- 진행기간 23. 1. 18. ~ 23. 3. 8.
🗓️ notion site
💬 github
포항공대 인공지능연구원 인턴으로 있으면서 내맘대로 만든 메뉴추천시스템 진행과정을 간략하게 정리해봤다. 프로젝트는 데이터 수집 단계부터 추천방정식 구현, 평가지표 고민까지 다양한 과정을 거쳤다.
약 2달이 좀 넘는 기간 동안 메뉴 추천을 구현해보면서, 단순 추천시스템을 만드는 것이 아니라 어떻게 하면 개인화된 추천을 할 수 있을지, cold start 문제는 어떻게 해결할지, 어떤 데이터를 더 이용해볼 수 있을지 고민해보는 시간이 되었던 것 같아 의미있었다.
또 메뉴 추천의 특성상 다른 추천보다 개인의 취향이 더 중요하게 작용하기 때문에, 어떻게 하면 사용자의 취향을 파악할 수 있을지를 우선으로 고민했다. 이를 위해 사용자의 취향에 따라 가중치를 다르게 부여하는 등의 작업을 통해 개인화된 추천을 구현해 나갔다. 개인화된 추천 시스템은 사용자의 다양한 취향을 이해하는 것이 중요하기 때문에 계속해서 추천 알고리즘 개선이 뒷받침되어야 하는 것 같다.
About this project
💡 메뉴(상품) 추천 알고리즘 설계 및 개발
- 소비자(고객 id 기반)가 방문한 상권 내 먹거리 매장에 대한 상호명, 구매 상품(메뉴) 등의 업종 정보와 소비자가 구매한 상품의 평점 등의 데이터를 수집 및 분석
- 소비자의 성별, 연령 등의 정보를 기반으로 유사 소비자군을 군집화하고 해당 군집을 기반으로 메뉴 추천 시스템 개발
- 해당 상품 추천 엔진으로서는 사용자 기반 추천 시스템으로 CBF 기법을 활용하여 유사도를 활용한 소비자 간의 user-based similarity를 기반으로 메뉴 추천 수행
- 유사도가 높은 소비자의 평점 정보를 바탕으로 타깃 유저에 대한 개인화된 메뉴 추천 수행
진행과정
1. 활용 데이터셋 탐색
음식 정보 생성을 위한 데이터셋과 개인의 음식 선호 관련 데이터셋 조사
I ) 강원도 원주시_다국어메뉴정보
(1) 데이터 정보
- 강원도 원주시에 위치한 음식점에서 판매하는 메뉴를 한국어, 중국어, 영어, 일본어로 적어놓은 데이터
- 식당명, 메뉴명, 메뉴가격, 지역특산메뉴여부 등의 메뉴정보를 포함
(2) 활용 방안
사용자 선호 메뉴 데이터와 결합하여 사용자가 메뉴를 고를 때에 가격을 많이 고려하는지 여부를 알기 위해 변수로 사용가능
(3) 한계 : 이용자에 대한 데이터가 단순 총 결제 금액일 경우 사용이 어려움
II ) 강원도 원주시_다국어메뉴설명정보
(1) 데이터 정보
- 강원도 원주시에 위치한 음식점의 메뉴에 대한 설명을 한국어, 중국어, 영어, 일본어로 적어놓은 데이터
- 식당명, 메뉴명, 메뉴설명(주재료, 조리법, 소스, 옵션) 등의 메뉴설명정보를 포함
(2) 활용 방안
