실습환경 : Oracle 11g
시스템 성능 저하 : select 방식에 focus
비효율적인 Input / Output 방법에 개선하는 것에 focus를 둠
문제유형
- indexing ( 가장 비중이 큼 )
- sql
- table
성능저하의 요인
- optimizer 누락 ( 비유하자면 실시간 교통정보를 알려주는 네비게이션 )
- access 누락
- 최적이 아닌 query plan
- 잘못 작성된 sql
실행계획에 따라 엄청난 수행속도 차이가 발생
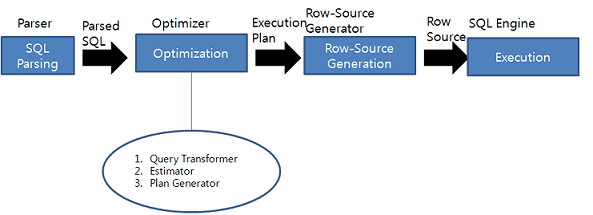
select문 처리과정 : Parsing -> Excute -> Fetch
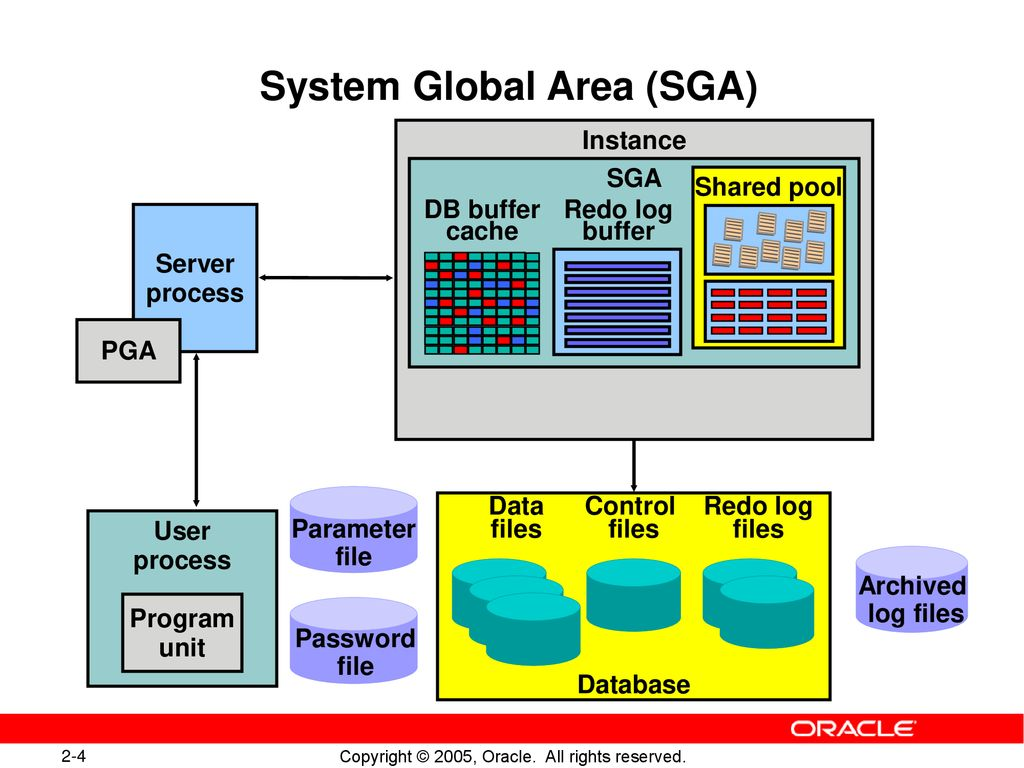
1. Buffer Cache를 이용한 데이터 Access
select * from customer where id = '005';
-1. DD 등의 내부정보를 통해서 Customer 테이블의 id = '005' 데이터가 있는 block의 위치정보를 알아냄
-2. buffer cache 확인하여 메모리에 상주하는지 확인 (LRU)
2. Hard parsing vs Soft parsing
1.select from EMP;
2.select from emp;
위 두 질의는 같은 테이블을 조회하지만 대소문자에 따라 다른 쿼리 id를 가지게 된다.
