
Preprocessing Module
Label Encoder
- label encoder 란?
- scaler 가져오기
from sklearn.preprocessing import LabelEncoder- 문자 데이터를 숫자 카테고리한 데이터로 변환
- 사용법
df = pd.DataFrame({
'A' : ['a','b','c','a','b'],
'B' : [1,2,3,1,0]
})
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])- 바꾸고 싶은 컬럼을 fit 시킨다
- 어떤 컬럼인지 확인하고 싶다면?
le.classes_
>>>
array(['a', 'b', 'c'], dtype=object)- DataFrame에 새로운 컬럼을 지정해주고 transform 시키면 끝
df['le_A'] = le.transform(df['A'])- fit > transform 이 귀찮으면 한번에 가능
le.fit_transform(df['A'])- 역변환
le.inverse_transform(df['le_A'])- inverse_transform을 사용하면 역변환 가능
- 바꿔준 컬럼을 선택해주어야 한다
Min-Max Scaling
- min-max scaling 이란?
- scaler 가져오기
from sklearn.preprocessing import MinMaxScaler- Fomula
- 사용법
df = pd.DataFrame({
'A' : [10,20,-10,0,25],
'B' : [1,2,3,1,0]
})
mms = MinMaxScaler()
mms.fit(df)
df_mms = mms.transform(df)- fit > transform
- 역시 한번에 가능
mms.fit_transform(df)- 역변환
- 역변환 가능
mms.inverse_transform(df_mms)Standard Scaling
- Standard scaling 이란?
- scaler 가져오기
from sklearn.preprocessing import StandardScaler- Fomula
- 사용법
df = pd.DataFrame({
'A' : [10,20,-10,0,25],
'B' : [1,2,3,1,0]
})
ss = StandardScaler()
ss.fit(df)
df_ss = ss.transform(df)- fit > transform
- 역시 한번에 가능
ss.fit_transform(df)역변환
- 생략
robust scaling
- robust scaling 이란?
- scaler 가져오기
from sklearn.preprocessing import RobustScaler- Fomula
- 사용법
df = pd.DataFrame({
'A' : [-0.1, 0, 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5]
})
rs.fit_transform(df)- 전체 비교
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style = 'whitegrid')
plt.figure(figsize=(16,6))
sns.boxplot(data=df_scaler, orient='h');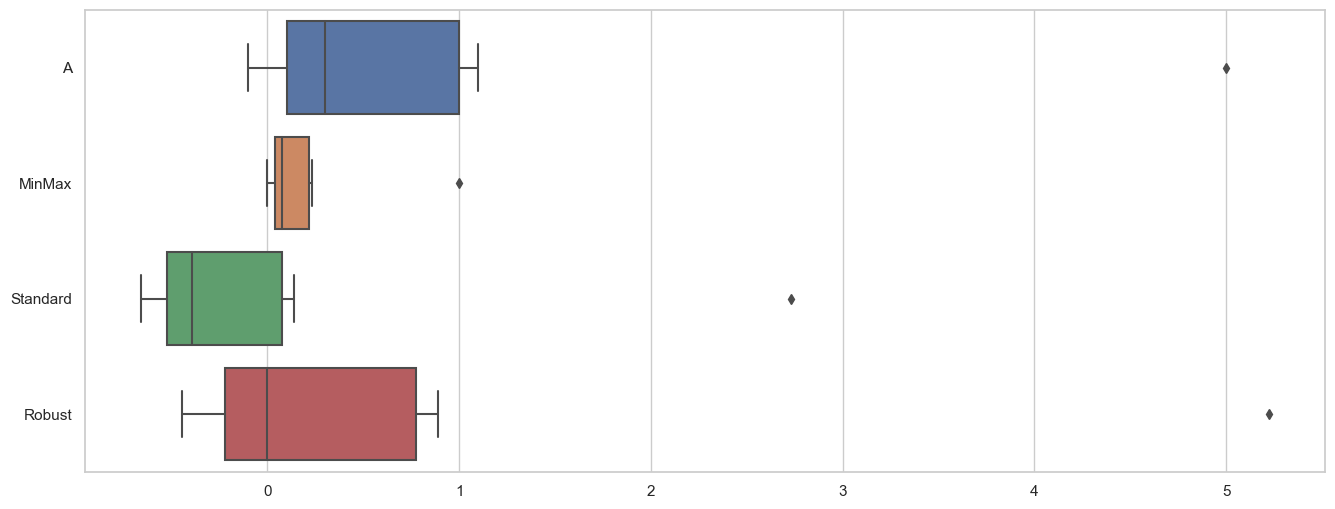
- 결론
- MinMax scaler : outlier에 취약하다
- Standard Scaler : outlier 때문에 평균과 표준편차의 영양을 받는다
- Robust scaler : 길이를 1로 만든다 outlier는 outlier 그대로 두고 나머지 값변환에 크게 영향을 주지 않는다

Easy day!