
Bloom Filter란
Bloom Filter는 특정 원소가 집합에 속하는지 여부를 검사하는데 사용되는 확률적 자료 구조입니다.
Bloom Filter는 집합에 속하지 않는 원소를 집합에 속한다고 잘못 판단할 가능성은 존재하지만, 집합에 속한 원소를 집합에 속하지 않는다고 잘못 판단할 가능성은 없습니다.
동작 원리
Bloom Filter는 비트 배열과 여러 개의 해시 함수를 통해 동작합니다. 어떤 값이 들어왔을 때 그 값을 각각의 해시 함수에 입력하고, 그 결과값으로 나온 비트 배열의 위치를 마킹합니다.
해시 함수는 같은 입력값에 대해 항상 같은 결과값을 반환합니다.
값을 찾을 때도 마찬가지로 해시 함수의 결과값을 이용해 비트 배열이 모두 마킹되어 있으면 값이 존재한다고 판단합니다.
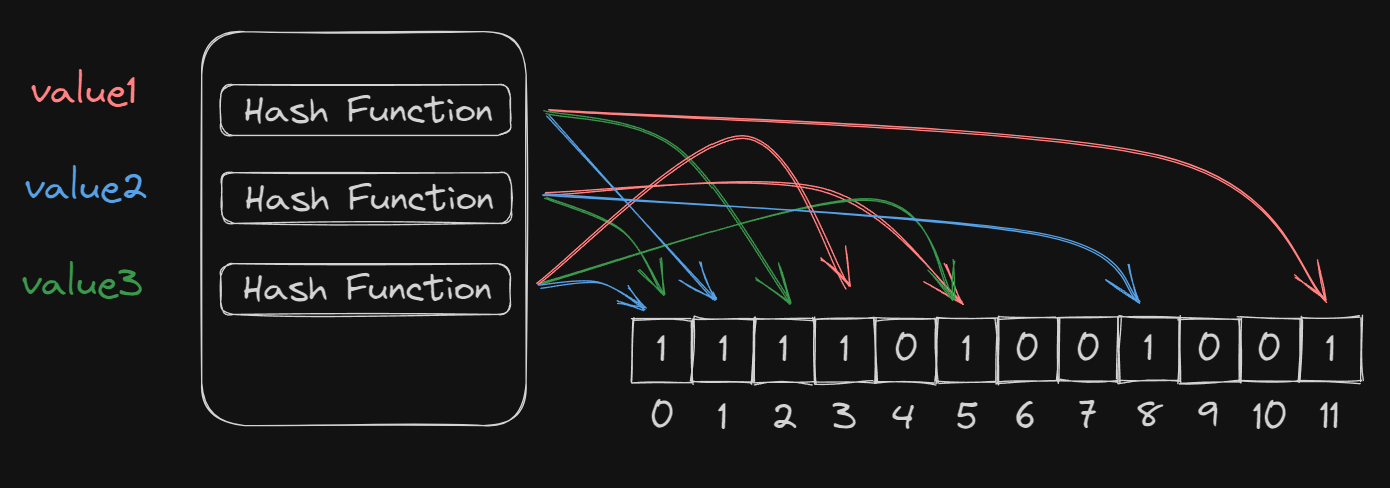
- 3개의 hash function과 size가 12인 비트 배열이 존재합니다.
- value1, value2, value3을 집어넣습니다.
- value1의 hash function 결과값으로 각각 3,5,11이 나왔습니다. 비트 배열의 해당 위치를 1로 마킹합니다.
- 같은 방식으로 value2와 value3의 hash function 결과값도 마킹되어 있습니다.
