
Ensemble
앙상블 이란?
- 여러개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
- 다양한 분류기의 사용하므로써 신뢰성 높은 예측 값을 얻을 수 있다
앙상블 학습 유형
- voting
-
여러 개의 분류 모형의 결과를 대상으로 투표를 통해 최종 클래스 라벨을 정하는 방법
-
다수결 투표
- 높은 득표수를 보이는 클래스로 예측 -
과반수 투표
- 다수결이 아닌 절반 이상의 분류기의 표를보이는 클래스로 예측
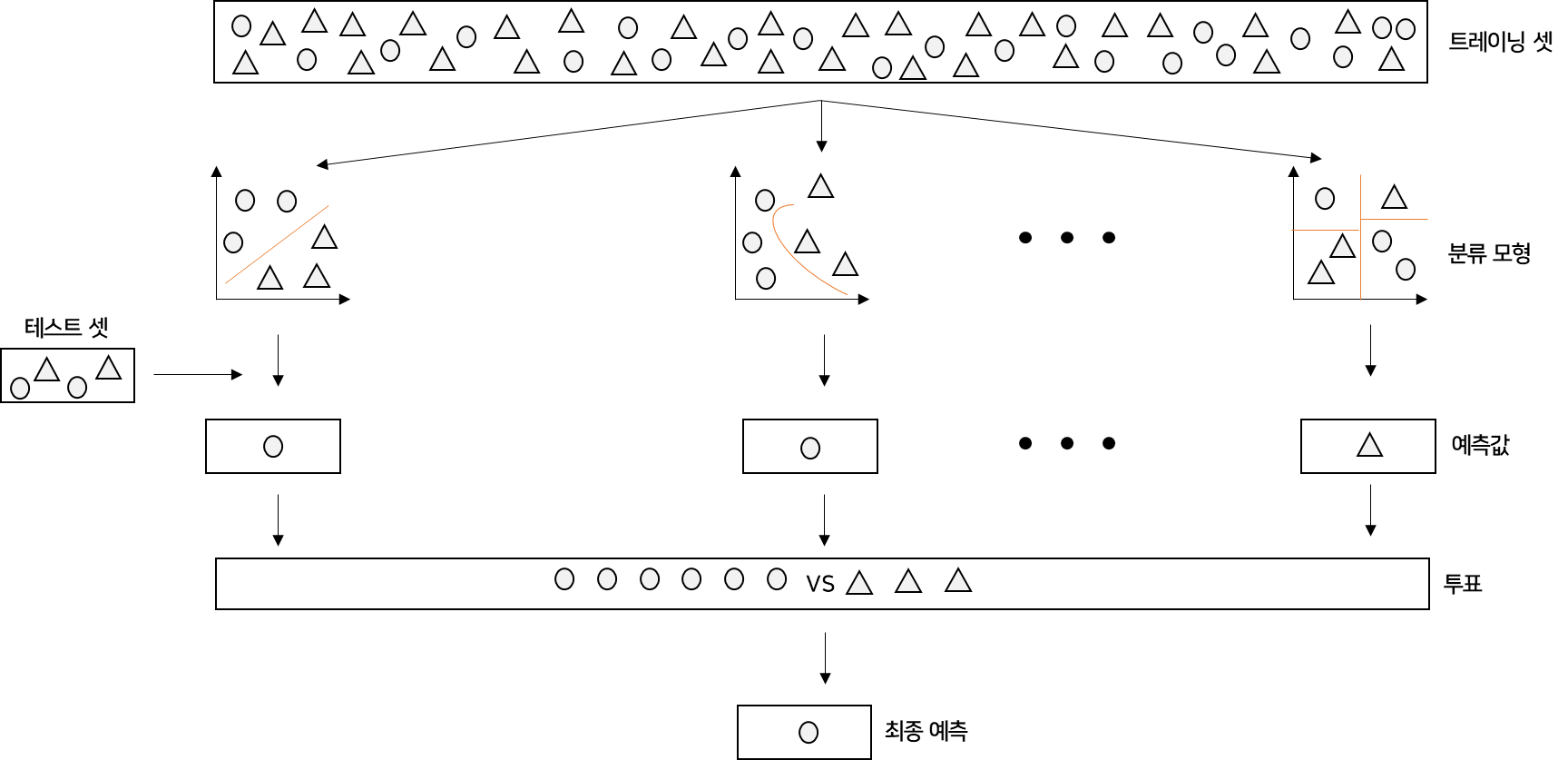
- 개별 모형보다 성능이 뛰어난 이유
-
이진 분류 문제를 푼다고 했을 때, 동일한 에러율 를 가진 개의 분류기를 가정해보자
-
모든 분류기의 오차는 서로 독립적이고, 서로 상관관계 가 없다고 가정한다.
