
Hyperparameter Tuning
교차검증
- 교차검증 이란?
- 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법
- 이터를 학습용/평가용 데이터 세트로 여러 번 나눈 것의 평균적인 성능을 계산하면, 한 번 나누어서 학습하는 것에 비해 일반화된 성능을 얻을 수 있기 때문
- 기존대비 안정적이고 뛰어난 통계적 평가
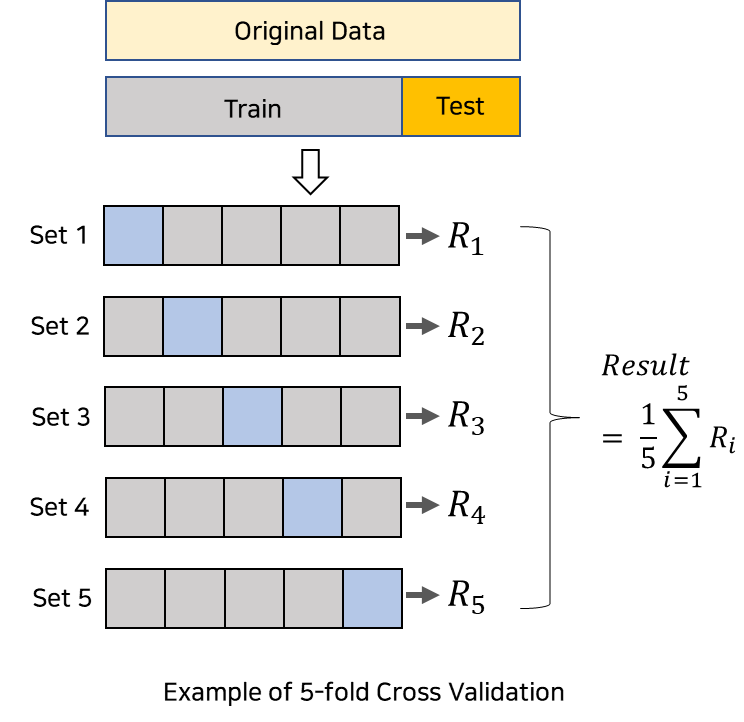
- k-fold cross validation
-
데이터를 k개로 분할한 뒤, k-1개를 학습용 데이터 세트로, 1개를 평가용 데이터 세트로 사용
구현하기
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1,2], [3,4] ,[1,2], [3,4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
print(kf.get_n_splits(X))
print(kf)
for train_idx, test_idx in kf.split(X):
print('--- idx')
print(train_idx, test_idx)
# 첫 번째 : 2,3 을 train | 0,1 을 테스트
# 두 번째 : 0,1 을 train | 2,3 을 테스트(validation)
print('--- train data')
print(X[train_idx])
print('--- val data')
print(X[test_idx])
>>>
--- idx
[2 3] [0 1]
--- train data
[[1 2]
[3 4]]
--- val data
[[1 2]
[3 4]]
--- idx
[0 1] [2 3]
--- train data
[[1 2]
[3 4]]
--- val data
[[1 2]
[3 4]]- 첫 번째 : 2,3 을 train | 0,1 을 테스트(validation)
- 두 번째 : 0,1 을 train | 2,3 을 테스트(validation)
- 와인 맛 분류 데이터
- 데이터 불러오기 생략
from sklearn.model_selection import KFold
kFold = KFold(n_splits= 5)
clf_cv = DecisionTreeClassifier(max_depth=2, random_state=13)- Train, Test 데이터 개수 확인
for train_idx, test_idx in kFold.split(X):
print(len(train_idx), len(test_idx))
>>>
5197 1300
5197 1300
5198 1299
5198 1299
5198 1299- idx에는 인덱스가 들어가 있다.
- iloc로 인덱스를 넣어주면 X, y에 데이터를 지정하여 학습하고 각각의 Set의 score를 구해줄 수 있다
cv_accuracy = []
# train_idx : index 값이 들어 있따
for train_idx, test_idx in kFold.split(X):
X_train, X_test = X.iloc[train_idx] , X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx] , y.iloc[test_idx]
clf_cv.fit(X_train, y_train)
cv_pred = clf_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, cv_pred))
cv_accuracy
>>>
[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]- 분산이 크지 않다면 평균으로 대표값으로 정한다
np.mean(cv_accuracy)
>>>
0.709578255462782- StratifiedKFold
- Split 에서 Stratified를 사용하지 않고 K-fold에서 사용한다
from sklearn.model_selection import StratifiedKFold
skFold = StratifiedKFold(n_splits= 5)
clf_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
# train_idx : index 값이 들어 있따
# stratified 는 y를 넣어줘 기준을 주어야 한다
for train_idx, test_idx in skFold.split(X,y):
X_train, X_test = X.iloc[train_idx] , X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx] , y.iloc[test_idx]
clf_cv.fit(X_train, y_train)
cv_pred = clf_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, cv_pred))
cv_accuracy
>>>
[0.5523076923076923,
0.6884615384615385,
0.7143956889915319,
0.7321016166281755,
0.7567359507313318]- 대표값 출력
np.mean(cv_accuracy)
>>>
0.6888004974240539- Train Score 와 함께(Test set)