집합에 속하지 않는 원소를 집합에 속한다고 잘못 판단할 가능성
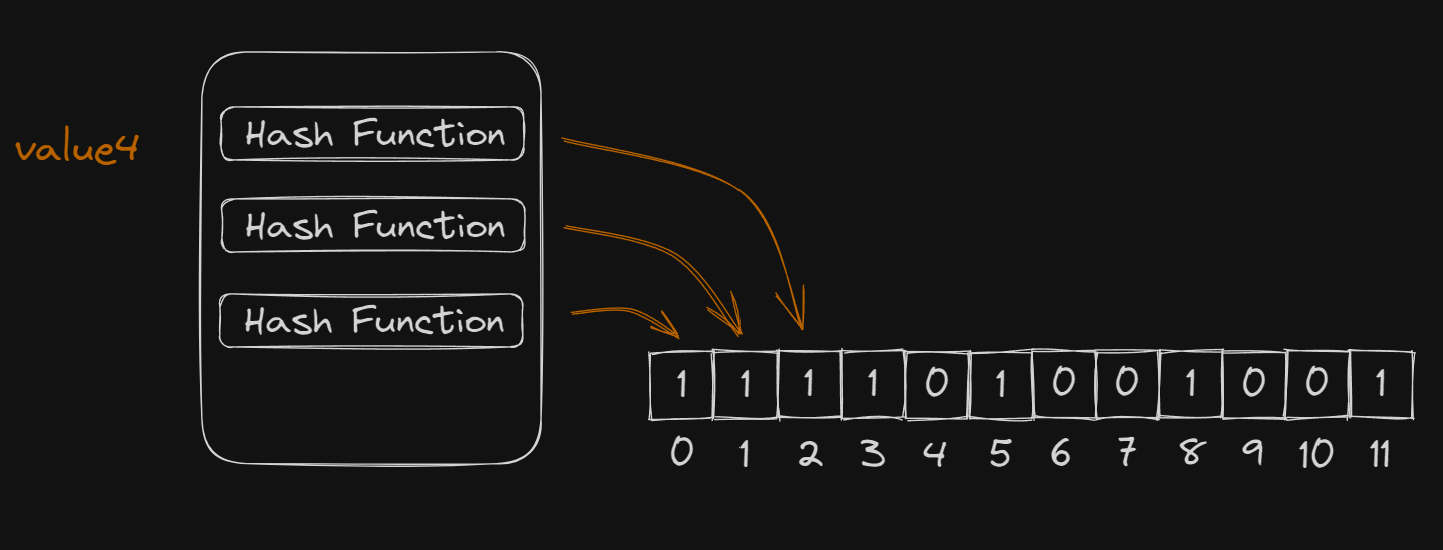
- value4는 집합에 존재하지 않는 값입니다. 하지만 3개의 hash function의 결과값으로 나온 비트 배열의 주소가 모두 1로 마킹되어 있어 해당 값이 존재하는 것으로 잘못 판단하게 됩니다.
집합에 속한 원소를 집합에 속하지 않다고 잘못 판단할 가능성

- value1은 집합에 존재하는 값입니다. value1의 hash function 결과값으로 나온 비트 배열의 주소는 이미 value1을 집합에 넣을 때 모두 1로 마킹해 뒀습니다. 따라서 value1이 포함되어 있음을 항상 보장할 수 있습니다.
값 제거
일반적인 블룸 필터는 집합에 들어온 값을 제거하는 기능을 지원하지 않습니다.
