1D with PyTorch
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6.]) t.size() # 1차원 텐서, 원소는 7개 > torch.Size([7]) t[2:5] # 슬라이싱 > tensor([2., 3., 4.])
2D with PyTorch
t = torch.FloatTensor([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.], [10., 11., 12.] ]) t.size() > torch.Size([4,3]) t[:,1] > tensor([ 2., 5., 8., 11.])
행렬곱셈 .matmul() vs 원소 별 곱셈 .mul()
차원별 계산 : dim = 0, 1, -1
- dim은 차원 축을 이야기한다.
2차원에서 dim=0은 아래방향(행방향)쪽이고, dim=1은 가로방향(열방향)쪽이다.
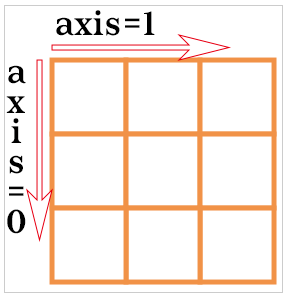
t = torch.FloatTensor([[1, 2], [3, 4]]) > tensor([[1., 2.], [3., 4.]]) t.mean(dim=0) # 행별 연산 > tensor([2., 3.]) t.mean(dim=1) # 열별 연산 > tensor([1.5000, 3.5000]) t.mean(dim=-1) # 마지막 차원끼리 연산 (여기서는 열별 연산에 해당) > tensor([1.5000, 3.5000])
최대(Max) vs 아그맥스(ArgMax)
- 최대(Max) : 원소의 최대값을 리턴
- 아그맥스(ArgMax) : 최대값을 가진 인덱스를 리턴
t = torch.FloatTensor([[1, 2], [3, 4]]) > tensor([[1., 2.], [3., 4.]]) print('Max: ', t.max(dim=0)[0]) # Max: tensor([3., 4.]) print('Argmax: ', t.max(dim=0)[1]) # Argmax: tensor([1, 1])**텍스트**
스퀴즈(Squeeze) vs. 언스퀴즈(Unsqueeze)
- 스퀴즈 : 1인 차원을 제거한다.
- 언스퀴즈 : 특정 위치에 1인 차원을 추가한다.
ft = torch.FloatTensor([[0], [1], [2]]) > tensor([[0.], [1.], [2.]]) ft.size() > torch.Size([3, 1]) print(ft.squeeze()) # 스퀴즈 > tensor([0., 1., 2.]) print(ft.squeeze().shape) > torch.Size([3])
ft = torch.Tensor([0, 1, 2]) print(ft.shape) > torch.Size([3]) ###################### print(ft.unsqueeze(0)) # 언스퀴즈 # 인덱스가 0부터 시작하므로 0은 첫번째 차원을 의미한다. > tensor([[0., 1., 2.]]) print(ft.unsqueeze(0).shape) > torch.Size([1, 3]) ###################### print(ft.unsqueeze(1)) # 언스퀴즈 (두번째 차원에 1추가) > tensor([[0.], [1.], [2.]]) print(ft.unsqueeze(1).shape) > torch.Size([3, 1])
- view(), squeeze(), unsqueeze() : 텐서의 원소 수를 그대로 유지하면서 모양과 차원을 조절한다.
In-place Operation (덮어쓰기 연산)
x = torch.FloatTensor([[1, 2], [3, 4]]) print(x.mul(2.)) # 곱하기 2를 수행한 결과를 출력 > tensor([[2., 4.], [6., 8.]]) print(x) # 기존의 값 출력 > tensor([[1., 2.], [3., 4.]])
곱하기 2를 수행했지만 이를 x에다 다시 저장하지 않았으니, 기존의 값 x는 변하지 않음
그런데 연산 뒤에 _를 붙이면 기존의 값을 덮어쓰기 함.(연산 결과가 x에 저장됨)
print(x.mul_(2.)) # 곱하기 2를 수행한 결과를 변수 x에 값을 저장하면서 결과를 출력 print(x) # 기존의 값 출력 > tensor([[2., 4.], [6., 8.]])
이번에는 x의 값이 덮어쓰기 되어 2 곱하기 연산이 된 결과가 출력된다.
reference: https://wikidocs.net/52846
https://aigong.tistory.com/35