- 메뉴별 한식/중식/일식/양식 대분류, 메뉴명 소분류를 사용하여 음식 정보 프로필 생성
- 대분류별 ('한식', '음료류', '제과류', '패스트푸드', '일식', '기타', '양식', '중식') 사용자 기호 판단에 사용- 메뉴별 주재료를 통해 음식 특성으로 사용하여 사용자 프로필과 대조하여 사용가능(주로 안먹는 재료, 매운맛을 내는 재료 등)
(3) 한계
- 음식에 대한 주문 빈도수 파악 불가
- 메뉴명 변수에 사이드메뉴가 포함되어 있고 매장마다 각기 다른 이름으로 불리어져 주메뉴를 분류하는 것이 복잡한 작업이 될 것이라고 생각됨
III) 소비자 유형별 선호 메뉴
(1) 데이터 정보 : 소비자 유형('건강식단추구', '경제성추구', '로컬푸드지향', '식생활모험가', '안전성중시')에 따른 계절별 음식 선호 순위
(2) 활용 방안
- 사용자 프로필 생성시 식생활 유형 분류 카테고리로 사용
- 식생활 유형에 따라 선호하는 메뉴가 다를 수 있으므로 유사도 분석시 유형별로 메뉴에 차별된 점수를 매겨 이용
- 계절별 메뉴 분류 및 추천에 사용 가능
(3) 한계 : 식생활 유형에 관한 사용자 프로필을 생성할 수 있을지에 대해 의문을 가짐
2. 데이터셋 활용안 구상
CF(nearest neighbor) & CBF hybrid 방식
(가) 같은 음식에 대한 여러 음식점 리뷰를 크롤링하여 태그정보 생성 + 음식 데이터(재료, 가격, 계절별 순위점수 등)를 결합하여 음식에 대한 프로필 완성(태그)
(나) 음식 간 코사인유사도 계산
(다) 기존 사용자의 과거 데이터(음식점 방문 기록) → 그 음식점에서 파는 주메뉴와 같은 음식점을 찾는 빈도수에 가중치를 주어 음식 선호도 계산
(라) 기존/신규 사용자 추천
- case 1) 기존 사용자의 경우 선호하는 음식 추천
- case 2) 신규 사용자에게 프로필 정보입력 받음(매운 음식 선호도, 한/중/일/양식 음식 분류 선호도, 안먹는 음식(재료) 등) → 유사한 프로필을 가진 음식 또는 popular 음식(치킨, 피자 등) 추천
3. 메뉴 데이터셋 정제
데이터셋 병합 및 정제, 음식 유사도 계산
페이지 상단의 github 링크 참고
4. 사용자 데이터 수집
네이버지도 리뷰 크롤링을 통해 사용자 데이터 직접 수집
페이지 상단의 github 링크 참고
- 사용자 유형 분류
- 신규/기존 유저에 대해 다른 처리
5. 추가 개선
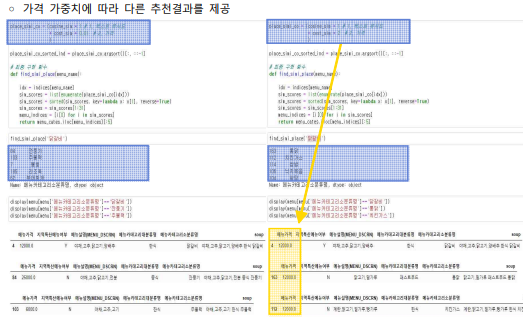
- 사용자유형별로 가격의 가중치를 달리할 수 있도록 개선
- 사용자유형별 메뉴순위 데이터와 사용자의 과거 음식 기록의 유사도를 계산하여 사용자 유형 분류(건강식단추구 / 경제성추구 / 로컬푸드지향 / 식생활모험가 / 안전성중시 )
- 사용자유형 유사도 가중치 사용