이때 메모리에 실행이력이 존재한다면 Soft parsing 이전 실행계획을 토대로 실행하게 됨
만약, 존재하지 않는다면 Parsing을 하게 됨 Hard Parsing 을 한다는 것은 다시 실행계획을 세우는 과정이다.3. Storage block
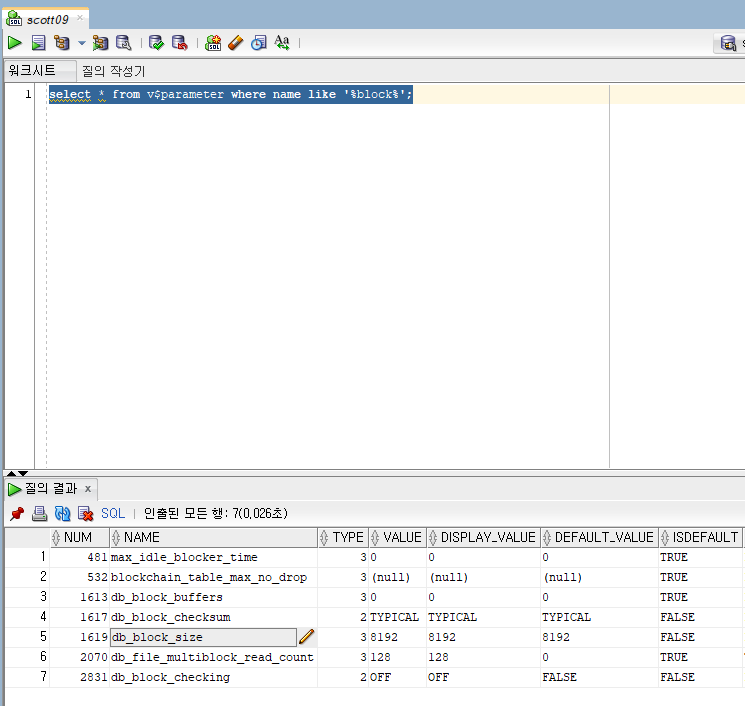
select 질의를 할시 where empno = 60011; 을 1건 조회하는 조건을 주더라도
block 단위로 메모리에 올리게 된다 ( 데이터의 최소단위 ) 그러므로 필요에따라 block size를 줄여야함 기본 block size = 8k
Data block < Extents < Segments < Tablespace
작은 block : 동일한 block에 다량의 transaction 유발 가능성이 있는경우
큰 block : dw성 데이터
4. Query planning ( 실행계획 )
- 들여쓰기가 가장 많이 된 row 부터 위로 읽음
- full table scan : 전체 조회
- index scan : index 타고 조회
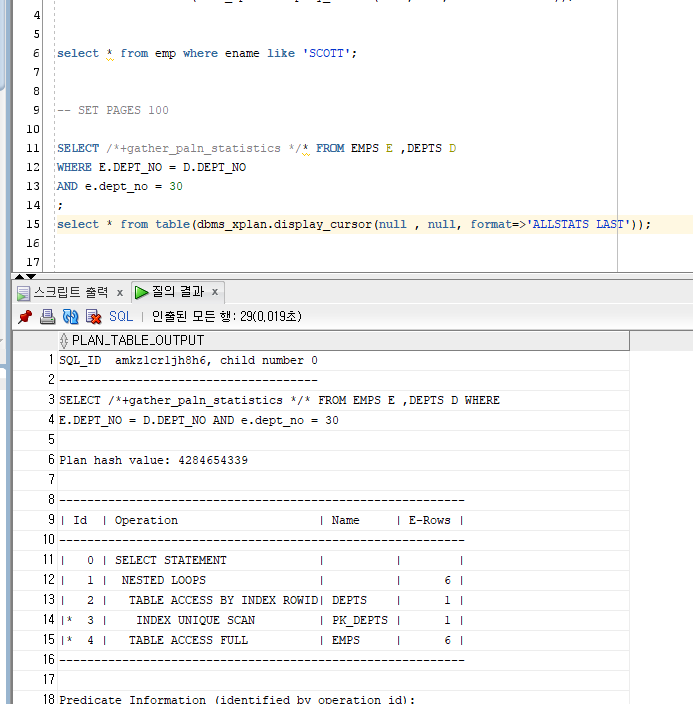
읽는 순서 3-2-1-4-0
일반적으로 full table scan이 항상 효율적이지 않은것은 아님
극히 일부의 데이터를 추출하는 경우에는 index scan이 효율적이지만 대부분의 데이터를 추출해야하는 경우에는 full table scan이 효율적일 수 있다.
