카운터의 확장
가산기는 숫자를 저장하기도 하고, 1씩 더해서 숫자를 세기도 하는 카운터를 이용하여 서로 더하거나 뺄셈을 가능하게 한다. 그러나, 카운터를 이용하여 한 자리씩(한 비트씩) 연산하게 된다면 엄청나게 느리게 연산이 될 것이다. 따라서 이전 가산기의 변형을 시도해 보자.
RCA4
RCA(Ripple Carry Adder)는 일반적인 input 2개(더하려는 값)과 output 2개(carry와 sum)로 이루어져 있다. 이것을 4개 묶어서 만들어낸 것이 RCA4이며, 0~15까지의 10진수 2개를 더하여 같은 범위의 10진수와 carry를 도출해낼 수 있다. 다음을 코드를 보자.
module RCA_4bit(a, b, cin, s, cout);
input [3:0] a, b;
input cin;
output cout;
output [3:0] s;
genvar i;
wire [4:0] tc; //cin과 각 RCA에서 내보내는 carry들을 저장/전송함
wire [3:0] q;
wire [3:0] g;
assign q = a & b; // AND게이트
assign g = a ^ b; // XOR게이트
assign tc[0] = cin;
for (i = 0; i < 4; i = i + 1)
begin
assign s[i] = g[i] ^ tc[i];
assign tc[i + 1] = q[i] | (tc[i] & g[i]);
end
assign cout = tc[4]; // Carry out
endmodule
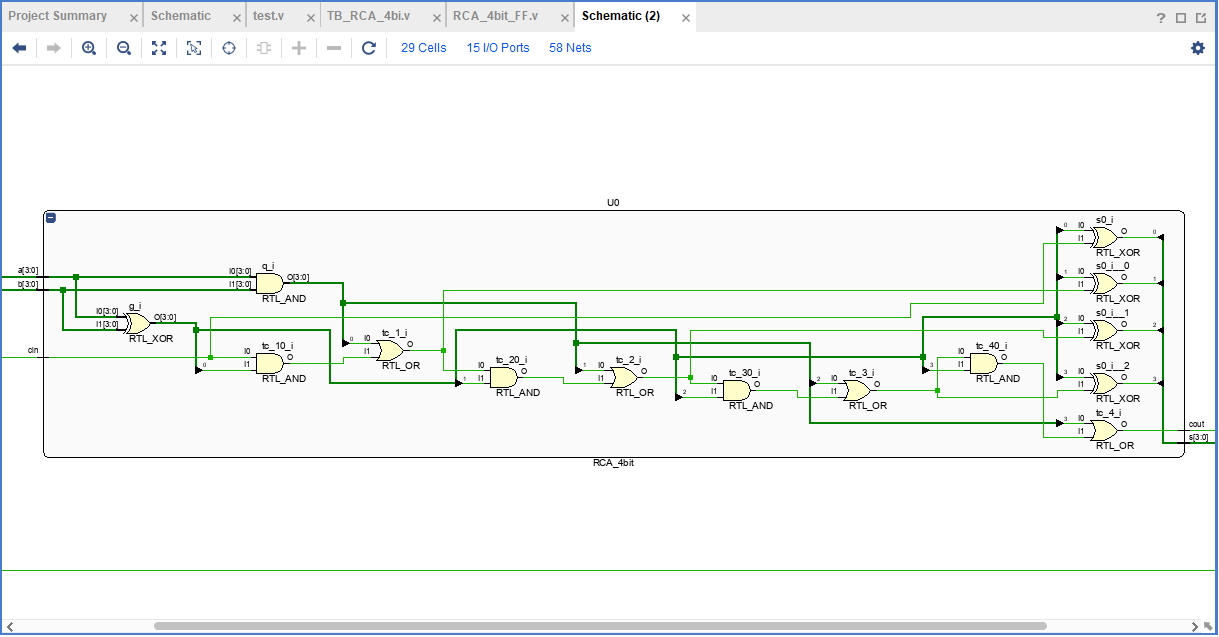
RCA4의 논리구조이다. (vivado너무편함) 우선, 양단에 clk를 넣어 timedomain을 도입시키기 위해 플립플롭을 구성시켰다. 이것은 우리가 조합회로에서 순차회로로 변경하여 vivado 프로그램에서 input to output time을 측정할 수 있게 한다. 즉, RCA와 다른 것과 비교가 효율과 시간 비교를 가능케 한다는 것이다.