- 사용자유형과의 유사도를 가중치로 사용하고, 정의한 사용자유형에서 선호도가 높은 음식에 많은 점수를 부여할 수 있도록 행렬곱을 수행하여 같은 유형의 사용자라도 개인별 추천이 이루어질 수 있도록하고자 함
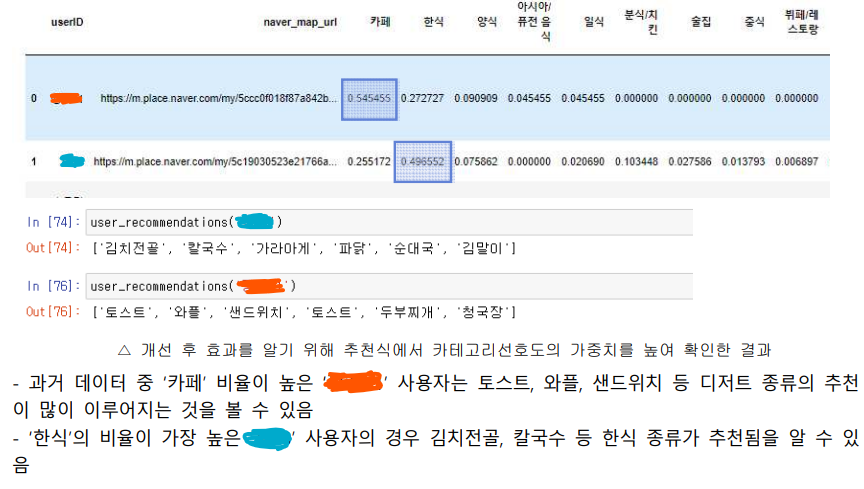
- 개인별 카테고리 선호도 반영
- 스크래핑한 사용자 리뷰 전처리시 삭제한 대분류를 이용하여 전체 데이터를 사용
- 각 사용자의 리뷰데이터 스크래핑시 식당명과 리뷰텍스트에서 메뉴명을 찾을 수 없는 데이터에서는메뉴에 대한 빈도수를 계산할 수 없는 문제점이 있었음
- 때문에 메뉴명이 없는 데이터를 보완하여 사용하기 위해 카테고리의 빈도수를 반영하여 카테고리(한/중/일/양) 선호도를 반영하고자 함
🔺 개선예시
6. 평가지표 탐색 및 고민
1) 추천시스템 평가 방법 조사
▶ 평가지표 중 오프라인 테스트 성능 지표의 적용방안에 대한 고민이 필요함
2) 오프라인 테스트 성능 지표
- RMSE (Root Mean Square Error) : 에러 값에 대한 지표로 일반적으로 rating error에 대한 값으로사용
- MAP@K (Mean Average Precision at K) : Precision 값에 대한 지표로 @k는 예측한 추천 리스트 중상위 K개에 해당하는 값으로 precision 계산 시 분모로 두고 계산
- nDCG (Normalized Discounted Cumulative Gain) : 순위를 고려한 평가 방법으로 상위의 랭크에 대해 지표 값의 차이가 큰 것이 특징
- MRR (Mean Reciprocal Rank) : 순위를 고려한 평가 방법으로 사용자가 선호하는 아이템이 추천리스트 중 몇 번째에 속하는 지에 대한 지표
3) 적용 방법 고민
(1) 사람의 카테고리 간 유사도를 계산하여 높은 유사도를 가진 사용자에게 다른 카테고리에서 선호도가 높은 음식을 추천
- ‘같은 카테고리 내에서 높은 유사도를 보일 시 다른 카테고리에서도 비슷한 선호도를 보일 것이다’라는 전제로 진행하여야 하는데 음식 선호 특성상 개인에 따라 카테고리별 선호도가 다를 수 있다는 점을 간과할 수 있음
(2) 추천한 음식을 제외한 나머지 음식에서 추천한 음식이 있는지 여부 및 개수를 평가
- 현재 방식의 경우 아이템 기반 협업필터링을 사용하여 가장 선호도가 높은 음식의 높은 유사도를보이는 음식을 추천해주는 방식을 사용함에 따라 가장 높은 선호도의 음식 Top3를 제외한 음식을고려하지 않고 있음
- 따라서 추천에 사용한 음식을 제외한 나머지 음식 기록에서 추천한 음식이 존재하는지 여부를 평가할 수 있음
- 성능지표 중 MAP@K를 사용하여 평가
(3) Train set, Test set으로 나누어 평가- 전체 데이터 중 비율을 정하여 분리하고 추천이 효용이 있는지 평가
