Grouping / Apply, Map
📂 Grouping
그룹을 지어서 특정 관점을 가지고 보겠다는 뜻
🗒️ 데이터의 각 host_name의 빈도수를 구하고 host_name으로 정렬하여 상위 5개를 출력하라
df.groupby('host_name').size().sort_index()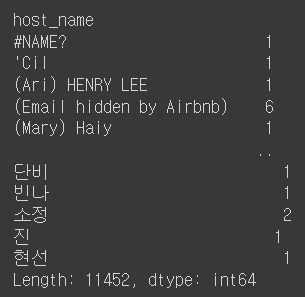
Ans = df.host_name.value_counts().sort_index()
Ans.head()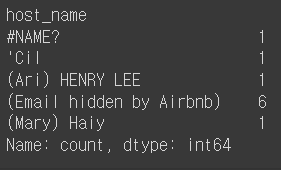
- Ans = df.groupby('host_name').size().sort_index()
- Ans = df.host_name.value_counts().sort_index()
↪️
1. value_counts()
- host_name이 가지고 있는 유니크한 개수를 세준다. 개수가 많은 순서대로
- 내림차순으로 정렬을 해준다.
- host_name이 가지고 있는 유니크한 개수를 세준다.
- 개수가 많은 순서대로 내림차순으로 정렬을 해준다.
- 널값을 세주지는 않는다.
하지만 dropna=False 를 넣어주면 널값도 같이 세준다.
- size() - 널값이 있어도 세준다.
📌그룹핑을 한 애들은 대부분 인덱스로 선언이 된다.
🗒️데이터의 각 host_name의 빈도수를 구하고 빈도수로 정렬하여 상위 5개를 출력하라
Ans = df.groupby('host_name').size().\
to_frame().rename(columns={0:'counts'}).\
sort_values('counts',ascending=False)
Ans.head(5)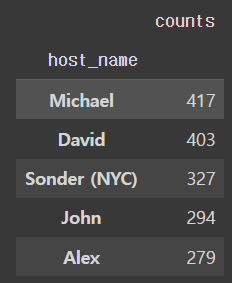
↪️ 코드가 너무 길때 '\'를 넣어주면 엔터로 인식을 해서 쓸 수 있다.
to_frame() -데이터 프레임화 하겠다는 이야기
rename(columns={0:'counts'})- 0을 count라는 name으로
변경을 할 것이다.
sort_values('counts',ascending=False)- count라는 것을
기준으로 내림차순df.groupby('host_name').size()
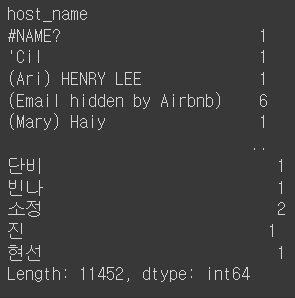
df.host_name.value_counts().to_frame()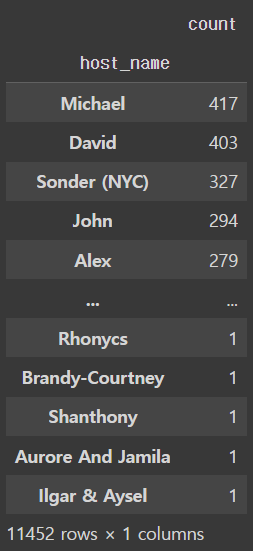
🗒️neighbourhood_group의 값에 따른 neighbourhood컬럼 값의 갯수를 구하여라
type(Ans)pandas.core.series.Series
↪️ 사실 데이터 프레임이 아닌 시리즈이다.
Ans = df.groupby(['neighbourhood_group','neighbourhood'], as_index=False).size()
Ans.head()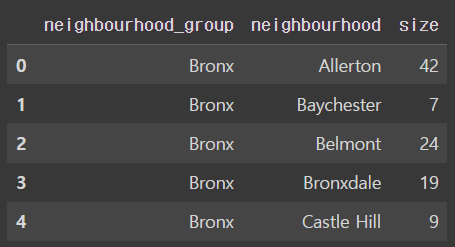
↪️
1. groupby - 두개의 기준으로 grouping을 할 수도 있다.
2.as_index=False- 시리즈여서 데이터 프레임화로 변경해주기 위해서
이 명령어를 쓴다.↪️ 인덱스로 설정되는 것이 아닌 하나의 컬럼으로 설정되서 조금 더 시각적으로 직관적으로 볼 수 있게 된다.
