1. index 생성
- JOIN KEY의 연결고리에는 index 필요
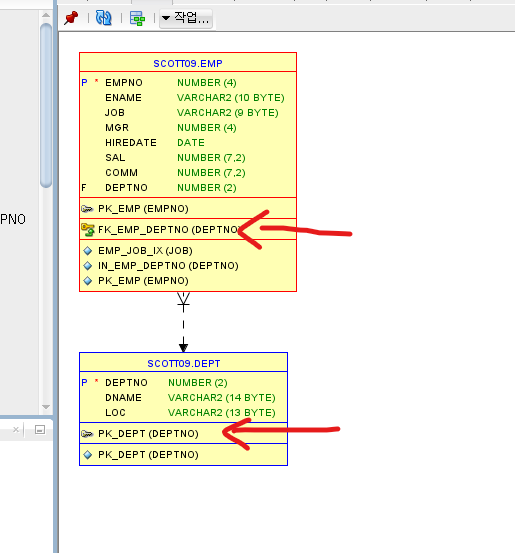
ex)dept 테이블의 depno는 pk emp 테이블의 deptno는 fk - 인덱스의 개수를 선정 할 때 DML을 고려해야 함 ( SELECT 퍼포먼스만 고려해선 안된다.)
2.INDEX FAST FULL SCAN
테이블의 인덱스가 존재하는 PK_EMP를 이용해서만 사용가능
SCOTT09 PK_EMP UNIQUE VALID NORMAL N NO NO EMPNO

3.결합인덱스
Create index TMP_IDX01 on TMP ( PROD_ID , STRT_DT); -- 결합인덱스
Create index TMP_IDX02 on TMP ( STRT_DT,PROD_ID); -- 결합인덱스
선두 컬럼에 따라 퍼포먼스가 다름
조건절에 항상 사용되거나 , 자주 등장하는 컬럼들을 선정
= 조건으로 자주 조회되는 컬럼들을 앞쪽에 둔다.4. 쿼리튜닝 ( DATA ACCESS 효율 향상 )
IS NOT NULL 과 같은 부정형 조건에 대해 인덱스를 사용할 수 없음
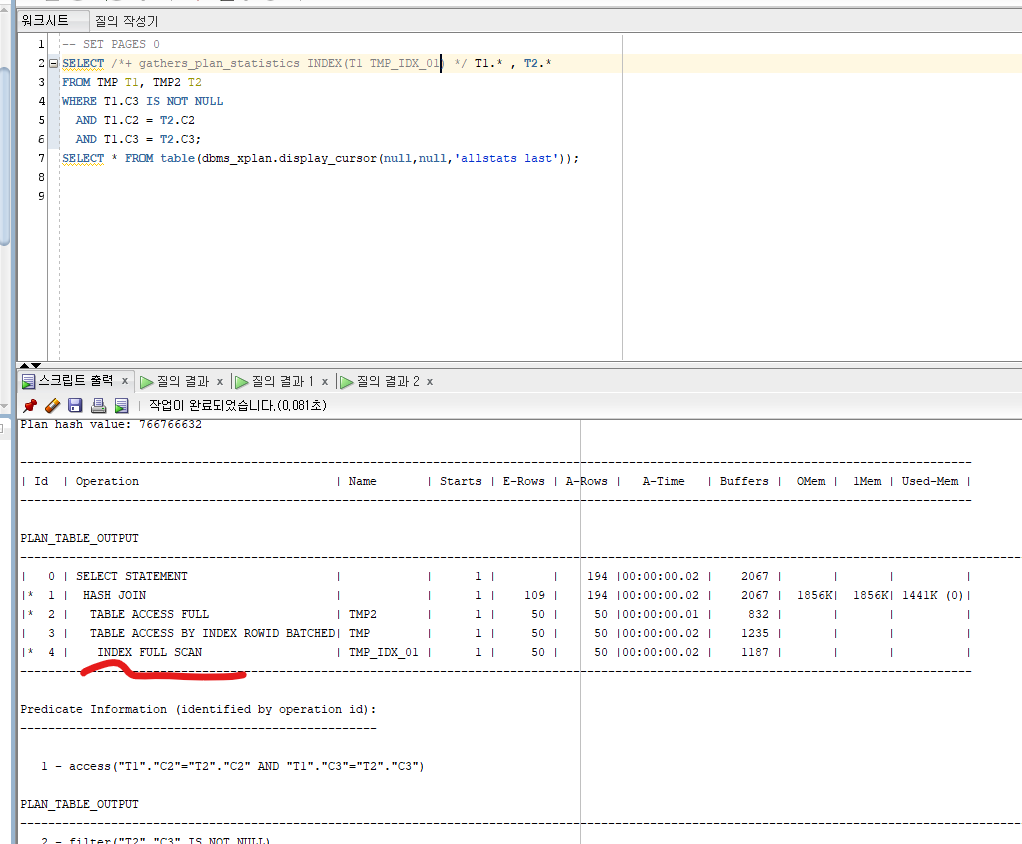
인덱스가 존재하지만 INDEX FULL SCAN으로 I/O가 증가
T1.C3와 같은 CHAR 타입의 T1.C3 > '' 을 사용하면 IS NOT NULL 같은 효과를 줄 수 있으며 INDEX RANGE SCAN 을 이용해 Buffer를 줄일 수 있다.
