
Cuckoo filter란
Cuckoo Filter는 Bloom Filter와 마찬가지로 특정 원소가 집합에 속하는지 여부를 검사하는데 사용되는 확률적 자료 구조입니다. (참고 : Redis의 Bloom Filter)
Cuckoo Filter도 Bloom Filter처럼 집합에 속하지 않는 원소를 집합에 속한다고 잘못 판단할 가능성은 존재하지만, 집합에 속한 원소를 집합에 속하지 않는다고 잘못 판단할 가능성은 없습니다.
Cuckoo Filter는 Bloom Filter와 달리 데이터 삭제가 가능합니다. Bloom Filter의 배열은 비트값만 표시했지만, Cuckoo Filter의 버킷은 값(정확히는 값 자체가 아니라 이를 단순화한 fingerprint) 자체를 저장합니다.
일반적으로 데이터가 존재하는지 확인하는 연산은 Cuckoo Filter가 더 빠릅니다. Cuckoo Filter는 단 2개의 해시 테이블만 확인하면 됩니다.
반면 데이터를 삽입하는 연산은 Bloom Filter가 더 빠릅니다. Cuckoo Filter는 충돌이 발생할 경우 재삽입 알고리즘을 수행해야 합니다.
동작 원리
Cuckoo Filter는 2개의 해시 함수와 2개의 해시 테이블을 사용합니다. Cuckoo Filter는 내가 들어가야 할 자리에 이미 어떤 값이 자리잡고 있다면 그 값을 밀어내는 방식으로 동작합니다.
1. 첫번째 테이블에 자신이 들어갈 자리가 비어있다면 그대로 삽입됩니다.
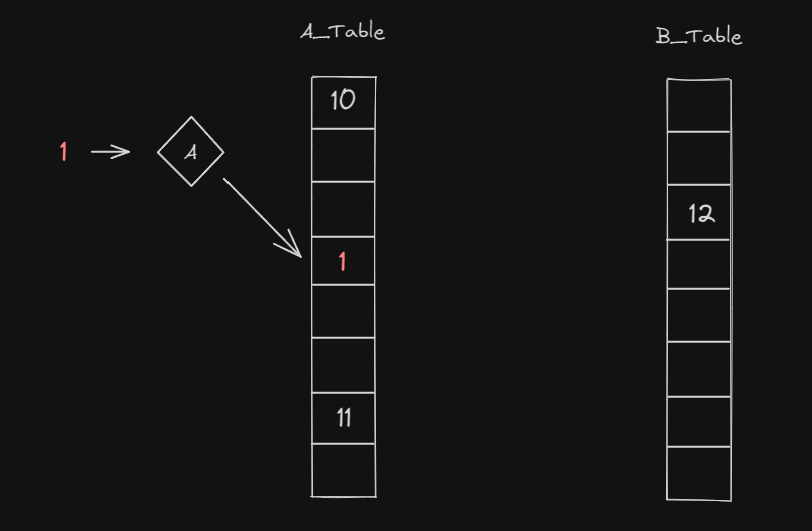
- 1은 A테이블에 곧바로 들어갈 수 있습니다.
2. 첫번째 테이블에 자신이 들어갈 자리에 이미 값이 차있다면 그 값을 밀어냅니다. 밀린 데이터는 두번째 테이블에 자신이 들어갈 수 있는지 확인하고 들어갑니다.
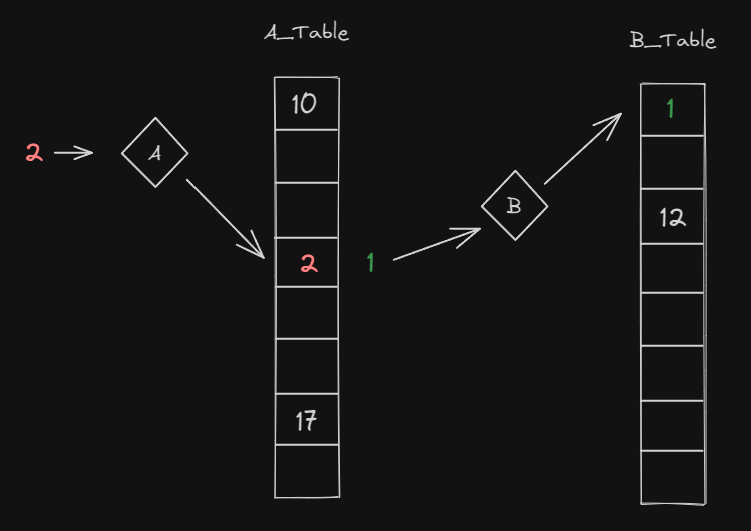
- A테이블에서 2가 들어가야 할 위치에 1이 있어 1을 밀어냅니다.