시간 측정을 위한 시간 차원 추가
따라서 다음과 같이 코드를 변형시켜서 테스트벤치에 입력한다. 나는 FlipFlop의 줄임말을 붙여서 FF를 추가로 새 바깥 모듈에 명명하였다.
module RCA_4bit_FF(a, b, cin ,clk ,s ,cout); // clk가 추가됨
input [3:0] a, b;
input cin, clk; // clk 추가
output reg cout;
output reg [3:0] s;
reg [3:0] a0, b0;
reg cin0;
wire cout0;
wire [3:0] s0;
always @ (posedge clk) //플립플롭
begin
a0 <= a;
b0 <= b;
cin0 <= cin;
end
RCA_4bit U0 (a0, b0, cin0, s0, cout0); //메인모듈
always @ (posedge clk) //플립플롭
begin
s <= s0;
cout <= cout0;
end
endmodule
결과
이렇게 되면, clk posedge마다 활성화된 입력이 출력되는 시간과 차이를 보이게 되고, 이를 통해 상대적으로 다른 방식의 가산기와 시간을 비교할 수 있다. 다음 RCA의 소요 시간과 chip의 사용량을 보자.
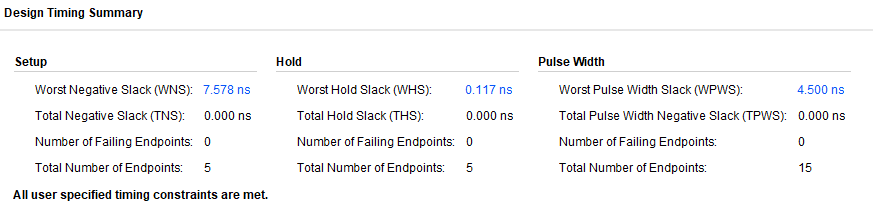
10ns동안 시행하였고, 7.578ns의 setup time을 얻었다. 또한 0.117ns동안 up time을 가졌다. 다음 그림을 보자.
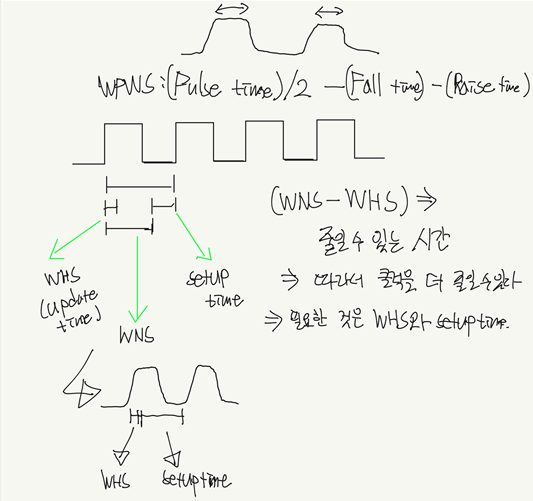
결과를 보면 3가지의 수치가 등장하는데, 이 중 pulse time은 그저 클럭에 연관하기 때문에 중요한 사항은 아니다. 주목해야 할 것은 WNS(worst negetive slack)과 WHS(worst hold slack)인데, 그림을 보면 우리가 필요로 해야 할 것은 setup time과 up time인 WHS이다. setup time은 주기인 10ns에서 WNS를 빼면, 2.422ns가 나오고, WHS가 0.117ns이므로 두 시간을 더하면 우리가 클럭을 줄일 수 있는 시간, 다시말하면 조합회로와 플립플롭 회로가 이 연산을 수행하는데 걸리는 총 시간을 확인할 수 있다.
- up time : 회로가 동작을 수행하기 위해서 필요한 최소 입력 시간.
- setup time : 회로가 다음 플립플롭으로 연산 후의 정보를 저장하기 위해서 걸리는 시간.
결과값(걸린 시간) : 2.539ns
CLA4
CLA(Carry Lookahead Adder)는 RCA의 단점인 내부 절차에서 여러 논리 게이트를 거쳐서 cout과 sum을 얻어내야만 다음 연산으로 차례로 넘어갈 수 있는 단점을 개선하여 속도를 증가시킨 가산기이다. 다만 단점은, 가산기가 복잡해지기 때문에 큰 용량을 사용한다는 단점이 있다.
CLA의 기본 구조는 다음 그림을 보면서 설명하겠다.
