본 글에서는 CVPR에서 22년도에 발표된 MetaFormer is Actually What You Need for Vision, Yu et al.에 대해 간단하게 정리하겠습니다.
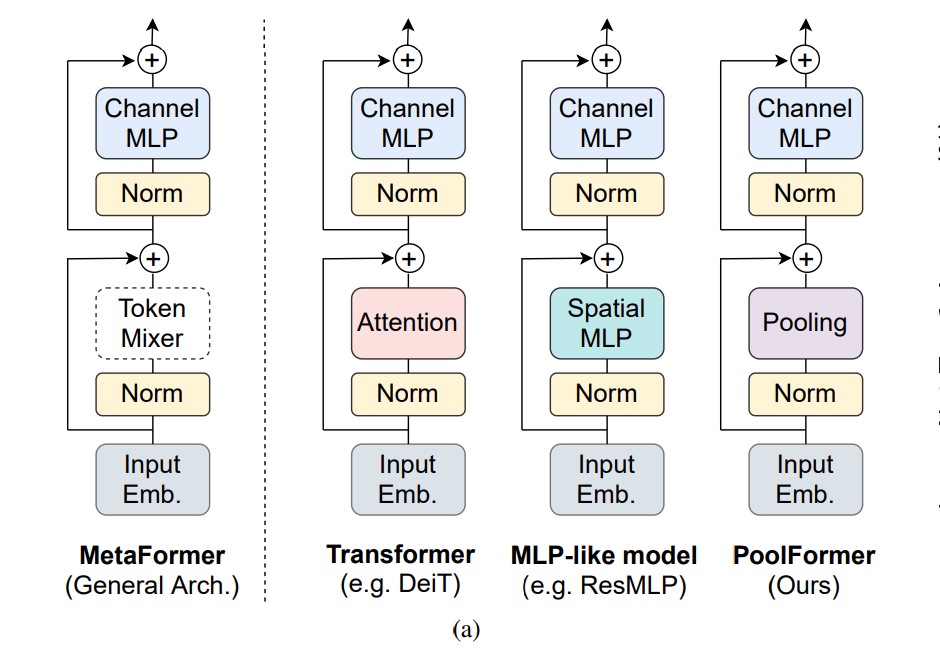
Generalized Transformer Achitecture
논문에서는 일반화된 트랜스포머 아키텍처를 제안합니다.
여기서 기존 트랜스포머 구조에서 Self-Attention이 왔던 부분을 Token Mixer라고 하고, Self-Attention을 제외한 나머지부분을 MetaFormer라고 했을 때, attention이 아니더라도Token Mixer 자리에 어떤 것이 오든지 MetaFormer 구조만 갖추고 있으면 CV task들에서 잘 작동한다는 것입니다.
Motivation
이러한 구조를 발견하게 된 배경을 보면,
ViT 모델들이 여러가지 구조로 다양화되고 있는데,저자들은 Token Mixer자리에 Self Attention이 아니더라도 MLP, 심지어는 옛날 연산 방식인 Fourier transform이 오더라도 성능이 잘 나온다는 흐름을 보게 되었습니다.
그래서 저자들은 파라미터 자체도 없는 Average Pooling을 넣어보면 어떨까? 하고 구조를 완성해봤는데 오히려 SOTA를 달성하는 결과를 얻었다고 말합니다.
이렇게 제안된 PoolFormer는 MetaFormer의 구조의 Token Mixer 자리에 average pooling을 넣어 완성했다고 불 수 있습니다.
PoolFormer Architecture
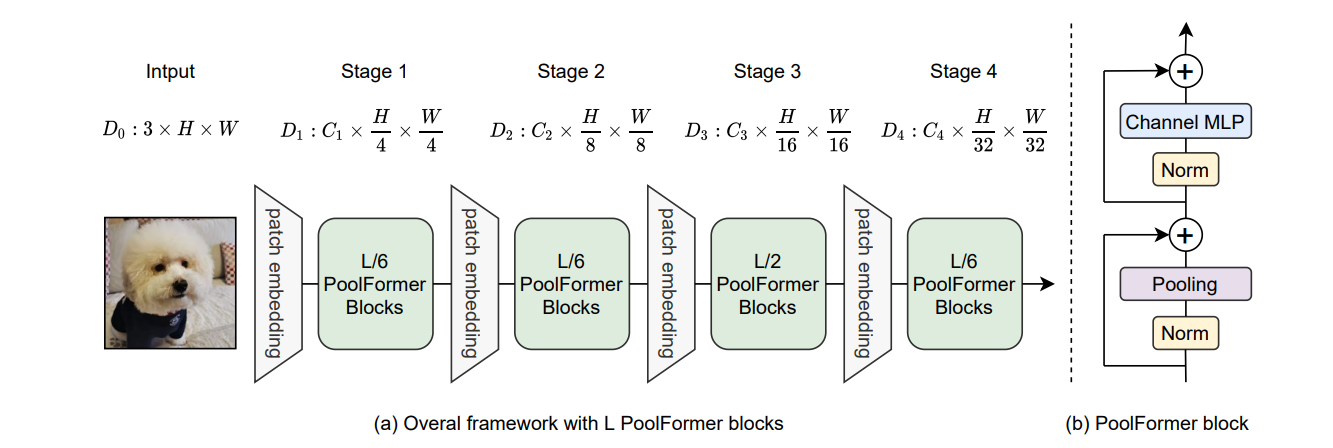
*L은 전체 블록의 개수, L/6은 전체의 1/6이 분포한다는 뜻임구조를 전체적으로 보면 patch embedding이 총 네 번 들어가고, 각 patch embedding 사이에 PoolFormer들을 여러개를 집어넣어서 특징을 추출하는 단계로 구성됩니다.
