AI 모델 경량화 툴 적용 기법 조사 및 On-device Object Detector SOTA Model 비교
Machine Learning/Deep Learning
<목차>
1. TensorRT 적용 경량화 기법
2. Pytorch 모델 경량화 툴
3. Knowledge Distillation 추가 조사
4. Edge 컴퓨팅 환경을 위한 AI 모델 최적화 및 경량화 기술개발최종보고서
1. TensorRT 적용 경량화 기법
1.1 TensorRT에서 수행하는 최적화 6가지
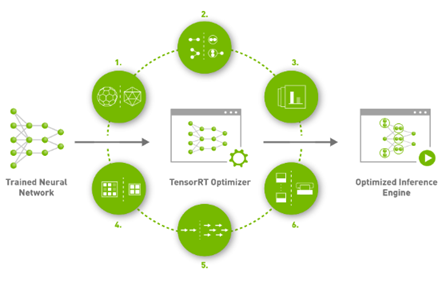
1) Reduced Precision
딥러닝 네트워크의 정확도를 유지하면서 FP32 연산을 FP16 (AMP) 혹은 INT8 (Quantization) 연산으로 바꿔 성능 향상을 달성함. 낮은 정확도를 가지는 데이터 타입 연산은 더 적은 메모리 사용량, 더 빠른 메모리 접근, 더 빠른 계산 (Tensor core와 같은 specialized hardware unit을 사용할 수도 있음) 을 가능하게 함.
2) Layer and Tensor Fusion (=Operator fusion)
몇가지 Layer들을 하나의 layer로 합침으로써 data reuse 를 늘려 DRAM or off-chip memory 접근을 줄여 성능 향상을 달성
3) Kernel Auto-Tuning
딥러닝 네트워크가 배포되는 시스템에 맞게 최적화된 GPU kernel tuning을 지원함. GPU는 어디에 사용되는지 (데이터센터용 100시리즈, 임베디드용 jetson, 자율주행용 DRIVE), 어떤 세대인지 (Volta, Ampere, Hopper), 어떤 용도로 사용되는지 (렌더링, HPC, 게임) 등 여러 조건에 따라 달라지는 각 아키텍처마다 최적 kernel parameters (thread block configuration, data layout, shared memory 등등)를 자동으로 선택
4) Dynamic Tensor Memory
GPU 메모리 사용량 최적화 및 재활용, TensorRT는 model 분석을 통해 네트워크에 사용되는 모든 tensor들의 lifetime을 알 수 있기에, 최적화된 메모리 영역 크기 파악 및 사용 스케줄링이 가능.
5) Multi-Stream Execution
여러 input에 대한 병렬처리가 가능
6) Time Fusion
Recurrent neural networks에 대한 최적화
💡 TensorRT에서 사용하는 최적화 기법을 보았을 때 경량화 기법으로 Quantization이 사용됨을 알 수 있었음
1.2 TensorRT Quantization 적용 개요
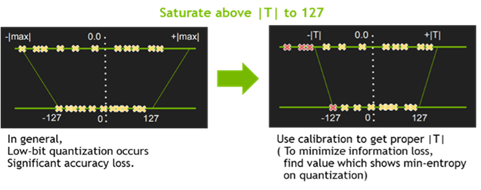
- Quantization & Precision Calibration
○ Quantization 기법들 중, TensorRT는 Symmetric Linear Quantization을 사용하고 있으며, 이를 통하여 Deep Learning Framework의 일반적인 FP32의 data를 FP16 및 INT8의 data type으로 precision을 낮춤
○ 일반적으로 FP16으로의 precision down-scale은 Network의 accuracy drop에 큰 영향을 주지는 않지만, INT8로의 down-scale은 accuracy drop을 보이는 몇 부류의 Network이 존재
