생성 시점
- Lazy evaluation: 계산 늦추다가 정말 필요 시기에 계산 수행
Transformations
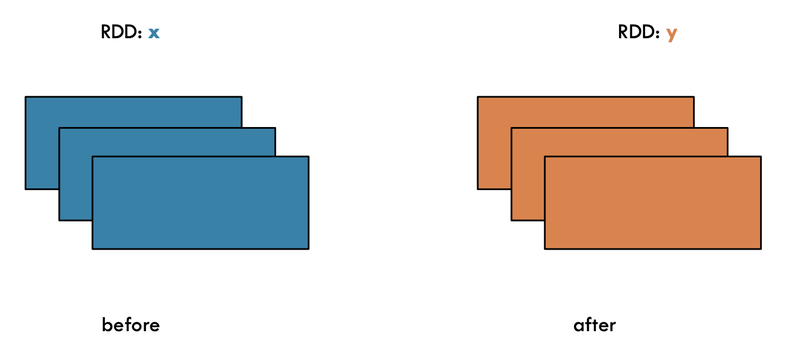
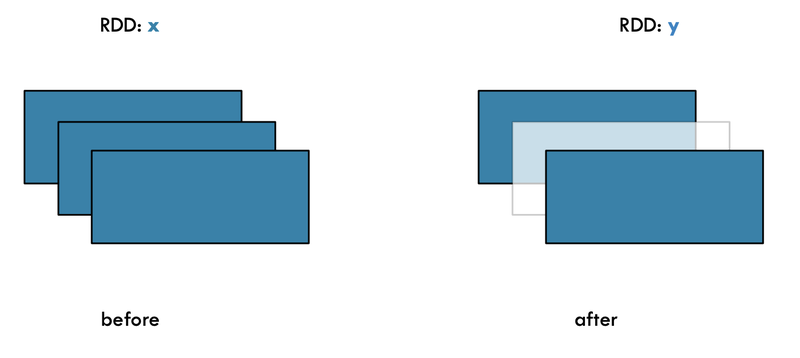
- map() :x 와 y의 원소개수가 같다
x = sc.parallelize(["b", "a", "c", "d"])
y = x.map(lambda z: (z, 1))
print(x.collect()) #collect()는 actions입니다.
print(y.collect())- filter(): 조건을 만족하는 값만 반환하므로 x와y의 원소 개수가 같지 않다
text = sc.parallelize(['a', 'b', 'c', 'd'])
capital = text.map(lambda x: x.upper())
A = capital.filter(lambda x: 'A' in x)
print(text.collect()) #['a','b','c','d']
print(A.collect()) #['A']
- flatmap(): map연산 후 원소의 개수 증가. 동일하게 증가 안함
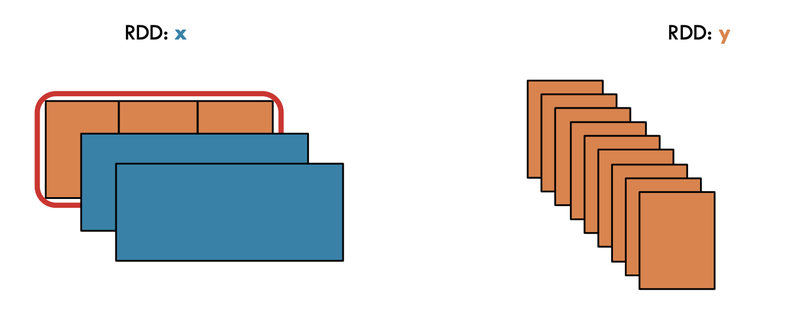
wordsDataset = sc.parallelize(["Spark is funny", "It is beautiful", "And also It is implemented by python"])
result = wordsDataset.flatMap(lambda x: x.split()).filter(lambda x: x != " ").map(lambda x: x.lower())
# 공백은 제거합니다.
# 단어를 공백기준으로 split 합니다.
result.collect()Actions
- collect() :RDD 의 모든 값을 리턴하므로 주의깊게 쓰기
nums = sc.parallelize(list(range(10)))
nums.collect()- take(): RDD에서 앞쪽부터 n개의 데이터를 list형식으로 리턴
nums.take(3)- count(): RDD에 포함된 데이터 개수 리턴
nums.count()- reduce(): RDD로 메모리 상에 존재하기 때문에 MapReduce 실행 가능
nums.reduce(lambda x, y: x + y)- saveAsTextFile : RDD데이터를 파일로 저장한다.
file_path = os.getenv('HOME')+'/aiffel/bigdata_ecosystem/file.txt'
nums.saveAsTextFile(file_path)
!ls -l ~/aiffel/bigdata_ecosystem전체 수행 코드
# RDD 생성
rdd = sc.parallelize(range(1,100))
# RDD Transformation
rdd2 = rdd.map(lambda x: 0.5*x - 10).filter(lambda x: x > 0)
# RDD Action
rdd2.reduce(lambda x, y: x + y)SparkContext
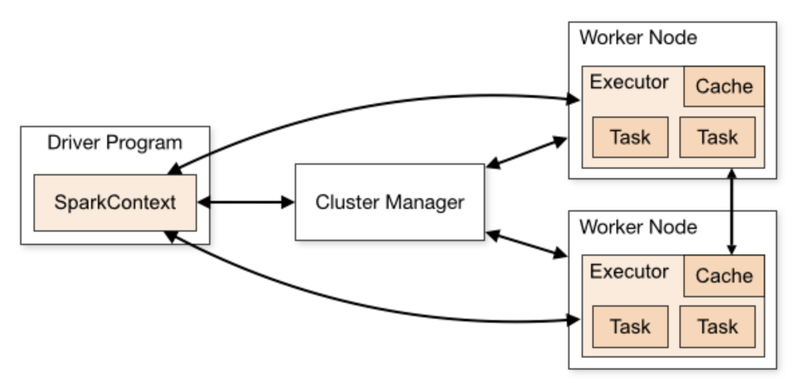
-
driver 프로그램 구동 시, 생성되는 특수 객체
-
1 by 1. 사용 후 종료해야함
-
문법: pyspark.SparkContext()
-
스파크 기능의 기본 엔트리 포인트
-
RDD 만들어서 브로드캐스트 사용
-
새로운 것 만들기 전에 활성 중지해야함
CODE
CODE1:Simple
from pyspark import SparkConf, SparkContext
sc = SparkContext()
sc
type(sc)
sc.stop()CODE2 : With Configuration
sc = SparkContext(master='local', appName='PySpark Basic')
sc
sc.getConf().getAll()
sc.stop()
CODE3 : With Spark Conf()
conf = SparkConf().setAppName('PySpark Basic').setMaster('local')# 어플리케이션의 이름과 Master의 URL설정
sc = SparkContext(conf=conf)
sc
sc.stop()