또한 이미지의 스테이지 자체는 기존에 사용되었던 image classification 모델들의 feature map 축소하는 비율과 유사하게 4배, 8배, 16배, 32배 축소가 되는걸 볼 수 있습니다.
MetaFormer
MetaFormer의 구조는 아래와 같이 구성되어 있으며,
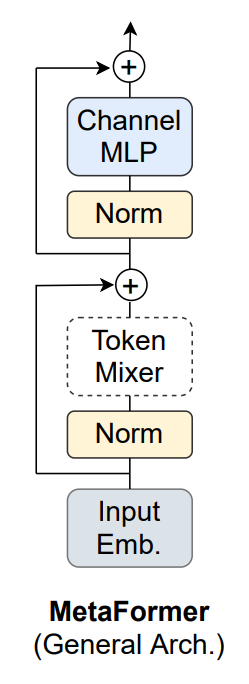
식으로는 다음과 같습니다.
average pooling
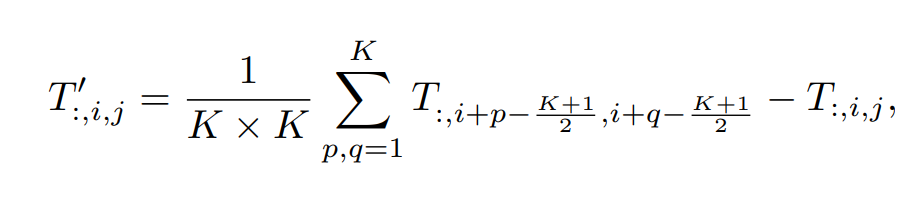

pooling자리에서 average pooling을 하고 normalization layer에서 넘어온 Input을 한번 빼는 점이 약간 다릅니다.
Ablation study
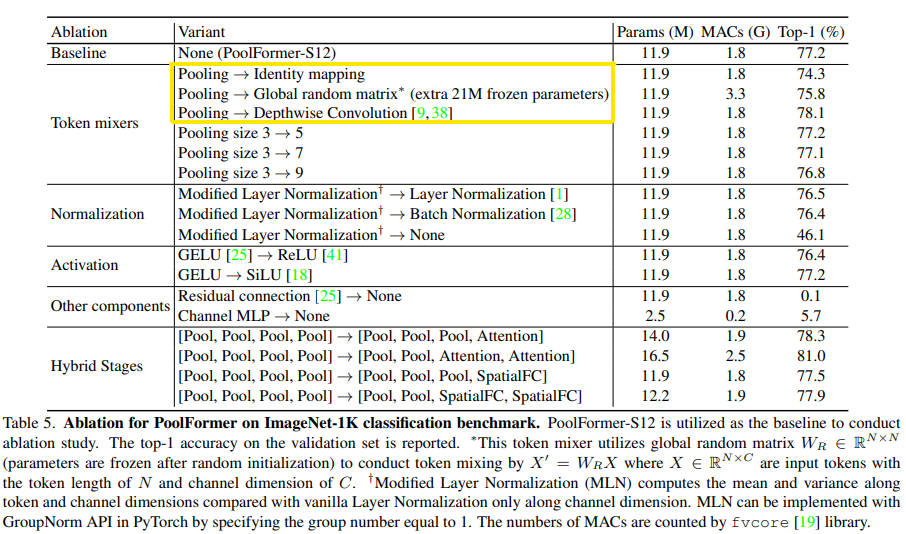
pooling 자체를 Identity mapping, 그냥 직접 전달하더라도 베이스라인에서 3% 밖에 안떨어지는 모습을 보이며 → metaformer 구조 자체가 훌륭하다는 것을 시사합니다.
감사합니다.
Reference