full table scan 비용 = 전체 블록 수 / DB_FILE_MULTIBLOCK_READ_CNT
Index scan 비용 = Selectivty * Cluster-Factor
DMBS_XPLAN 사용법
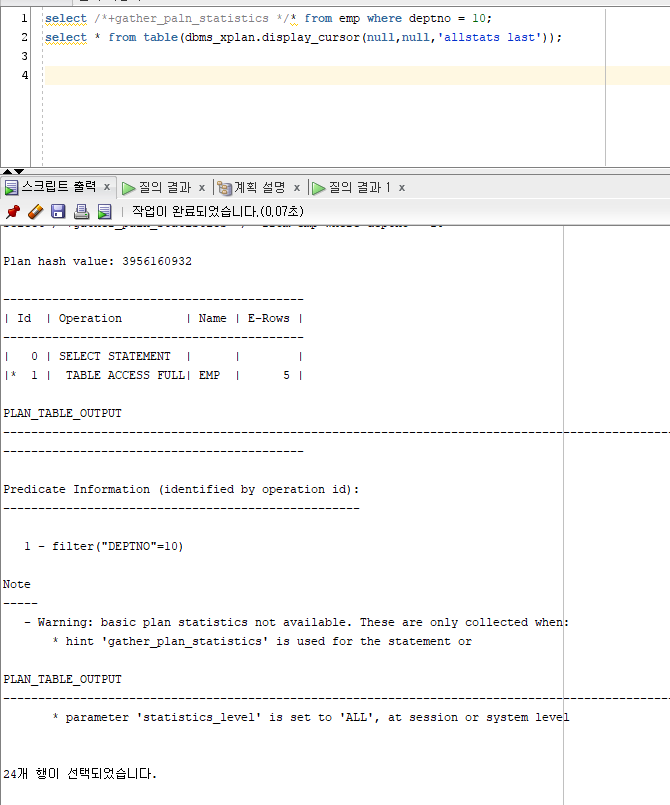
5. Query Tranforamtion
동일한 결과를 가져오는 보다 효율적인 형태로 QUERY 변환
EX ) ename LIKE 'WARD' -> ename ='WARD'
6.Optimizer 최적화
CBO VS RBO
- RBO : 15가지 룰에 의해서 계획됨
- CBO : COST 기반 -> 비용 산출을 위해서는 통계정보 최신화 필수
7.실행계획 제어
