최적화하기 전에 프로파일링을 하라
빠를 것 같은데 느리고 느릴 것 같은데 빠른 언어 기능들이 있다. 이러한 것을 직관보단 직접 성능을 측정하는 것을 추천하고 이를 프로파일러라고 한다.
암달의 법칙: 프로파일러가 있으므로 프로그램에서 가장 문제가 되는 부분을 집중적으로 최적화하고 프로그램에서 속도에 영향을 미치지 않은 부분은 무시할 수 있다.
Code
#삽입 정렬을 사용하여 데이터 리스트 정렬
#핵심 메커니즘: 데이터 조각을 삽입할 위츠를 찾는 함수다.
def insertion_sort(data):
result = []
for value in data:
insert_value(result, value)
return result
#입력 배열을 선형으로 검색하는 비효율적인 함수
def insert_value(array, value):
for i, existing in enumerate(array):
if existing > value:
array.insert(i, value)
return
array.append(value)
#먼저 난수 데이터 집합을 만들고 프로파일러에 넘길 test 함수 정의
from random import randint
max_size = 10**4
data = [randint(0, max_size) for _ in range(max_size)]
test = lambda: insertion_sort(data)내장 프로파일러인 파이썬 파일러와 C확장 모듈 cProfile 내장 모듈 중에서 후자가 더 좋다.
from cProfile import Profile
profiler = Profile()
profiler.runcall(test)테스트 함수가 실행되면 pstats 내장 모듈에 들어있는 Stats 클래스를 사용하여 성능 통계를 추출할 수 있다.
Stats에 들어 있는 여러 메서드를 사용해 관심 대상 프로파일 정보를 선택하여 정렬하는 방법을 조절해서 관심있는 항목만 표시
from pstats import Stats
stats = Stats(profiler)
stats.strip_dirs()
stats.sort_stats('cumulative') #누적 통계
stats.print_stats()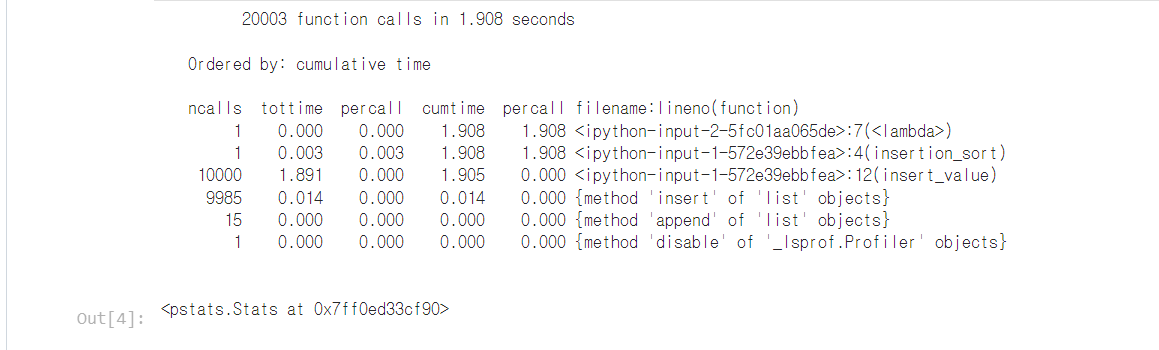
컬럼에 대한 설명
-
ncalls: 프로파일링 기간 동안 함수가 몇 번 호출되었는지 보여준다.
-
tottime: 프로파일링 기간 동안 대상 함수를 실행하는데 걸린 시간의 합계로 다른 함수를 호출하여 실행되는 시간은 제외된다.
-
tottime percall: 프로파일링 기간 동안 함수가 호출될 때마다 걸린 시간의 평균을 보여주고 대상 함수가 다른 함수를 호출할 경우 다른 함수 실행을 위한 걸린 시간은 제외되고, 이 값은 tottime을 ncalls로 나눈 값과 같다.
-
cumtime: 함수가 실행할 때 걸린 누적 시간을 보여주는 것으로 대상 함수가 호출한 다른 함수를 실행하는데 걸린 시간이 모두 포함된다.
-
cumtime percall: 프로파일링 기간 동안 함수가 호출될 때마다 걸린 누적 시간의 평균을 보여주는 것으로 대상 함수가 호출한 다른 함수를 실행하는데 걸린 시간이 모두 포함이 되므로 cumtime을 ncalls로 나눈 값과 같다.
from bisect import bisect_left
def insert_value(array,value):
i = bisect_left(array, value)
array.insert(i, value)Summary
-
파이썬 프로그램을 느리게 하는 원인이 불분명한 경우가 많으므로 프로그램을 최적화하기 전에 프로파일링하는 것이 중요하다.
-
profile 모듈 대신 cProfile 모듈을 사용하고, cProfile이 더 정확한 프로파일링 정보를 제공한다.
-
함수 호출 트리를 독립적으로 프로파일링하고 싶다면 Profile 객체의 runcall 메서드를 사용하기만 하면 된다.
-
Stats 객체를 사용하면 프로파일링 정보 중에서 프로그램 성능을 이해하기 위해 살펴봐야할 부분만 선택해서 출력할 수 있다.
