
알려진 사실
COUNT(*)는 NULL값을 포함하는지 여부와 관계 없이 검색된 행의 개수를 반환하고,
COUNT(column)은 NULL값을 제외한 행의 개수를 반환합니다.
그렇기 때문에 데이터를 읽지 않고 레코드 수만 불러오는 COUNT(*)가
실제 데이터를 들여다보며 NULL을 확인하는 COUNT(column)보다 속도가 빠릅니다.
테스트
위 사실을 눈으로 확인하기 위해 간단한 테스트를 진행해 봤습니다.
테스트를 위해 dummy_table을 만들었습니다.
CREATE TABLE dummy_table(
id INT NOT NULL,
num INT,
str VARCHAR(255),
PRIMARY KEY(id)
);- dummy_table은 id를 PK로 가지며 num과 str은 null값이 허용된 column입니다.
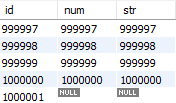
해당 테이블에 모든 값이 채워진 1_000_000건의 더미 데이터를 넣었습니다.
그리고 마지막에는 id를 제외한 num과 str이 NULL인 데이터를 하나 채웠습니다.
테이블에 들어간 데이터는 대략 다음과 같습니다.
단순 SELECT
COUNT가 아닌 단순 SELECT는 *보다 사용하는 column만 명시하는 게 더 빠릅니다.
SELECT * FROM dummy_table;쿼리는 0.51초가 소요됐습니다.

반면 SELECT num FROM dummy_table;쿼리는 0.34초가 소요됐습니다.
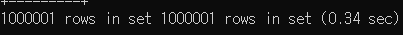
쿼리를 실행할 때마다 값의 오차는 있었지만 *를 이용한 쿼리가 column을 이용한 쿼리보다 느리다는 걸 변하지 않았습니다.
COUNT
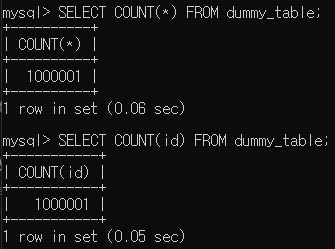
이번에는 COUNT쿼리를 실행해 보겠습니다.
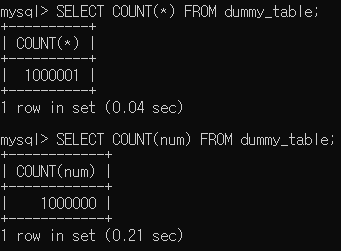
COUNT(*)가 COUNT(num)보다 훨씬 빠르다는 걸 확인할 수 있습니다.
또 다른 중요한 차이는 COUNT(*)는 NULL값을 제외하지 않아 1_000_001을 반환했지만,
COUNT(num)은 마지막에 추가한 NULL데이터를 제외한 1_000_000을 반환했습니다.
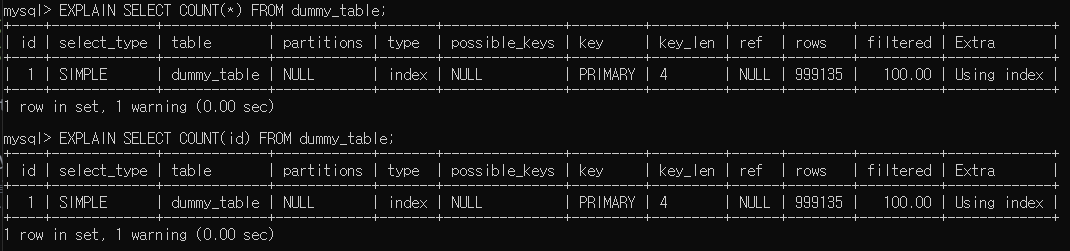
두 쿼리의 실행계획을 비교해 보겠습니다.
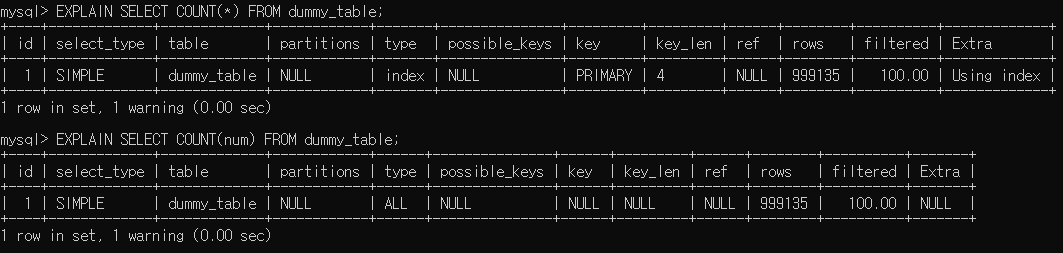
-
COUNT(num)는 type이 ALL로
FULL TABLE SCAN을 실행한다는 걸 확인할 수 있습니다. -
COUNT(*)는 type이 index로 적혀 있지만
INDEX SCAN을 실행하지 않고테이블의 행의 수를 추적하고 그 값을 바로 가져오는 방식으로 InnoDB가 최적화된다고 합니다.
어떠한 경우든 FULL TABLE SCAN을 하는 COUNT(column)보다는 성능이 좋습니다.
기타
COUNT(*)과 COUNT(PK)는 성능상 차이가 없고 둘의 실행계획도 동일합니다.
References