🗒️ neighbourhood_group 값에 따른 reviews_per_month 평균, 분산, 최대, 최소 값을 구하여라
Ans = df.groupby('neighbourhood_group')['reviews_per_month'].agg(['mean','var','max','min'])
Ans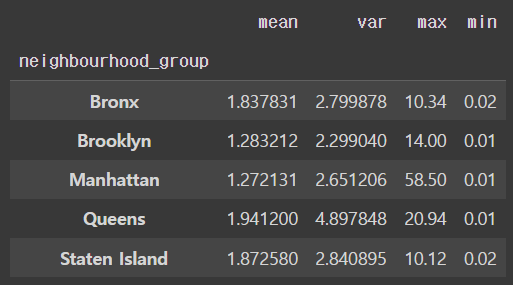
↪️
agg() - 사칙 연산을 어떤 걸 해줄지에 대해 선언을 해준 것이다./ 한번에 여러가지 사칙연산을 할 수 있다.
📌 참고
- 계층적 indexing 없이 구하라-> 계층적으로 보이는 것을 좀 더 직관적으로 만들어달라는 뜻
- fillna(-999) - 빈 값이 있으면 -999로 채워넣겠다는 말
🗒️데이터중 neighbourhood_group 값에 따른 room_type 컬럼의 숫자를 구하고 neighbourhood_group 값을 기준으로 각 값의 비율을 구하여라
Ans = df[['neighbourhood_group','room_type']].groupby(['neighbourhood_group','room_type']).size().unstack()
Ans.loc[:,:] = (Ans.values /Ans.sum(axis=1).values.reshape(-1,1))
Ans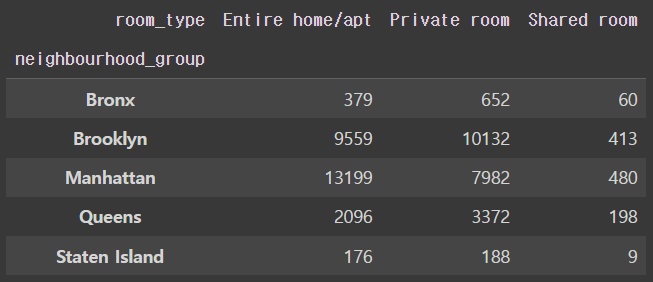
↪️
1.[['neighbourhood_group','room_type']이 데이터들을 가져와서groupby( ['neighbourhood_group','room_type']를 씌운 것이다.
2.size().unstack()- 숫자를 세고 풀어준다.
3.Ans.loc[:,:]- 모든 값을 가져온다.
Ans.values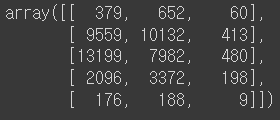
↪️ Ans.values- 각 값에 대한 array를 Matrix 형태로 뽑아준다.
Ans.sum(axis=1)
↪️ Ans.sum(axis=1) - 컬럼값을 기준으로 sum을 하겠다는 말
Ans.sum(axis=1).values
**Ans.values /Ans.sum(axis=1).values.reshape(-1,1)**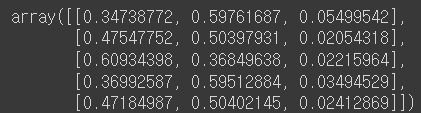
↪️
1.Ans.values를Ans.sum(axis=1).values.reshape(-1,1)로
나눠준 것이다.
2.values.reshape(-1,1)로 데이터 형태를 만들어주고 같은 형태끼리 나눠줄 수 있게 한다.
📂 Apply, Map
🗒️ Income_Category의 카테고리를 map 함수를 이용하여 다음과 같이 변경하여 newIncome 컬럼에 매핑하라
dic = {
'Unknown' : 'N',
'Less than $40K' : 'a',
'$40K - $60K' : 'b',
'$60K - $80K' : 'c',
'$80K - $120K' : 'd',
'$120K +' : 'e'
}
df['newIncome'] = df.Income_Category.map(lambda x: dic[x])
Ans = df[['newIncome', 'Income_Category']]
Ans.head()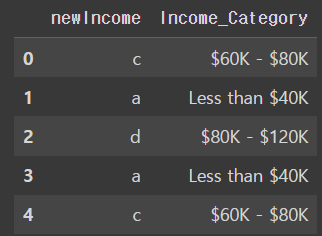
↪️
1. dic - dictionary / 한쌍의 데이터로 이루어짐
2.Income_Category이 변수를 x로 보는 것이다.
