
Decsion Tree (Classfication)
시작은?
- 분류를 하는 근거가 필요하다!
- 정량적 수치를 제시해보자
e.g)
- iris dataset
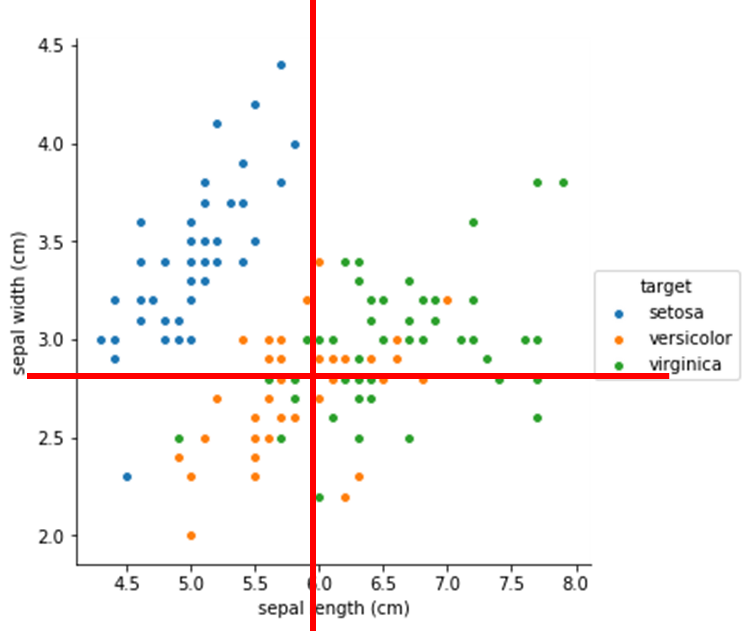
- setosa 를 저렇게 구분하면 최선인데 그렇게 보이는 근거가 필요!
Split Criterion
- 정보획득
- 어떤 데이터 영역의 순도가 증가는 불확실성이 감소
- 어떤 사건이 얼마만큼의 정보를 줄 수 있는가를 수치화
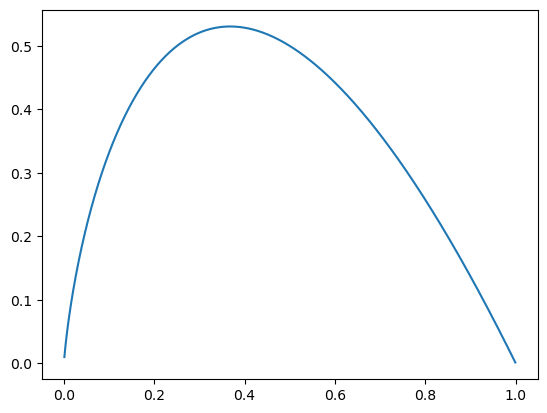
- 1 또는 0 은 명확한 사실
- Entropy
- 얼마만큼의 정보를 담고있는가?