: 옵티마이저의 실행계획을 원하는대로 변경 가능
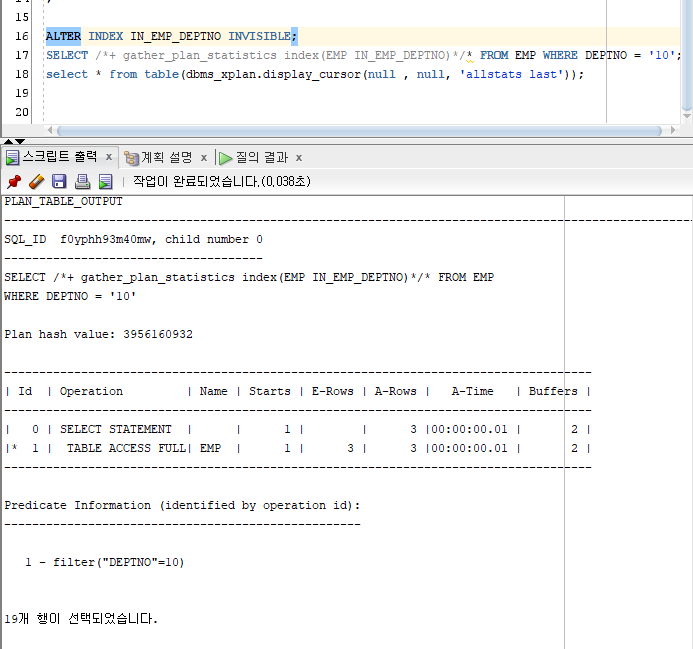
Hint 사용 /+index(EMP IX_EMP)/
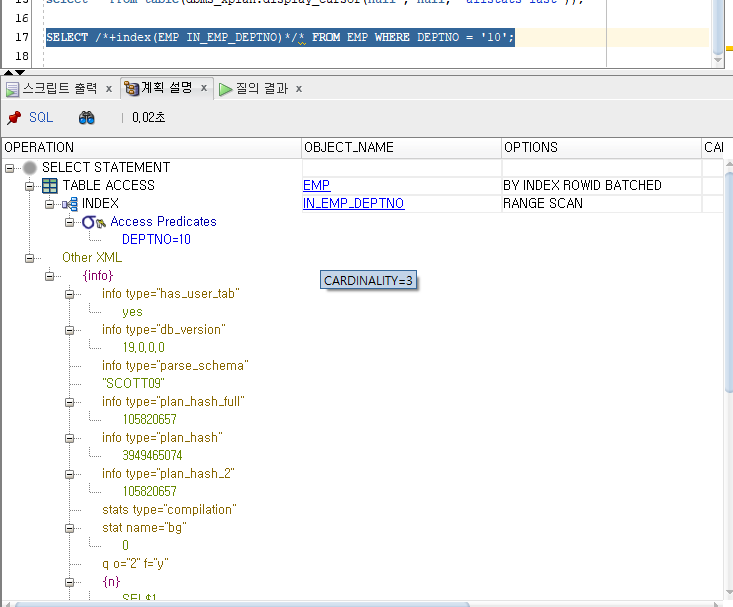
SELECT /*+ gather_plan_statistics index(EMP IN_EMP_DEPTNO)*/* FROM EMP WHERE DEPTNO = '10';
select * from table(dbms_xplan.display_cursor(null , null, 'allstats last'));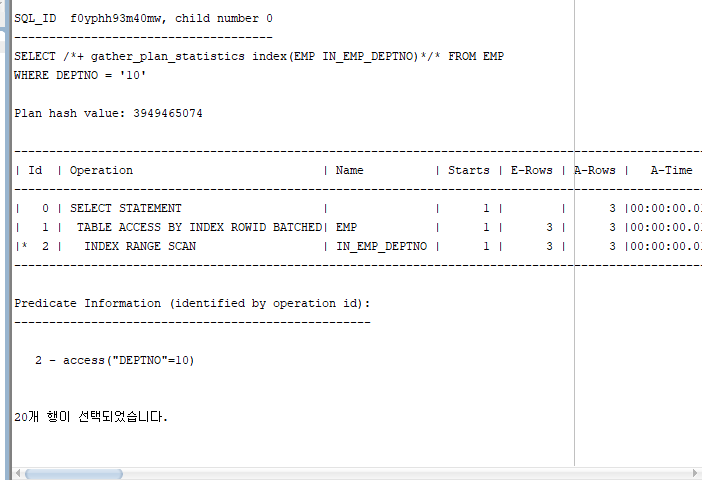
INDEX INVISIBLE : 사용 못하게 설정