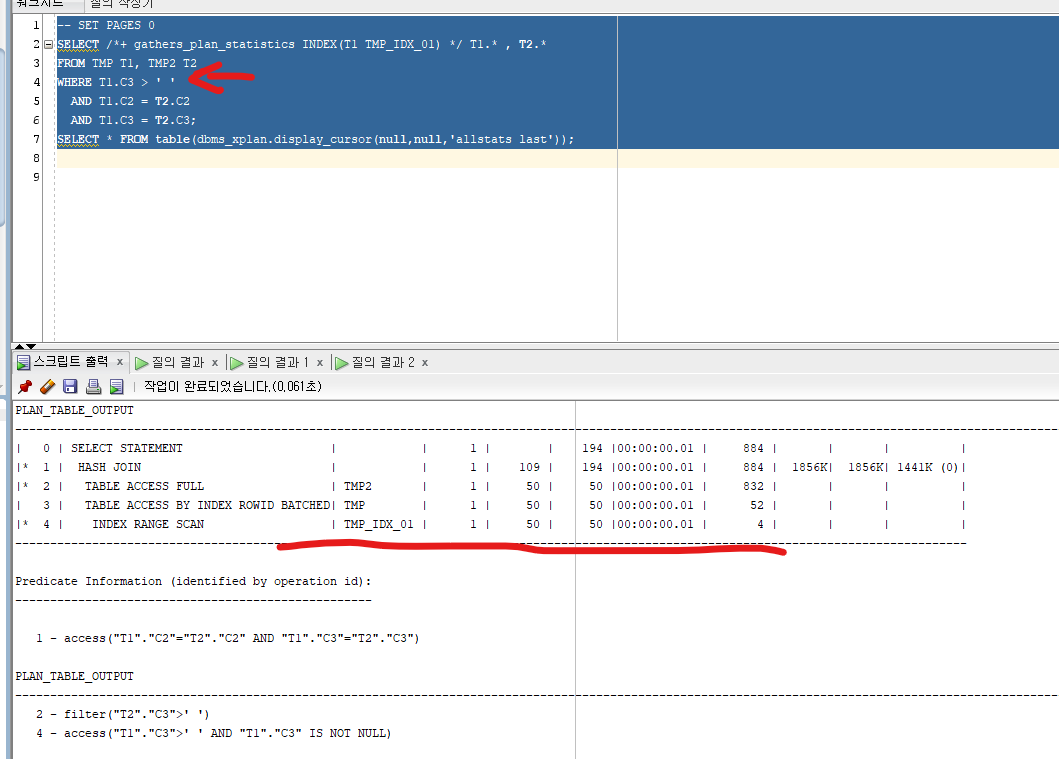
수행 방식에 따른 조인의 종류
NESTED LOOP JOIN : 드라이빙 테이블(선행)로부터 where절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후 이 값들을 가지고 조인 대상 테이블을 반복적으로 검색하면서 조인 조건을 만족하는 최종 결과값을 얻어 내는 방식 (driving table 선택에따라 performence 달라짐)
HINT : /''+use_nl(table) ''/
SORT MERGE JOIN : 조인하고자 하는 두 테이블의 행들을 조인 조건 컬럼 기준으로 정렬한 후 Merge하여 매치되는 결과를 추출
HINT : /''+ USE_MERGE(TABLE) ''/