-
이런 가정 아래 개의 분류기로 구성된 앙상블 모형의 오차 확률은 따르며 아래의 식과 같다
-
분류기가 틀리려면 X는 K보다 크거나 같아야 한다.
-
예를들어 9개의 분류기로 구성된 앙상블 분류기가 있다고 할때, 최소 5개의 분류기의 예측이 틀려야 한다.
-
각 분류기의 에러율이 0.3이라고 하면 아래와 같다
-
개별 분류기의 에러율 0.3보다 작은 0.09가 되었다.
- Bagging
- 개별 분류기들의 분류 결과를 종합하여 최종 분기의 성능을 향상하는 방법
- 오리지널 트레이닝 데이터 셋이서 부트스트랩 샘플을 뽑아서 학습
- 부트스트랩이란 중복을 허용한 랜덤 샘플 방법
- 개별 모형의 결과값을 모아 다수결 투표를 통해 최종 예측

- Randomforest
- 대표적인 배깅 방법
- 배깅에 사용하는 개별 분류기들은 모두 같은 머신러닝 알고리즘
HAR, Himan Activity Recognition
- 데이터 불러오기
- 생략
- 의사결정 나무
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
clf = DecisionTreeClassifier(random_state=13, max_depth=4)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
accuracy_score(y_test, pred)
>>>
0.8096369189005769- GridSearchCV
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20,24]
}
grid_cv = GridSearchCV(clf, param_grid=params, scoring='accuracy',
cv = 5 , return_train_score=True)
grid_cv.fit(X_train, y_train)
# 여기서는 scoring 을 사용- best_score 확인
grid_cv.best_score_
>>>
0.8543335321892183- best_param 확인
grid_cv.best_params_
>>>
{'max_depth': 8}- max_depth 별로 표로 성능 정리
cv_result_df = pd.DataFrame(grid_cv.cv_results_)
cv_result_df[['param_max_depth', 'mean_test_score','mean_train_score']]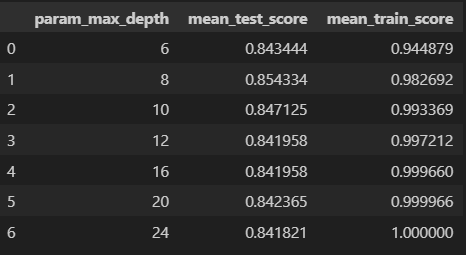
- test set 적용
pred = grid_cv.predict(X_test)
accuracy_score(y_test, pred1)
>>>
0.8743- 수업에서는 for문을 사용하여 한번더 fit 해주었으나 gird_cv에 이미 담겨 있기 때문에 그냥 predict 해주었다.