3. dic[x]- 앞에 있는 dictionary에 income 카테고리를 넣어주겠다는 뜻
📌
1. 람다(lambda) 함수는 함수형 프로그래밍에서 중요한 개념 중 하나로, 익명 함수(anonymous function)라고도 부릅니다.
2. 람다 함수는 이름이 없는 함수로, 일반적으로 함수를 한 번만 사용하거나 함수를 인자로 전달해야 하는 경우에 매우 유용하게 사용됩니다.
3. apply()는 사용자 정의한 하나의 데이터 프레임 시리즈에 적용할 때
많이 쓴다.
4. def - 내가 정의를 만들어서 쓰고 싶을 때 쓰는 것
🗒️ Customer_Age의 값을 이용하여 나이 구간을 AgeState 컬럼으로 정의하라. (0-9: 0 , 10-19: 10 , 20-29: 20) … 각 구간의 빈도수를 출력하라
df['AgeState'] = df.Customer_Age.map(lambda x: x//10 *10)
Ans = df['AgeState'].value_counts().sort_index()
Ans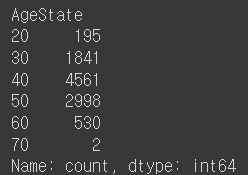
↪️
1.Customer_Age- 연속형 숫자형의 변수
2.map(lambda x- 맵핑을 변경을 해준다는 말
3. x//10 - 여기서 //는 나눗셈 후 몫을 나타내준다.49//10*10
40
🗒️ Education_Level의 값중 Graduate단어가 포함되는 값은 1 그렇지 않은 경우에는 0으로 변경하여 newEduLevel 컬럼을 정의하고 빈도수를 출력하라
df['newEduLevel'] = df.Education_Level.map(lambda x : 1 if 'Graduate' in x else 0)
Ans = df['newEduLevel'].value_counts()
Ans 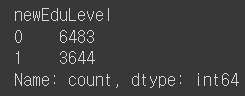
↪️
1.if 'Graduate' in x else 0- if else의 축약문으로 볼 수 있다.
2.map(lambda x : 1 if 'Graduate' in x else 0)- 두번째 x에 Graduate가 있으면 1을 내뱉고 없으면 0을 내보낸다.
여기서 map 을 apply로 바꿔도 같은 결과가 나온다.
import numpy as np
df['newEduLevel'] = np.where( df.Education_Level.str.contains('Graduate'), 1, 0)
Ans = df['newEduLevel'].value_counts()
Ans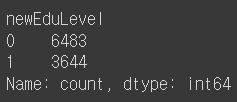
↪️
1.np.where( df.Education_Level.str.contains('Graduate'), 1, 0)↪️ np.where은 앞에 있는 조건
(df.Education_Level.str.contains('Graduate'))을 만족하면 1 아니면 0으로 변환하라는 의미이다.
📌 바로 위의 두개의 코드처럼 동일한 기능을 수행하는데 다양한 기능을 통해서 다양한 명령어를 통해서 결과를 내뱉을 수 있다.
🗒️ Marital_Status 컬럼값이 Married 이고 Card_Category 컬럼의 값이 Platinum인 경우 1 그외의 경우에는 모두 0으로 하는 newState컬럼을 정의하라. newState의 각 값들의 빈도수를 출력하라
def check(x):
if x.Marital_Status =='Married' and x.Card_Category =='Platinum':
return 1
else:
return 0
df['newState'] = df.apply(check,axis=1)
Ans = df['newState'].value_counts()
Ans 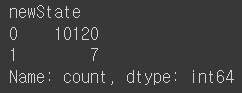
↪️
1. map보단 사용자 정의함수를 만들어 놓고 apply로 정의하는 것이 좋다.
2.axis=1-행기준으로 출력이냐 열기준으로 출력이냐 정해야되는데 이건 열기준으로 출력한다.
📌 참고
df['Gender'] = df.Gender.apply(changeGender)
↪️ gender라는 하나에 적용하므로 축기준을 안정해줘도 된다.
