
Decsion Tree (Classfication)
데이터 전처리
- 데이터 합치기
red_wine['color'] = 1
white_wine['color'] = 0
# red : 1 ,white : 0
wine = pd.concat([red_wine,white_wine])- redwine 데이터와 whitewine 데이터 합치기기
- quality histogram
import plotly.express as px
fig = px.histogram(wine, x='quality')
fig.show()- quality 별 히스토그램 작성
- 와인종류별 퀄리티별 히스토그램
fig = px.histogram(wine , x='quality', color='color')
fig.show()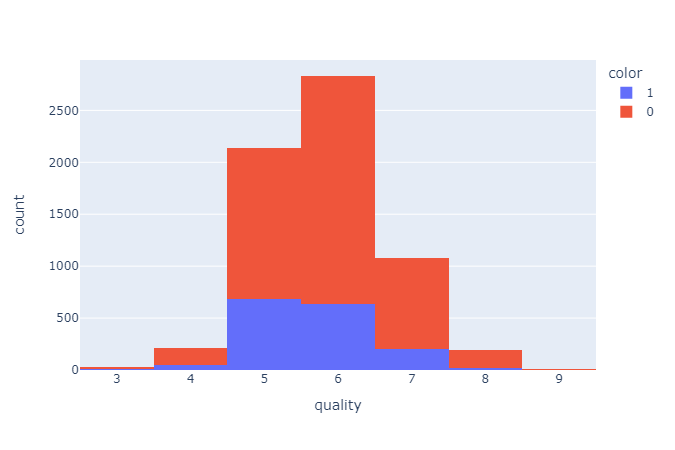
- 하나의 컬럼에 여러개의 value를 가지고 있다면 color로 그래프를 다르게 그릴 수 있다
레드 와인/ 화이트 와인 분류기
- 데이터 split
X = wine.drop(['color'], axis=1)
y = wine['color']
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test , y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state = 13)
- Train, Test 구경하기
import plotly.graph_objects as go
fig =go.Figure()
fig.add_trace(go.Histogram(x=X_train['quality'], name ='Train'))
fig.add_trace(go.Histogram(x=X_test['quality'], name ='Test'))
fig.update_layout(barmode='overlay')
fig.update_traces(opacity=0.75)
fig.show()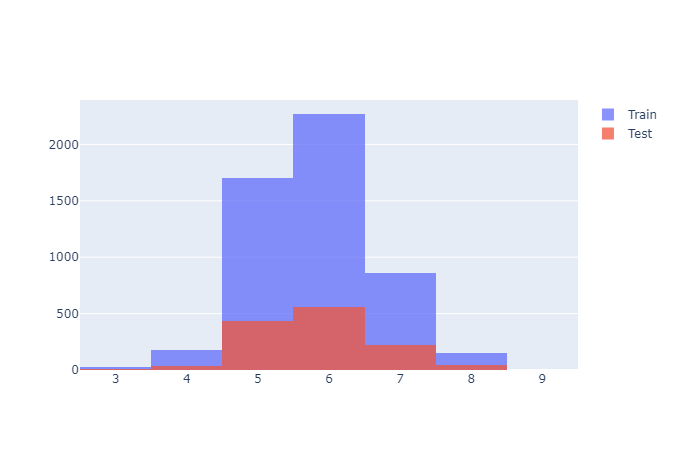
-
update_layout : 그래프를 어떻게 나타낼 것인가 Stack, overlay, 등등..