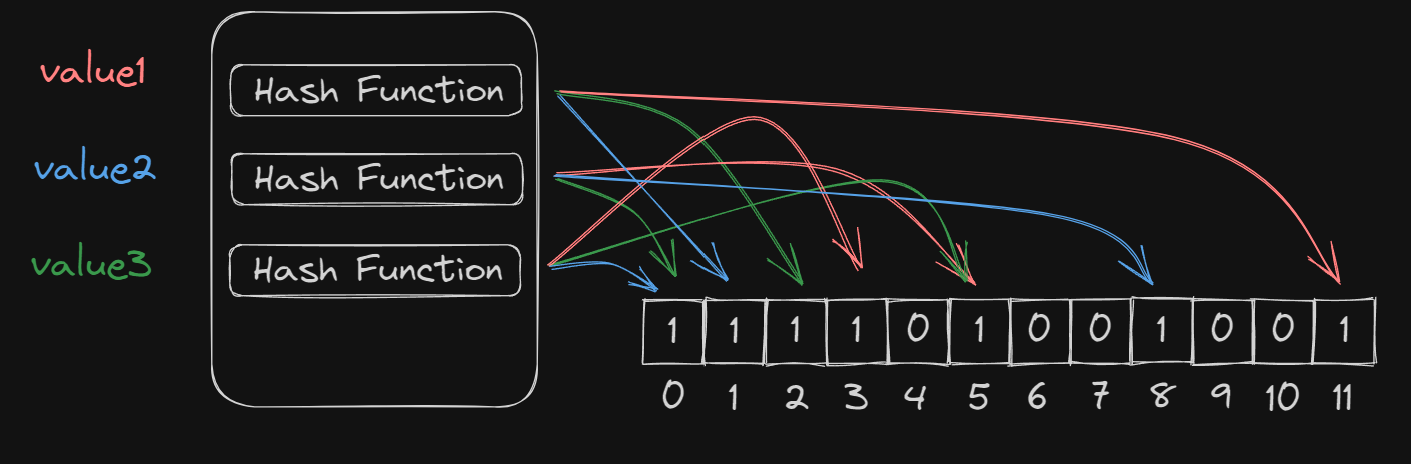
- value3을 삭제하기 위해 비트 배열의 0,2,5번 값을 다시 0으로 되돌린다고 생각해 봅시다. 이때 5번 인덱스는 value1에 의해서도 마킹된 값이기 때문에 0으로 되돌리면 value1이 존재하는지 판단하는 데 문제가 생기게 됩니다.
Redis에서 Bloom Filter 사용하기
RedisBloom모듈이 Redis Stack에 포함되면서 Redis에서도 간편하게 Bloom Filter를 사용할 수 있습니다.
Redis Stack
- Redis Stack은 Redis의 핵심 기능을 확장한 서비스입니다.
- Redis Stack은 RedisBloom모듈 말고도 RedisSearch, RedisJSON, RedisGraph, RedisTimeSeries 등의 모듈을 포함하고 있습니다.
설치
도커를 통해 Redis Stack을 간편하게 사용할 수 있습니다.
이미지 다운로드
docker pull redis/redis-stack:latest컨테이너 생성 및 실행
docker run -itd --name redis-stack -p 6379:6379 redis/redis-stack:latestredis-cli 접속
docker exec -it redis-stack redis-cli예시
Bloom Filter 생성
// BF.RESERVE <key> <error_rate> <capacity>
BF.RESERVE myBloomFilter 0.01 1000- 1000개 이하의 데이터에 대해 오차율이 1%인 myBloomFilter라는 이름의 블룸필터를 생성했습니다.
- capacity를 넘어가는 양의 데이터를 저장할 수도 있지만 그렇게 할 경우 오차율이 1%보다 커지게 됩니다.
단일 요소 추가
// BF.ADD <key> <value>
BF.ADD myBloomFilter value1
여러 요소 추가
// BF.MADD <key> <value> <value> ... <value>
BF.MADD myBloomFilter value2 value3
특정 요소 존재 여부 확인
// BF.EXISTS <key> <value>
BF.EXISTS myBloomFilter value1 // 1
BF.EXISTS myBloomFilter value4 // 0
여러 요소가 존재하는지 여부 확인
// BF.MEXISTS <key> <value> <value> ... <value>
BF.MEXISTS myBloomFilter value1 value4
Bloom Filter 내 특정 값(value) 또는 모든 값 출력
불가능합니다.
Bloom Filter는 확률적으로 값의 존재 여부를 반환합니다. 위에서 살펴본 것처럼 비트 배열에 해시값을 저장할 뿐 원본 데이터 자체를 저장하지 않기 때문에 그 값을 반환할 수 없습니다.

References

기록하고 정리하는 걸 좋아하는 백엔드 개발자입니다.