HASH JOIN : 둘 중 작은 집합을 읽어 해시 영역에 해시 테이블을 생성하고, 반대쪽 큰 집합을 읽어 해시 테이블을 탐색하면서 조인 ( DW성 데이터 조회시 사용 )
CUSTOMER 테이블을 읽어 해시테이블로 만든 뒤 ORDERS 테이블과 조인
MERGE JOIN 사용대비 6배정도 COST 차이가 남
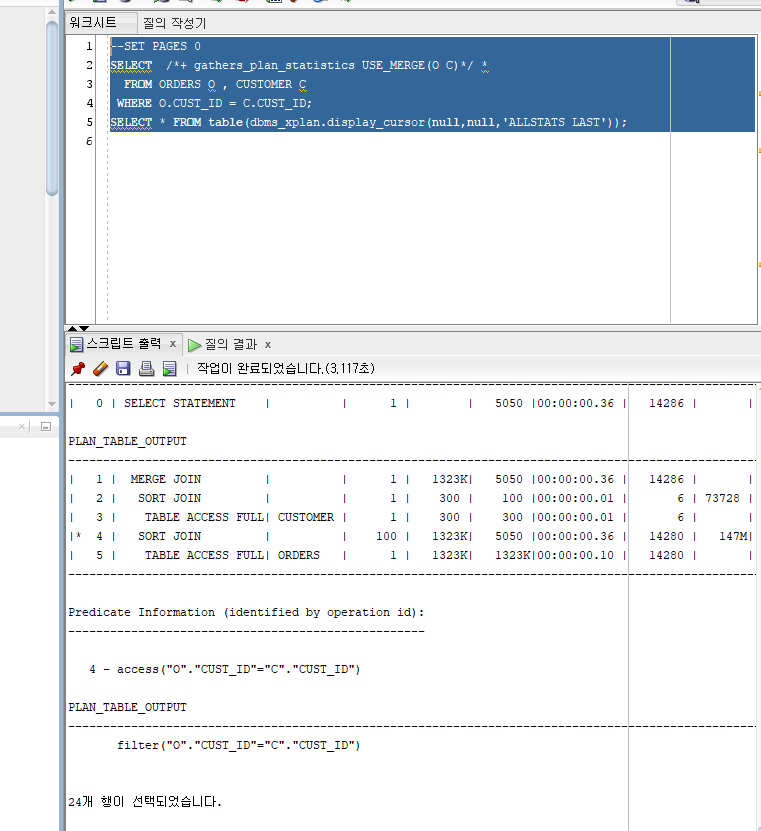
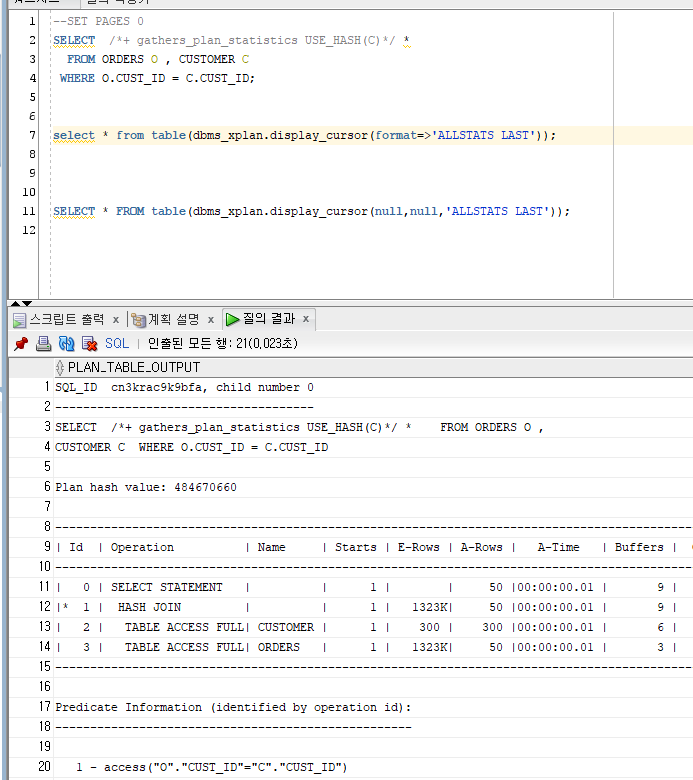
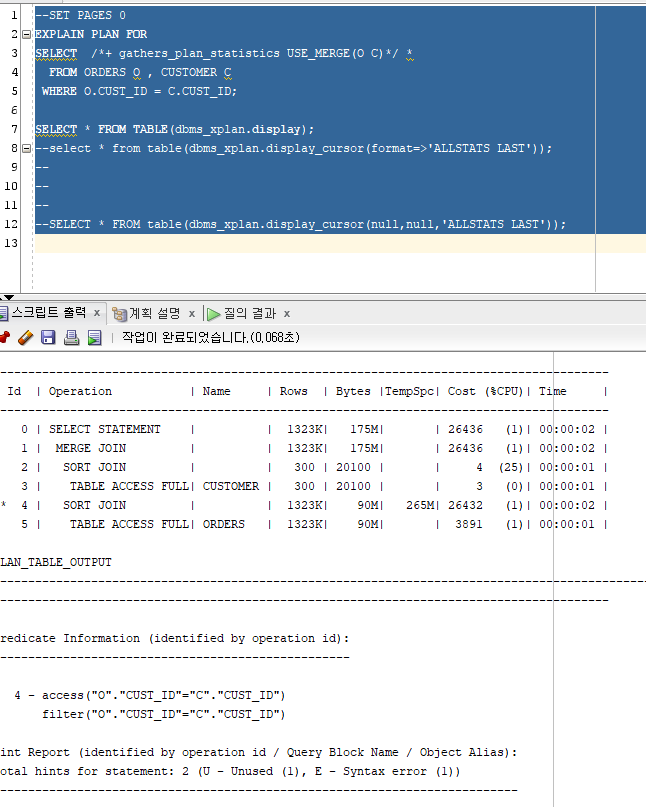
HINT : /''+ USE_HASH(TABLE) ''/
driving table = 선행 테이블 = outer table = build input
driven table = 후행 테이블 = inner table = probe input
