
sklearn.preprocessing.scale
: standardize a dataset along any axis.
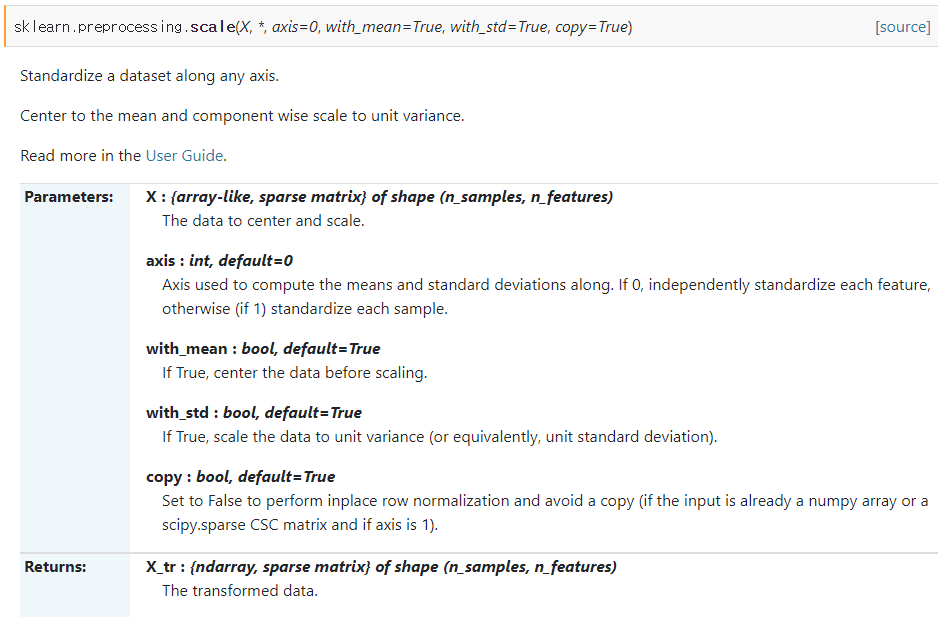
from sklearn.preprocessing import scale v = np.array([[1,2],[3,4]]) b = scale(v,axis=0) # 열별 scaling >> array([[-1., -1.], [1. , 1.]])
np.mean(v, axis=0) # array([2., 3.]) np.std(v, axis=0) # array([1., 1.]) (v-np.mean(v,axis=0))/np.std(v, axis=0) >> array([[-1., -1.], [1., 1.]])
scale()은 axis값에 따라 scaling하는 것을 알 수 있다.
위의 경우 axis=0인 scale함수와 실제로 열별로 평균과 표준편차를 계산해 스케일링 한 값이랑 일치한다.
데이터프레임 column별 스케일링이 필요할 때 사용할 수 있을 것 같다.
vs.
sklearn.preprocessing.StandardScaler
: Standardize features by removing the mean and scaling to unit variance.
from sklearn.preprocessing import StandardScaler v = np.array([[1,2],[3,4]]) # StandardScaler scaler = StandardScaler() scaler.fit(v) scaler.transform(v) >> array([[-1., -1.], [1., 1.]])
scaler(axis=0)인 경우와 StandardScaler()는 같은 결과를 낸다. 둘 다 똑같이 column별로 표준화해주는 역할을 한다.
다만, scaler()는 axis=1로 설정하므로써 row별로 표준화한 것도 가능하다. 물론 나의 짧은 경험으론,, 잘 쓰이진 않을 것 같다!
reference : https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html#sklearn.preprocessing.StandardScaler
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.scale.html#sklearn.preprocessing.scale