(참고 : https://plotly.com/python/reference/layout/) -
Train 과 Test 셋에 비슷한 비율로 데이터가 분리되어 있다
- 학습 및 평가
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=2 , random_state=13)
clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print('Train ACC : ', accuracy_score(y_train,y_pred_tr))
print('Test ACC : ', accuracy_score(y_test,y_pred_test))
>>>
Train ACC : 0.9553588608812776
Test ACC : 0.9569230769230769데이터 전처기
- 데이터 들여다 보기
fig = go.Figure()
fig.add_trace(go.Box(y=X['fixed acidity'], name ='fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name ='chlorides'))
fig.add_trace(go.Box(y=X['quality'], name ='quality'))
fig.show()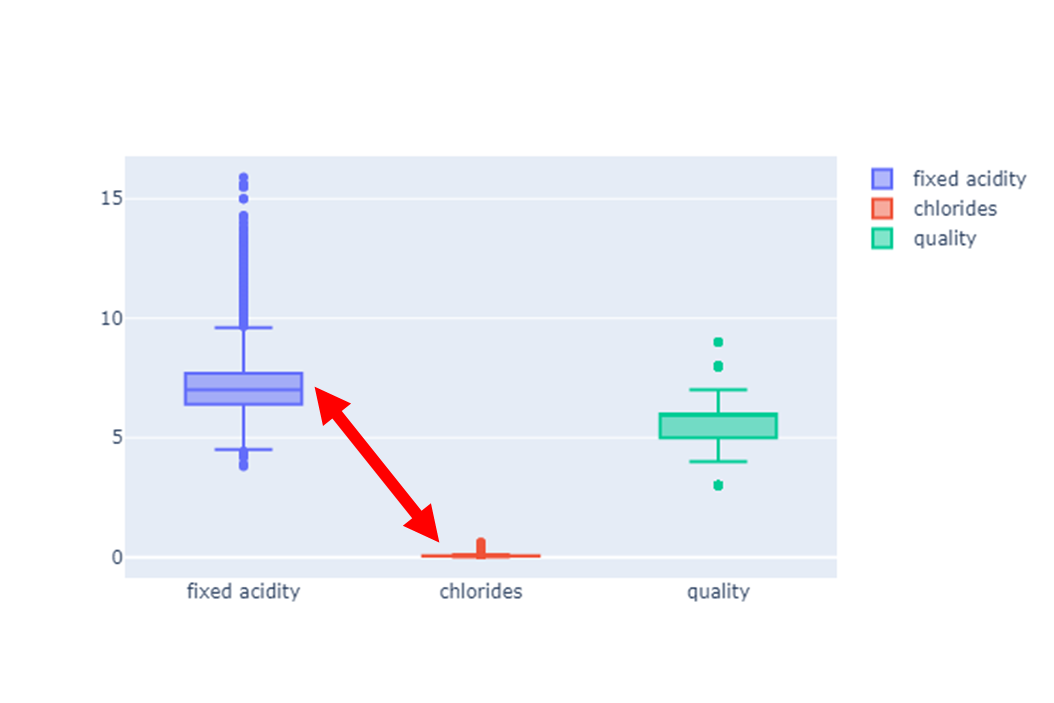
- 차이가 너무 크다
- 특성의 편향 문제는 최적의 모델을 찾는데 방해가 될 수 있다
- 전처리를 통해 줄여보자
- Decision Tree는 크게 의미 없긴하다
- 어떤 전처리를 사용할 것인지는 해봐야 안다!