- 1은 B테이블에 곧바로 들어갈 수 있습니다.
3. 밀린 데이터 모두가 삽입될 수 있을 때까지 밀어내는 과정을 반복합니다.
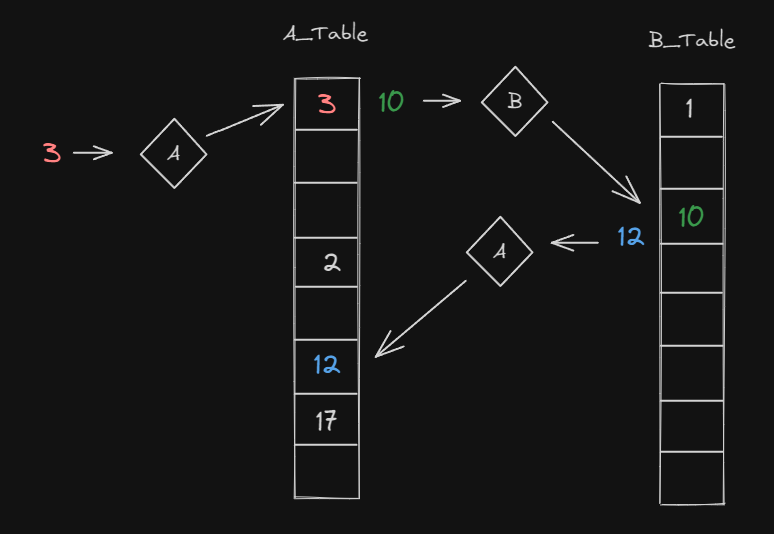
- A테이블에 3이 들어가야 할 위치에 10이 있어 10을 밀어냅니다.
- B테이블에 10이 들어가야 할 위치에 12가 있어 12를 밀어냅니다.
- 12는 A테이블에 곧바로 들어갈 수 있습니다.
값이 존재하는지 확인
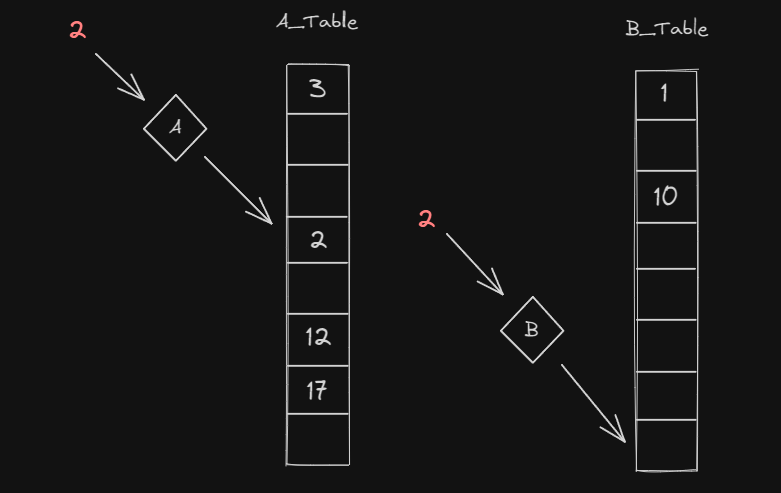
- 2라는 값이 존재하는지 확인하려면 A테이블의 A(2) 위치, B테이블의 B(2) 위치만 확인하면 됩니다. O(1) * 2
사이클과 재배치
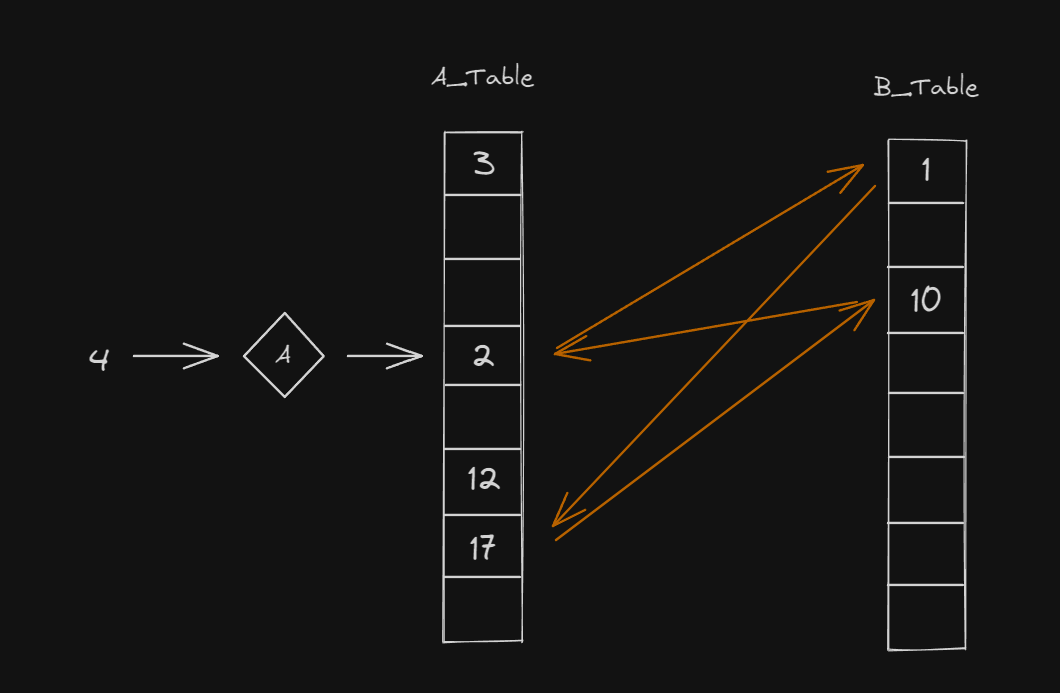
- A테이블에 4가 들어가야 할 위치에 2가 있어 2를 밀어냅니다.
- B테이블에 2가 들어가야 할 위치에 1이 있어 1을 밀어냅니다.
- A테이블에 1이 들어가야 할 위치에 17이 있어 17을 밀어냅니다.
- B테이블에 17이 들어가야 할 위치에 10이 있어 10을 밀어냅니다.
- A테이블에 10이 들어가야 할 위치에 4가 있어 4를 밀어내야 합니다. (4는 삽입하려는 데이터기 때문에 안밀려나야 하지만 만약 밀려났고) B테이블에 4가 들어가야 할 위치가 첫번째 칸(1이 있는 위치)이라면 모두 빈 자리를 얻는건 불가능합니다.
사이클이 발생하면 재배치가 일어납니다. 재배치는 해시 함수를 변경하거나 해시 테이블의 크기를 키운 뒤 모든 데이터를 다시 처음부터 새롭게 테이블에 집어넣습니다.
Redis에서 Cuckoo Filter 사용하기
