Pivot/ Merge, Concat
Pivot
행에 대한 인덱스를 설정해주고 컬럼에 어떠한 것들을 어떤 차원으로 위치를 시킬지 설정해준다.
🗒️ Indicator을 삭제하고 First Tooltip 컬럼에서 신뢰구간에 해당하는 표현을 지워라
신뢰구간-> First Tooltip 부분
df.drop('Indicator',axis=1,inplace=True)
df['First Tooltip'] = df['First Tooltip'].map(lambda x: float(x.split("[")[0]))
Ans = df
Ans.head()
↪️
1.drop- 말그대로 삭제
2.axis=1- 행을 삭제할 것인지 열을 삭제 할 것인지 축을 설정을 해준다.
3.inplace=True)- 실제 원본에도 반영을 하겠다는 뜻
4.x.split("[")[0]- '[' 를 기준으로 split를 하겠다는 말, 여기서 첫번째 숫자만 남길거라 0을 넣어준 것이다.
📌
1. ⭐pivot을 만들때는 index/columns/values 세개가 짝꿍이다.
2. aggfunc- 어떠한 연산을 할 것인지 알 수 있다.
3. 우리가 특정한 데이터를 가져왔을 때 정말 잘 가져왔냐는 의문이 들때 확인 방법-> ex) kr.Country.unique()- kor만 가져온 것을 확인 할 수 있다.
🗒️ 한국 올림픽 메달리스트 데이터에서 년도에 따른 medal 갯수를 데이터프레임화 하라
Ans = kr.pivot_table(index='Year',columns='Medal',aggfunc='size').fillna(0) Ans.head()
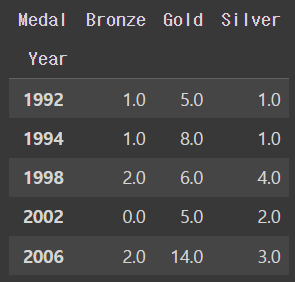
↪️
1. value 값을 정할 수 없다.
2. 어떤 특정한 값들이 정해져 있는 것이 아니기 때문에 aggfunc를 가지고 사칙연산을 통해서 세겠다는 말
3. 없는 값에 대해서는fillna(0)을 넣어주겠다.
📌
1. Bronze Gold Silver의 순서를 바꿔주려면?
Ans[['Bronze', 'Silver', 'Gold']] 나 Ans[['Gold', 'Silver', 'Bronze']]해준다.
2. pivot 테이블에서는 values 값을 사용해야되는 경우도 있고 aggfunc을 바로 써주는 경우도 있다.
Merge, Concat
데이터를 병합하는 기능들
✏️ df.iloc[:4,:]
0~3 행을 추출을 하고 컬럼은 모든 값을 추출
✏️ df.iloc[4:,:]
4~ 모든 데이터 그리고 열도 모든 데이터 가져온다.
✏️ total = pd.concat([df1,df2], axis=0)
df1와 df2를 합쳐주겠다. axis=0-> 행 기준으로 합치겠다는 이야기
두개를 위아래로 붙이겠다는 이야기
✏️ pd.concat([df3,df4],join='inner')
둘다 있는 것만 붙이겠다는 이야기
✏️ Ans = pd.concat([df3,df4],join='outer').fillna(0)
다 합치기 위해서는 join의 옵션인 outer를 이용한다.
✏️ Ans =pd.merge(df5,df6,on='Algeria',how='outer').fillna(0)
df5에 df6를 양쪽에 존재하는 값만 나오게하는 inner로 Algeria 키 값으로 붙인다.
Algeria를 기준으로 Andorra Angola가 붙을 때 merge를 쓴다.
조인의 개념을 사용하는 게 merge이고 데이터를 합칠때 사용하는 게 concat이다.
Stats
📌
1.value_counts()는 데이터 eda를 하거나 데이터에 대한 파악을 할 때 사용
2. del -데이터 바로 제거 -> 한번 삭제한 데이터는 다시 복구를 못해서 위험성이 있따.데이터를 다른 변수에 저장 해놓으면 맨위까지 다시 올라가지 않아도 된다.