- 데이터 전처리
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mms = MinMaxScaler()
ss = StandardScaler()
X_ss = ss.fit_transform(X)
X_mms = mms.fit_transform(X)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)
- StandardScaler , Min-MaxScaler 모두 해본다
- 학습 및 평가
- Standard Scaler
X_train, X_test , y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2,
random_state = 13)
clf = DecisionTreeClassifier(max_depth=2 , random_state=13)
clf.fit(X_train, y_train)
y_pred_tr = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print('Train ACC : ', accuracy_score(y_train,y_pred_tr))
print('Test ACC : ', accuracy_score(y_test,y_pred_test))
>>>
Train ACC : 0.9553588608812776
Test ACC : 0.9569230769230769- Min-Max Scaler
X_train, X_test , y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2,
random_state = 13)
clf = DecisionTreeClassifier(max_depth=2 , random_state=13)
clf.fit(X_train, y_train)
y_pred_tr = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print('Train ACC : ', accuracy_score(y_train,y_pred_tr))
print('Test ACC : ', accuracy_score(y_test,y_pred_test))
>>>
Train ACC : 0.9553588608812776
Test ACC : 0.9569230769230769- 중요 특성 보기
dict(zip(X_train.columns, clf.feature_importances_))
>>>
{'fixed acidity': 0.0,
'volatile acidity': 0.0,
'citric acid': 0.0,
'residual sugar': 0.0,
'chlorides': 0.24230360549660776,
'free sulfur dioxide': 0.0,
'total sulfur dioxide': 0.7576963945033922,
'density': 0.0,
'pH': 0.0,
'sulphates': 0.0,
'alcohol': 0.0,
'quality': 0.0}와인 맛에 대한 분류 - 이진 분류
- 이진화 (quality 컬럼 제외)
wine['taste'] = [1 if grade > 5 else 0 for grade in wine['quality']]- 학습 및 평과
X = wine.drop(['taste','quality'], axis=1)
y = wine['taste']
X_train, X_test ,y_train, y_test = train_test_split(X,y, test_size = 0.2,
random_state = 13)
clf = DecisionTreeClassifier(max_depth=2, random_state=13)
clf.fit(X_train, y_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print(f'Train ACC : {accuracy_score(y_train, y_pred_train)}')
print(f'test ACC : {accuracy_score(y_test, y_pred_test)}')
>>>
Train ACC : 0.7294593034442948
test ACC : 0.7161538461538461- Tree 시각화
import matplotlib.pyplot as plt
import sklearn.tree as tree
plt.figure(figsize=(12,8))
tree.plot_tree(clf, feature_names=X.columns,
rounded=True,
filled=True);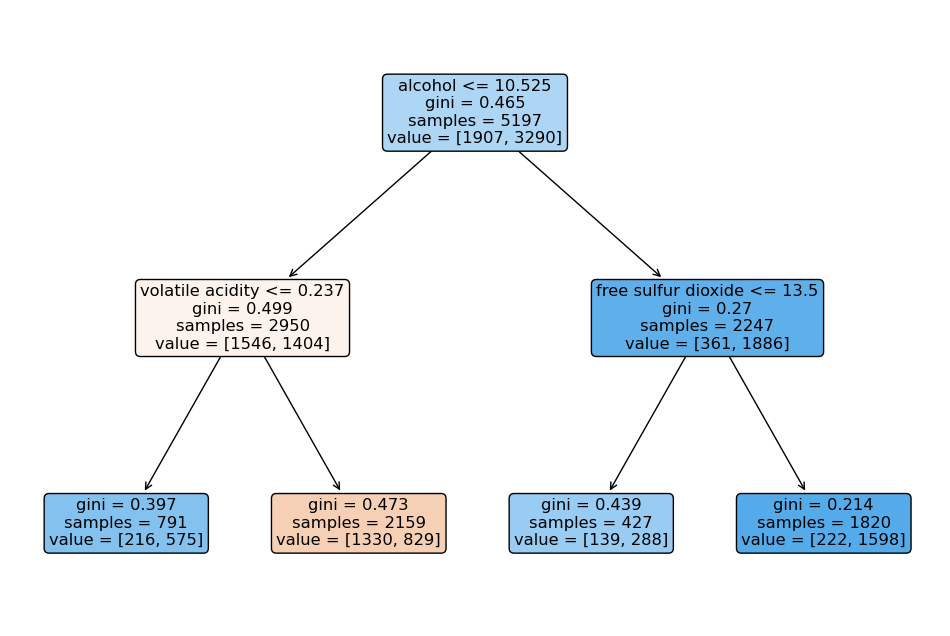
- feature importacne 에 대해서는 좀더 알아보자! ( https://soohee410.github.io/iml_tree_importance )

Easy day!