Redis Stack과 도커로 Redis Stack을 실행하는 방법은 Redis의 Bloom Filter를 참고해 주세요.
예시
Cuckoo Filter 생성
// CF.RESERVE {key} {capacity} [BUCKETSIZE bucketSize] [MAXITERATIONS maxIterations] [EXPANSION expansion]
CF.RESERVE myCuckooFilter 1000- bucketSize : 버킷의 슬롯 수를 설정합니다. 해시 테이블은 한 공간에 여러 값을 담을 수 있는
슬롯이라는 개념이 존재합니다. - maxIterations : 하나의 값을 삽입할 때 최대 몇번의 밀어내기를 허용할지 설정합니다. maxIterations만큼 값들의 위치를 재조정 해봤지만 여전히 삽입이 불가하면 재배치를 실행합니다.
- expansion : Cuckoo Filter가 가득 찼을 때 확장하는 크기의 비율을 설정합니다.
요소 추가
// CF.ADD <key> <value>
CF.ADD myCuckooFilter value1특정 요소 존재 여부 확인
// CF.EXISTS <key> <value>
CF.EXISTS myCuckooFilter value1특정 요소 삭제
// CF.DEL <key> <value>
CF.DEL myCuckooFilter value1특정 요소의 개수 확인
// CF.COUNT <key> <value>
CF.COUNT myCuckooFilter value1- 슬롯으로 인해 동일한 값을 2개(테이블 개수) 이상 가지고 있을 수 있습니다.
References