○ 추가적인 calibration 방법들로 TensorRT에서는EntronpyCalibrator, EntropyCalibrator2, MinMaxCalibrator를 지원하여 quantization시 weight 및 intermediate tensor들의 정보의 손실을 최소화
1.3 Convert Onnx to TensorRT
○ TensorRT에서 지원하는 프레임워크는 pytorch, tensorflow, keras, onnx 등이 있으며, 여러 프레임워크에서 직접적인 TensorRT 변환을 지원하고 있지만 다소 제약이 있음
○ 대신 onnx로의 변환은 대부분의 프레임워크에서 더 나은 지원을 해주고 있으며 onnx로 변환한 모델은 다시 TensorRT로 변환이 가능하기 때문에 pytorch을 onnx로 변환하고 이를 TensorRT로 추론하는 방법이 가능
○ Torch-TensorRT는 NVIDIA GPU에서 TensorRT의 추론 최적화를 활용하는 PyTorch용 통합 컴파일러
또한 코드 한 줄만으로 NVIDIA GPU에서 성능을 최대 6배 향상해주는 간단한 API를 제공
1.4 기타 Tensor 모델 경량화 툴
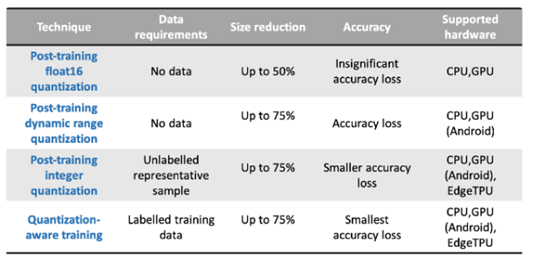
○ Tensorflow Lite - 텐서플로우 라이트, 텐서플로우의 경량화 버전으로, 텐서플로우 라이트 포맷 형태로 변환을 거치면, 모바일과 같은 임베디드 시스템에서도 추론(Inference)이 가능
*TF Lite에서는 아래와 같은 양자화 방법론을 사용
2. Pytorch 모델 경량화 툴
2.1 TorchScript & Pytorch JIT
○ PyTorch는 python과 비슷하기 때문에 tensorflow에 비해 모델을 서빙하기에 부족
○ PyTorch 1.0.0 업데이트에서 공개된 JIT 컴파일 지원은 PyTorch 모델 서빙에 새로운 해법 제시 - 이를 사용하면 모델을 최적화하여 다양한 환경에서 serving 하는 것이 가능
2.2 NVIDIA APEX
○ A Pytorch Extension의 약자로 pytorch에서 쉽게 분산학습과 mixed precision을 사용할수 있게해주는 Nvidia의 툴
○ APEX 안에 Amp(Automatic Mixed Precision)을 사용해 배치 사이즈를 늘리고 학습시간을 단축
*AMP (Automatic Mixed Precision)
AMP는 APEX에서 단 3줄만으로 mixed precision으로 학습할 수 있게 만들어주는 도구로 mixed precision 학습을 통해 배치 사이즈 증가, 학습시간을 단축, 성능 증가의 장점을 얻을 수 있음
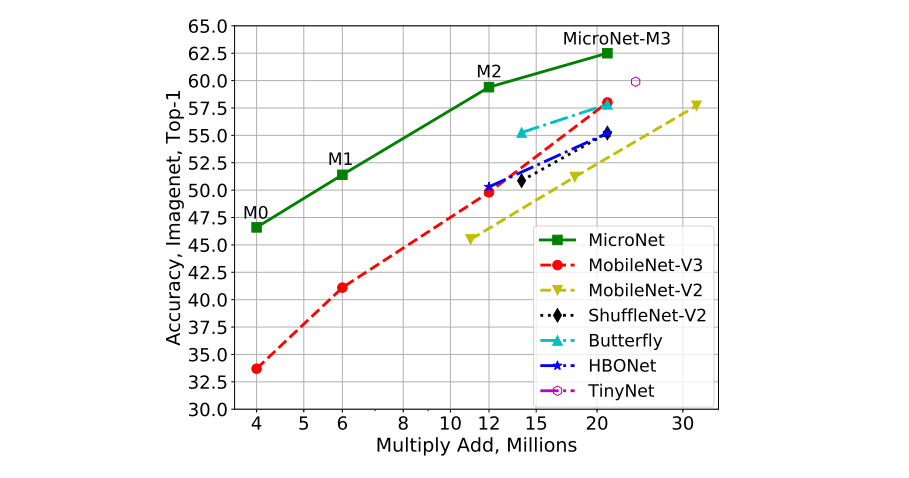
3. 온디바이스 객체 검출 SOTA Model 비교 - MobileNetv3, ShuffleNet, MicroNet
3.1 MicroNet
(ICCV 2021, MicroNet: Improving Image Recognition with Extremely Low FLOPs)
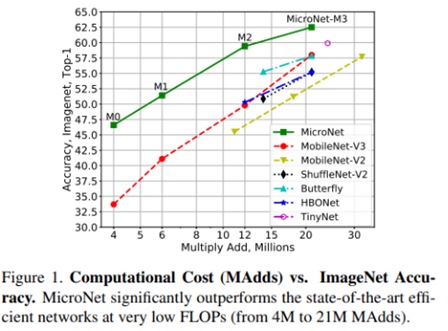
○ Pointwise와 Depthwise Convolution에 대해 저차원으로 Micro-Factorized Convolution을 적용하여 Input/Output Connectivity와 Channels 사이의 균형을 제공
○ Pointwise Convolution에 대해 Group-Adaptive Convolution 적용하고, Depthwise Convolution에 대해 k x k (kernel)에 대해 1 x k or k x 1 적용
