학습목표
-
scikit-learn 예제 데이터셋 종류
-
scikit-learn 모델 학습과 예측
-
모델 성능 평가 지표
-
용어 정리
사이킷런(scikit-learn)
정의:머신러닝에서 가장많이 쓰이는 라이브러리.
제공예제 테이터 셋:
-Toy datasets: boston, iris, diabetes, digits, linnerud, wine, breast cancer
-Real world datasets: olivetti faces, 20newsgroups, covtype, california housing
머신러닝 모델
출력: 라벨(label), 타겟(target)
문제지(=feature):변수 이름은 통상적으로x이고, 입력되는 데이터
정답지(=label,target):변수 이름은 y이고,맞추어야 하는 데이터
test_size:전체의 몇 %를 테스트 데이터로 사용
random_state: train데이터와 test데이터 분리하는데 적용되는 랜덤성결정
랜덤 조절 값: random_state 또는 random_speed. 이 두 값이 같다면 항상 같은 랜덤 결과를 나타냄
학습:
-종류: 지도학습(정답있는 거 학습)
+)분류(Classification):
데이터->카테고리별 분류
ex)Decision Tree(스무고개 느낌)
-순도 증가 혹은 불확실성 감소 방향으로 학습 진행
-재귀적 분기: 입력 변수 영역 두 개로 구분
-가지치기: 구분된 영역 통합
-from sklearn.tree import DecisionTreeClassifier
+)희귀(Regression)
: 데이터 -> 특정 필드의 수치 맞추기
:비지도학습(정답 없는 거 학습)
-학습 과정
i) 데이터 셋 나누기(training dataset / test dataset)
-train_test_split함수 이용
n_test_split
ii)fit메서드이용
decision_tree.fit(X_train, y_train)
-예측 과정 (by test)
i)학습이 완료된 decision_tree 모델 + predict()메서드 이용
y_pred = decision_tree.predict(X_test)
y_pred
ii) 예측한 결과에 대한 수치화
-sklearn.metrics패키지 이용
from skelarn.metrics import accuracy_score
-모델 변경 가능한 파트
i)RandomForest-Ensemble기법
from sklearn.ensemble import RandomForestClassifier
ii)SVM
from sklearn import svm
iii)SGDClassifier
from sklearn.linear_model import SGDClassifier
iv)Logistic Regression
from sklearn.linear_model import LogisticRegression
모델 성능 평가 지표
-정확도(accuracy)
= 예측 정답인 데이터 / 예측 전체 데이터
+맞은 데이터만 신경쓰는 척도.
-오차행렬(매우 어려움 주의)
+)의미있는 정답 그리고 유의미한 오답을 놓치지 않는다.
+)수학에서 조건부확률 원리와 같다
+)정밀도(Precision): 분모 FP가 낮을 수로 커짐.
+)재현율(Recall,Sensitivity) :분모 FN이 낮을수록 커짐
+)F1스코어(f1 score)
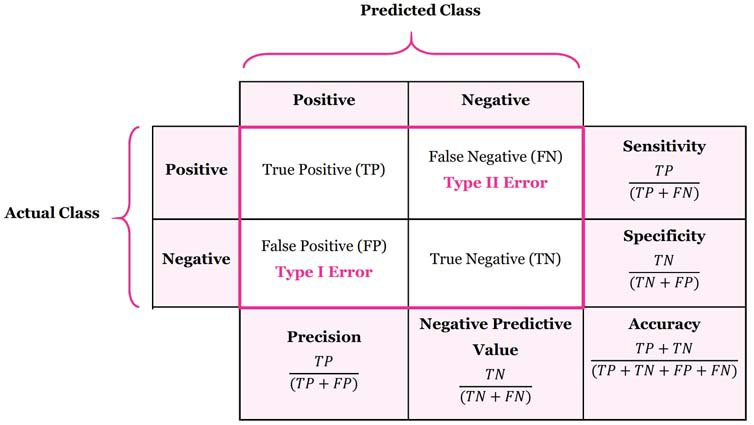

+)이미지 분석
-TP는 높고 FP, FN이 낮을 수록 좋은 예측이므로
Precision 과 Recall값이 클수록 좋다
+) 모델이 예측했던 결과 불러오기
from sklearn.metrics import confusion_matrix
+) 지표를 한 번에 확인 가능
from sklearn.metrics import classification_report
용어 정리
pip install scikit-learn: scikit-learn 설치 명령어
pip install matplotlib: matplotlib 설치 명령어
dir()-객체가 어떤 변수와 메서드 있는지 나열
keys()-어떤 정보가 담겼는지 알려주는 메서드
shape-배열의 형상정보 출력
DESCR-데이터셋의 설명
filename-데이터셋 파일이 저장된 경로
pandas(=pd)-표 형태로 이뤄진 2차원 배열 데이터
fit: 이 메서드는 training dataset에 맞게 모델을 맞춘다 for 학습.
matplotlib:이미지 보기 위한 라이브러리
프로젝트 하면서 의문점
load_digits
정규화 실행 정확성 > 정규화 하지 않은 것의 실행 정확성
i) Recall 과 Precision 값의 감소(오차행렬)
ii) Random_state통일 값
iii)max_iter 값
iv) shuffle
이 네가지 차이가 정확성의 차이를 일으킵니다.