- 무질서, 불확실성을 정령화 한 표현
- Entropy가 최소가 되는 방향으로 분류해 나각는 것이 최적의 방법
- decision tree를 시각화 하면 노드에 entropy 확인 가능
- Gini index
- Entropy의 계산량이 많아서 계산량이 적은 지니계수를 사용
Scikit-learn
- Basic Code
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
X = iris.data[:,2:]
y = iris.target
clf.fit(X, y)
from sklearn.metrics import accuracy_score
y_pred_tr = clf.predict(X)
accuracy_score(y, y_pred_tr)- Tree Plot
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_clf);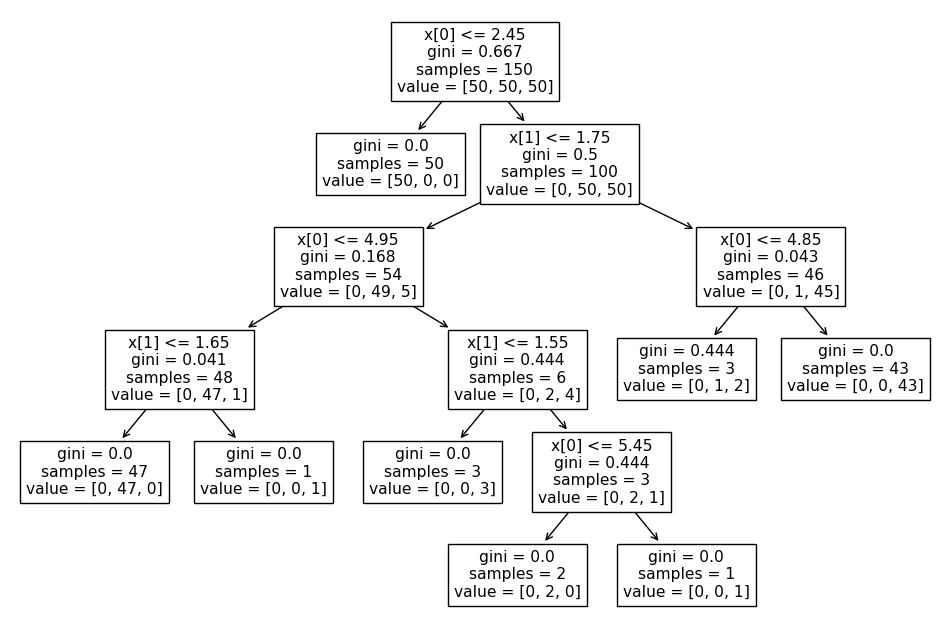
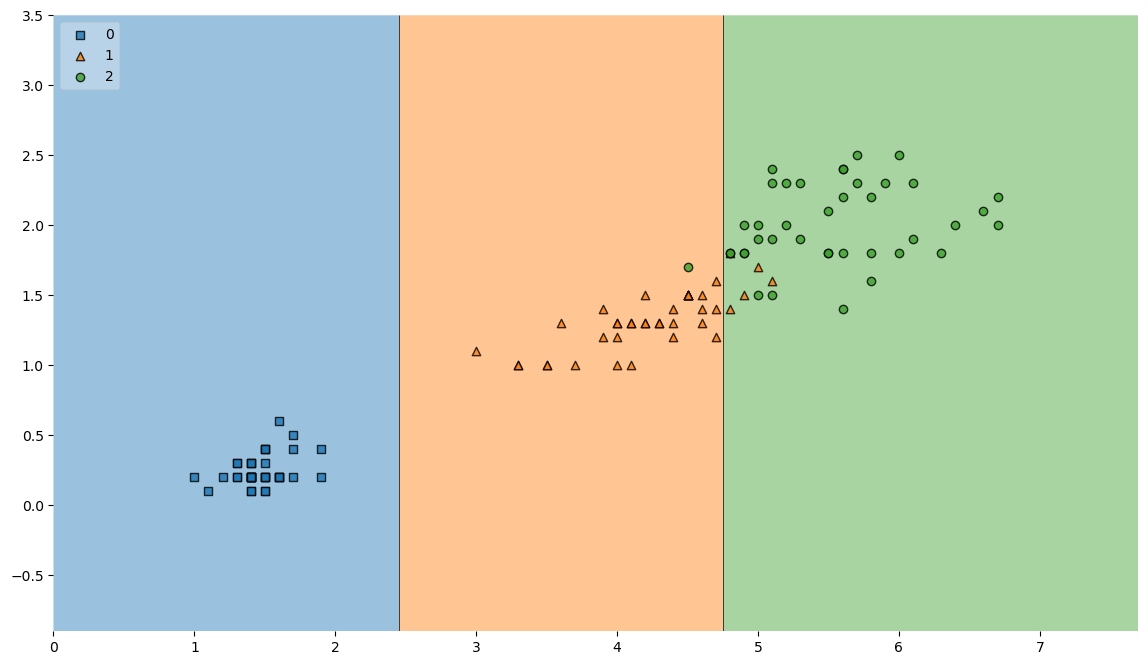
- 분류 기준 시각화
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y = iris.target, clf=iris_clf, legend=2)
plt.show()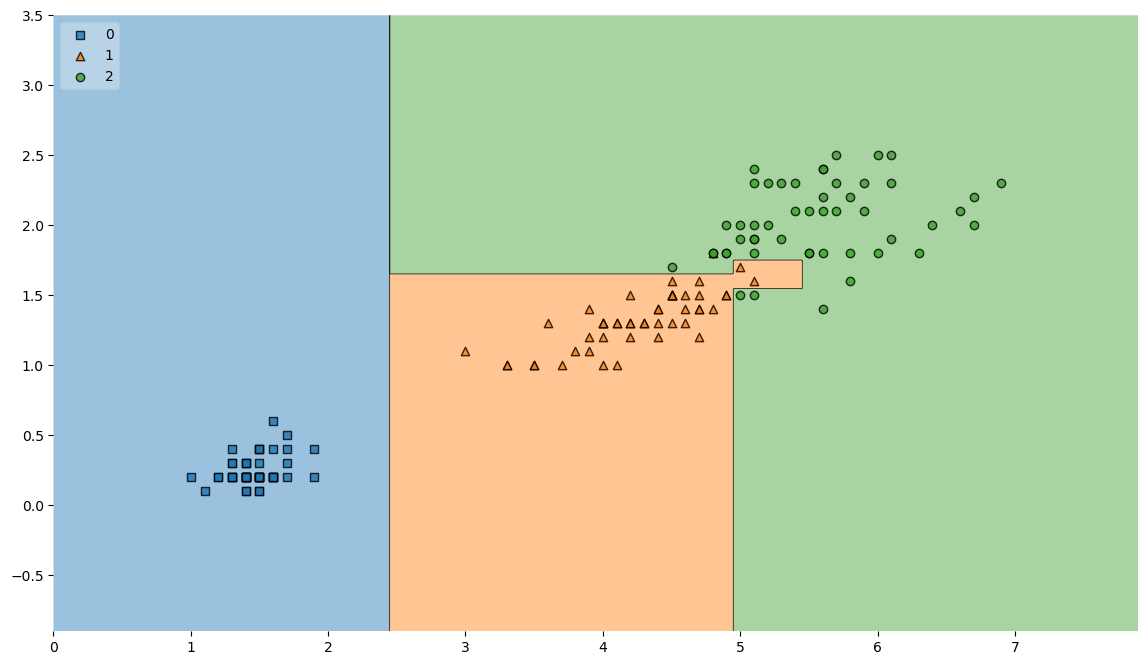