○ MicroNet은 MobileNet과 ShuffleNet에 대해 Convolution과 Activation이 다름
*Pointwise Convolution에 대해 Group-Adaptive Convolution을 수행, 그리고 Depthwise Convolution 적용 후 Channel Connectivity 고려한 Activation 적용
3.2 MobileNetV3: Searching for MobileNetV3 (Image Classification)
(ICCV 2019, Searching for MobileNetV3)
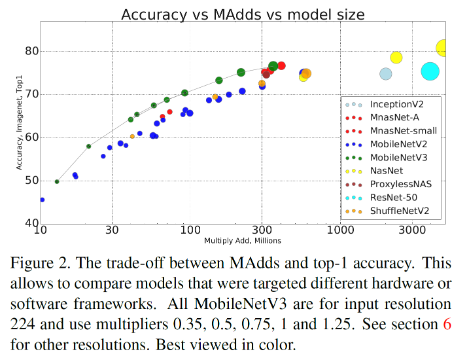
💡 MobileNetv3과 ShuffleNetv2의 연산량과 정확도에서 MobileNetv3이 같은 연산량에서 ShuffleNetv2보다 높은 정확도를 보임
3.3 ShuffleNet V2
(ECCV 2018, ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design)
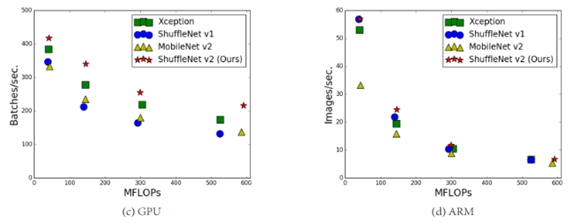
<GPU와 ARM 두 가지 platform에서 진행된 실험의 연산량지표(아래)>
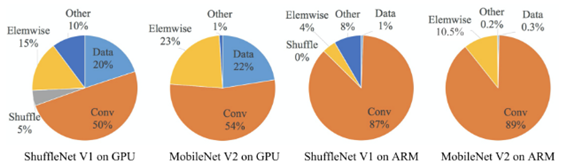
<ShuffleNet과 MobileNet의 연산량을 나타낸 표(아래)>
4. Edge 컴퓨팅 환경을 위한 AI 모델 최적화 및 경량화 기술개발최종보고서(참고용)
○ 객체 검출 경량화 기술 개발
-
Yolov5 code를 기반으로 학습기 개선
-
Knowledge distillation 적용
-
“Object detection at 200 Frames Per Second” 논문 적용
○ 객체 검출 경량 네트워크 개발
-
Yolov5x 네트워크 모델 기반으로 경량 네트워크 개발
-
C3 모듈을 개선하였음. BottleneckCSPF 와 유사한 구조임
<개선된 C3 구조(아래)>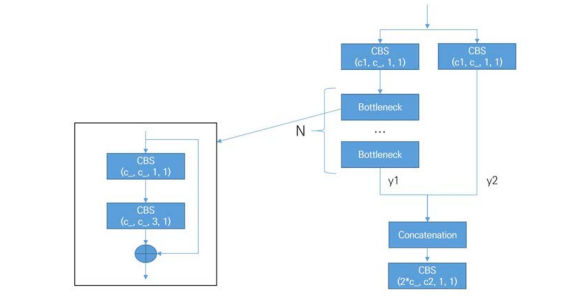
○ 임베디드 디바이스 기반 객체 검출 기술 개발
-
NVIDIA GPU 기반 딥러닝 고속화 기술인 TensorRT를 기반으로 하여 객체 탐지 기능을 구현
-
임베디드 디바이스로는 NVIDIA Jetson Xavier NX 사용
-
객체 탐지 네트워크 모델의 입력 이미지에 대한 전처리 기능을 CUDA로 구현하여 GPU 자원을 최대한 활용
-
다수의 프레임에 대해 동시에 추론할 수 있도록 Batch 단위의 추론 기능 구현 - TensorRT 기반의 객체 탐지 기술과 Torch 기반의 객체 탐지 기술 간의 성능 비교
-
성능 비교 결과, 추론 속도 측면에서는 TensorRT 기반 기술이 더 좋으나 mAP 측면에서 Torch 기반 기술이 더 좋은 것으로 확인됨
-
Pruning과 Knowledge distillation을 이용한 모델 경량화 수행
참고문헌 및 출처
https://jackyoon5737.tistory.com/250
MicroNet: Improving Image Recognition with Extremely Low FLOPs(2021)
MobileNetV3: Searching for MobileNetV3 (Image Classification)(2019)
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design(2018)

이해가 쏙쏙 되네요 ^~^
좋은 글 잘 보고 갑니다.