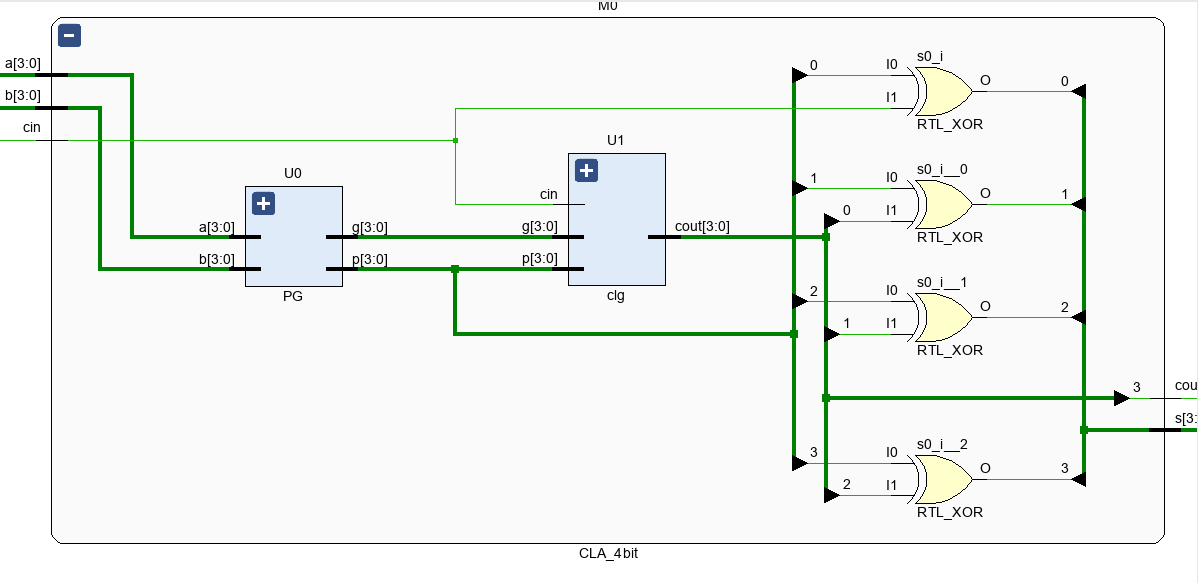
module CLA_4bit(a, b, cin, cout, s);
input [3:0] a, b;
input cin;
output cout;
output [3:0] s;
wire [3:0] p ,g;
wire [3:0] tc;
assign cout = tc[3];
PG U0 (a, b, p, g);
clg U1 (p, g, cin, tc);
assign s[0] = p[0] ^ cin;
assign s[1] = p[1] ^ tc[0];
assign s[2] = p[2] ^ tc[1];
assign s[3] = p[3] ^ tc[2];
endmodule마지막 assign문을 제외한 모든 구조가 pg와 clg로 구성되어 있고, 이들에게서 연산한 결과를 토대로 SUM과 COUT을 출력하는 구조이다.
PG
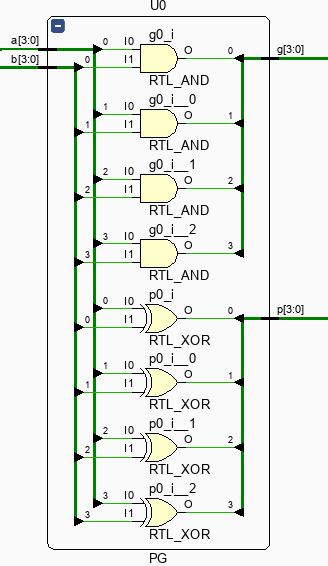
pg 모듈의 역할은 input을 먼저 합성하여 and와 xor 형태의 신호로 미리 변환하여 연산을 빠르게 하고, 모듈의 복잡성을 더는 역할을 한다. 두 신호를 합성하여 g, p의 형태로 출력한다.