# train score 와 함꼐 보려면?
from sklearn.model_selection import cross_validate
cross_validate(clf_cv, X, y , scoring=None, cv =skFold, return_train_score=True)
>>>
{'fit_time': array([0.01745868, 0.01506758, 0.01425695, 0.0142417 , 0.01510668]),
'score_time': array([0.00369287, 0.00138402, 0.00099945, 0.00201011, 0.00200129]),
'test_score': array([0.50076923, 0.62615385, 0.69745958, 0.7582756 , 0.74903772]),
'train_score': array([0.78795459, 0.78045026, 0.77568295, 0.76356291, 0.76279338])}하이퍼파라미터 튜닝
- 하이퍼파라미터 튜닝이란?
- 모델의 성능을 확보하기 위해 조절하는 설정값
- 튜닝 대상?
- 많다..!!
- 반복문을 통해서 테스트 가능
- GridSearchCV 사용하기
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2, 4, 7, 10]}
clf = DecisionTreeClassifier(max_depth=2 , random_state= 13)
gridSearch = GridSearchCV(estimator=clf, param_grid=params, cv=5)
gridSearch.fit(X,y)- GridSearchCV 변수
estimator : 분류기, 여기선 clf
param_grid : 파라미터
train_test_split을 사용하지 않아도 됨
- GridSearchCV 결과 보기
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridSearch.cv_results_)
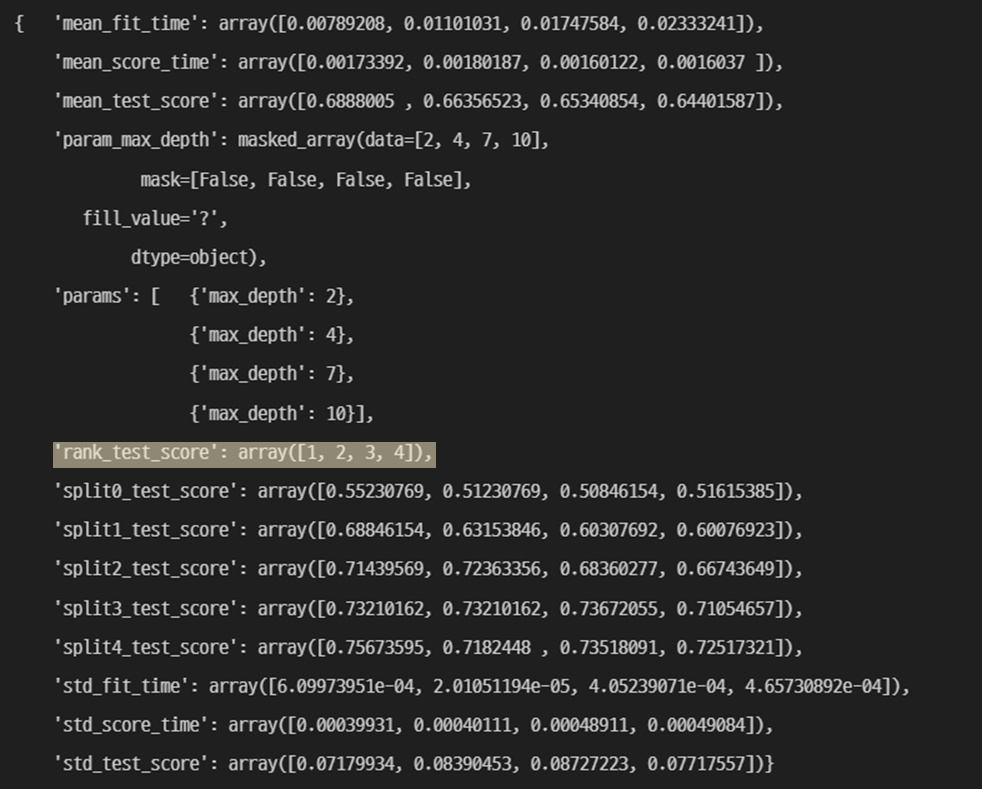
- Rank_test_score 로 가장 성능이 좋은 파라미터값 확인 가능
- best 가져오기
- best 모델기 가져오기
gridSearch.best_estimator_
- best score 가져오기
gridSearch.best_score_
>>>
0.6888004974240539- best 파라미터 가져오기
gridSearch.best_params_
>>>
{'max_depth': 2}- Pipeline 사용하기
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth' : [2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid = param_grid , cv = 5)
GridSearch.fit(X,y)- 분류기에 pipeline을 지정해주면 끝!
- 데이터프레임으로 결과 정리하기
score_df = pd.DataFrame(GridSearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]
# 원하는 컬럼만 가져왔따!
Easy day!