- 복잡하다!
- Accuracy가 과적합의 위험이 있다
- 일반화X
- 데이터를 분리하여 테스트 하자!
데이터 분리
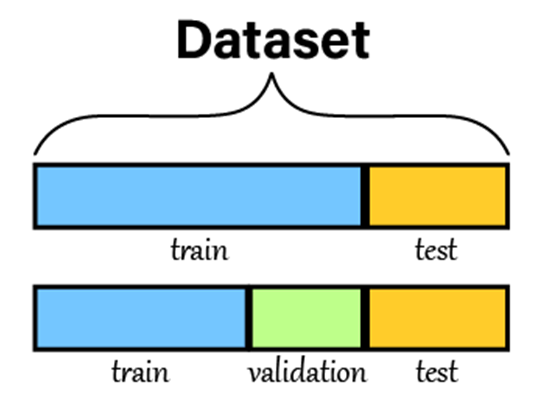
-
Train 데이터와 Test 데이터를 분리
-
Validation 개념은 뒤에서!
-
Scikit-learn Module
from sklearn.model_selection import train_test_split
feature = iris.data[:,2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(feature, labels,
test_size=0.2,
random_state=13,
stratify=labels,
)- stratify : label의 갯수를 맞춰준다
- 결과
- 일반화된 형태
피쳐 중요도
iris_clf_model = dict(zip(iris.feature_names, clf.feature_importances_))
iris_clf_model
>>>
{'sepal length (cm)': 0.0,
'sepal width (cm)': 0.033898305084745756,
'petal length (cm)': 0.3958012326656394,
'petal width (cm)': 0.5703004622496148}
Easy day!