- 랜덤포레스트 적용
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6,8,10],
'n_estimators' : [50,100,200],
'min_samples_leaf' : [8,12],
'min_samples_split' : [8,12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params ,cv = 2 , n_jobs=-1)
grid_cv.fit(X_train, y_train)- 결과 가져오기
cv_result_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_result_df[target_col].sort_values('rank_test_score').head()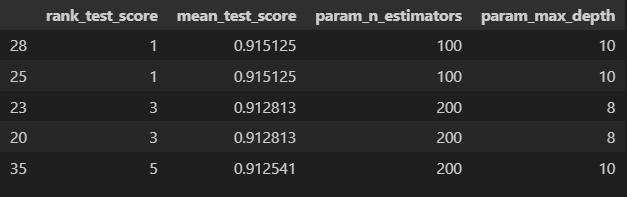
- test set 적용
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
pred1 = rf_clf_best.predict(X_test)
accuracy_score(y_test, pred1)
>>>
0.9205972175093315- feature importance
best_col_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_col_values, index=X_train.columns)
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols
# feature_importances_ 를 먹여서 들고와야 한다- 시각화
import seaborn as sns
plt.figure(figsize=(8,8))
sns.barplot(x=top20_cols , y=top20_cols.index)
plt.show()
# seaborn 에서도 barh 그리기 가능!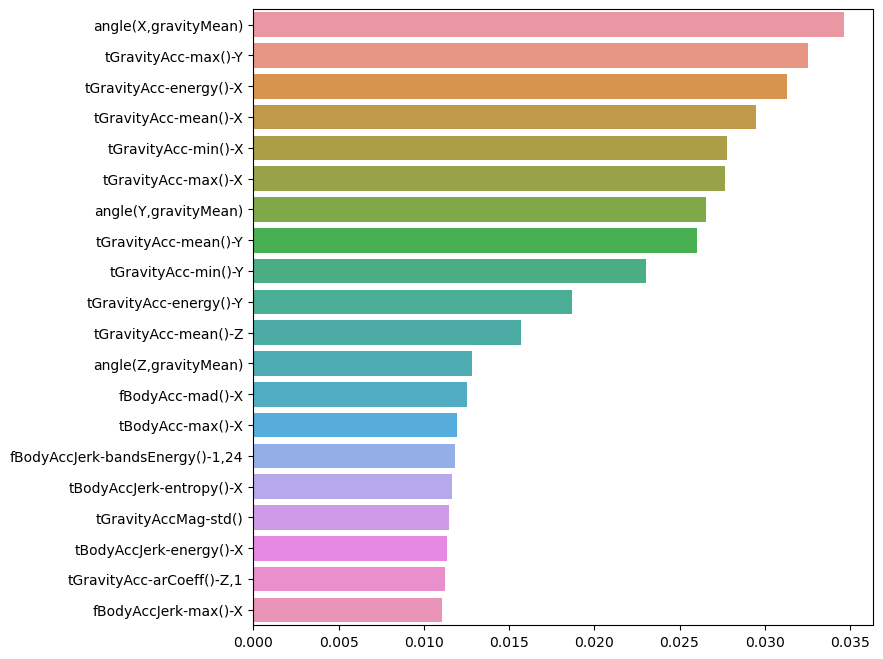
- 중요특성 20개 가지고 성능 확인
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
y_train.values.reshape(-1)
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train) # 왜 바꿔줬찌..?
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)
>>>
0.8177807940278249- 성능은 조금 떨어졌지만 속도는 빠를것Boosting
- 개별 학습기들이 서로 독립이 아닌 경우
- 분류하기 어려운 데이터에 집중한다
- 데이터에 가중치를 할당
- 분류가 잘 된 데이터는 가중치를 감소하고, 분류가 잘못된 데이터에는 가중치를 증가
- 약한 학습기 여러 개를 모아 하나의 강한 학습기를 만드는 방법
- voting 과 bagging은 병렬적으로 수행할 수 있지만 boosting은 그럴수 없다
- Adaboost 가 가장 기본
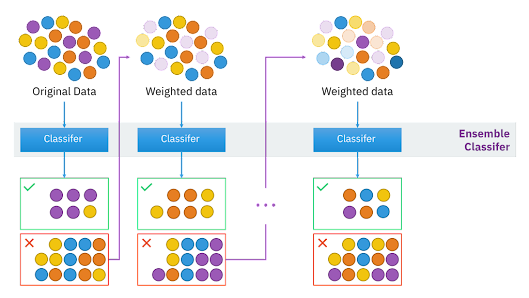
- 부스팅 기법
- GBMGradientBoosting Machine
- AdaBoost 기법과 비슷하지만, 가중치 업데이트를할 때 경사 하강법을 사용 - XGBoost
- GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐 - LightGBM
- XGBoost 보다 빠른 속도를 가짐

Easy day!