module PG(a, b, p, g);
input [3:0] a, b;
output [3:0] p, g;
assign p[0] = a[0] ^ b[0];
assign p[1] = a[1] ^ b[1];
assign p[2] = a[2] ^ b[2];
assign p[3] = a[3] ^ b[3];
assign g[0] = a[0] & b[0];
assign g[1] = a[1] & b[1];
assign g[2] = a[2] & b[2];
assign g[3] = a[3] & b[3];
endmoduleclg
module clg(p, g, cin, cout);
input [3:0] p, g;
input cin;
output [3:0] cout;
assign cout[0] = g[0] | p[0] & cin;
assign cout[1] = g[1] | p[1] & g[0] | p[1] & p[0] & cin;
assign cout[2] = g[2] | p[2] & g[1] | p[2] & p[1] & g[0] | p[2] & p[1] & p[0] & cin;
assign cout[3] = g[3] | p[3] & g[2] | p[3] & p[2] & g[1] | p[3] & p[2] & p[1] & g[0] | p[3] & p[2] & p[1] & p[0] & cin;
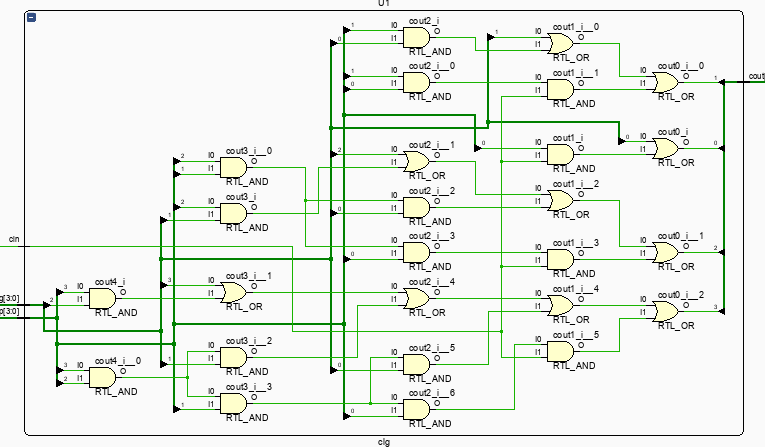
endmoduleclg 모듈의 역할은 사실상 CLA 모듈의 메인 역할을 수행하는 것이다. 이전 carry에 구애받지 않고 모든 sum 4개와 carry를 즉시 받아서 연산을 수행한다. 이미지를 보면, cin가 어떤 과정을 거치지 않고 최종 연산에 직접적으로 영향을 끼치는 것을 확인할 수 있으며, RSC보다 훨씬 빨리 연산할 수 있을 것이라는 예상이 가능하다.
결과
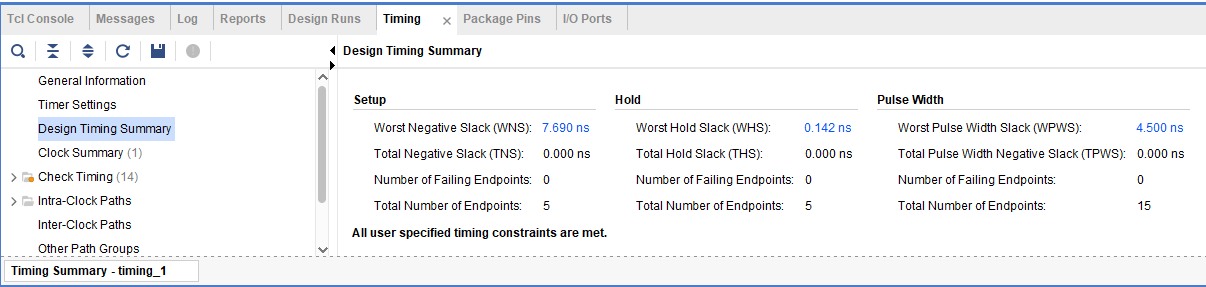
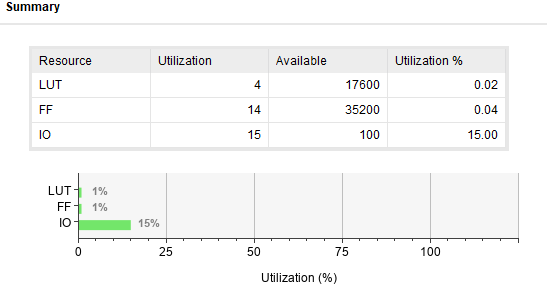
- up time : 0.142ns
- setup time : 2.310ns
결과값(걸린 시간) : 2.452ns
결론
우리가 앞에서 언급했듯이 결과값을 살펴보면, CLA가 RCA에 비해 속도가 빠르지만, 면적은 유의미한 차이가 나지 않았다. 다음 번 코드인 16bit 연산에서는 유의미한 차이점을 발견할 수 있을 것이라고 생각한다.
