자바 개발자가 Go언어를 공부해보고 느낀점

최근 Go언어를 공부했습니다. 많은 내용을 공부한건 아니고 유튜브 Tucker의 Go 언어 프로그래밍 강의만 완강한 상태입니다. (강의 설명이 매우 좋았어서 Go언어에 관심이 있으신 분들에게 적극 추천드립니다!)
또한 저는 비전공자이며 Java/Kotlin외에 다른 언어(C계열은 한번도 안해봤습니다)를 제대로 공부해본 적 없는 2년차 주니어 개발자입니다.
이런 제가 Go언어를 공부하며 느꼈던 점, 그리고 Java와 달라 신기했던 점들에 대해 소개해 보고자 합니다. 많은 내용을 공부한게 아니다 보니 잘못된 내용이 있을 수 있습니다. 잘못된 내용이 있다면 알려주시면 감사하겠습니다!!
사소한 부분들
- for문에 괄호를 쓰지 않으며 아래와 같은 형태로 정의해야 합니다. 저는
for(를 타이핑 하는게 손에 배어 있어 처음에 조금 불편했습니다. 또한 while문이 없습니다.for i := 0; i < 10; i++ { } - 타입이 다양합니다. 자바의 int로 표현되는 숫자가 uint8, uint16, uint32, uint64, uint, int8, int16, int32, int64, int 이런 식으로 세분화되어 있습니다. int는 64비트 컴퓨터에서 int64로 동작하지만 int타입 변수에 int64타입 값을 대입하려면 타입변환이 필요합니다.
- 큐와 스택을 직접 구현해야 합니다. Go에서는 큐와 스택을 내장 자료형으로 제공해주지 않습니다.
- 별칭 타입을 제공합니다. Java에서 비슷한 개념을 찾아보자면 Wrapper클래스 정도가 될거 같습니다.
- 값을 선언했는데 사용하지 않으면 컴파일 에러가 발생합니다. 간혹 init을 위해 사용하지 않는 패키지를 import해야 할 경우가 있는데 이때는
_(blank identifier)를 사용해야 합니다. - 대문자로 시작하는 변수도 많이 사용합니다. 그 이유는 식별자 첫 글자의 대소문자로 접근 제어를 구분하기 때문입니다. 대문자로 시작하면 외부 공개(public), 소문자로 시작하면 비공개(private)입니다.
- 함수가 여러개의 반환값을 가질 수 있습니다. 성공시 결과값과 실패시 에러값을 같이 반환하는 형태가 많습니다.
func InputIntValue() (int, error) { var n int _, err := fmt.Scanln(&n) if err != nil { stdin.ReadString('\n') } return n, err } - try-catch가 없습니다. 에러를 처리하는 철학이 Java와 다르다고 합니다.
덕타이핑
개인적으로 Go를 공부하면서 가장 신기했던 개념입니다. Go는 OOP를 지향하지만 클래스와 상속의 개념이 없습니다. 클래스의 경우 비슷한 개념인 구조체가 있지만, 상속과 유사한 개념은 없는 대신 덕타이핑을 제공합니다.
만약 어떤 새를 봤는데 그 새가 오리처럼 걷고, 오리처럼 날고, 오리처럼 운다면 나는 그 새를 오리라고 부르겠다
덕타이핑은 객체를 정의하는 쪽이 아닌 사용하는 쪽에서 그 객체를 판단합니다.
Java의 객체 정의는 다음과 같습니다.
public interface Duck {
String duckCry();
}
public class SuperDuck implements Duck {
@Override
public String duckCry() {
return "슈퍼 꽥꽥";
}
}
public void observe(Duck duck) {
System.out.println(duck.duckCry());
}- SuperDuck을 정의할 때 상속을 이용해 이 객체가 Duck의 한 종류임을 명시하고 있습니다.
Go에서는 다음과 같습니다.
package superduck
type SuperDuck struct{}
func (s SuperDuck) DuckCry() string{
return "슈퍼 꽥꽥"
}import (
"fmt"
"superduck"
)
type Duck interface {
DuckCry() string
}
func observe(duck Duck) {
fmt.Println(duck.DuckCry())
}
func main() {
var duck Duck
duck = &superduck.SuperDuck{}
observe(duck)
}- SuperDuck을 정의하는 곳에는 Duck과 관련된 정보가 없습니다.
- Duck을 사용하는 곳에서
DuckCry() string메서드를 가진 객체는 Duck으로 취급하겠다고 정의했고, SuperDuck은 이를 만족하기 때문에 Duck으로 사용됐습니다.
포인터
C계열을 공부해보지는 않았지만 포인터가 뭔지 들어본 적은 있습니다. 제대로 공부해본 건 이번이 처음이였고, C를 공부했던 몇몇 지인들이 왜 포인터를 싫어했는지 이해할 수 있었습니다. 개념 자체는 어렵지 않았지만 실제 코드를 보면 헷갈리는 경우가 많았습니다.
타입 크기
Go는 각 타입마다 고정된 size를 가지며 이 부분이 중요합니다. 변수는 메모리에 저장되는데 한 지점이 아닌 공간(from부터 to까지)의 성격을 띕니다. 포인터로 변수가 저장된 메모리의 시작 위치를 알 수 있다면, 타입의 size를 통해 메모리의 끝 위치를 알 수 있습니다.
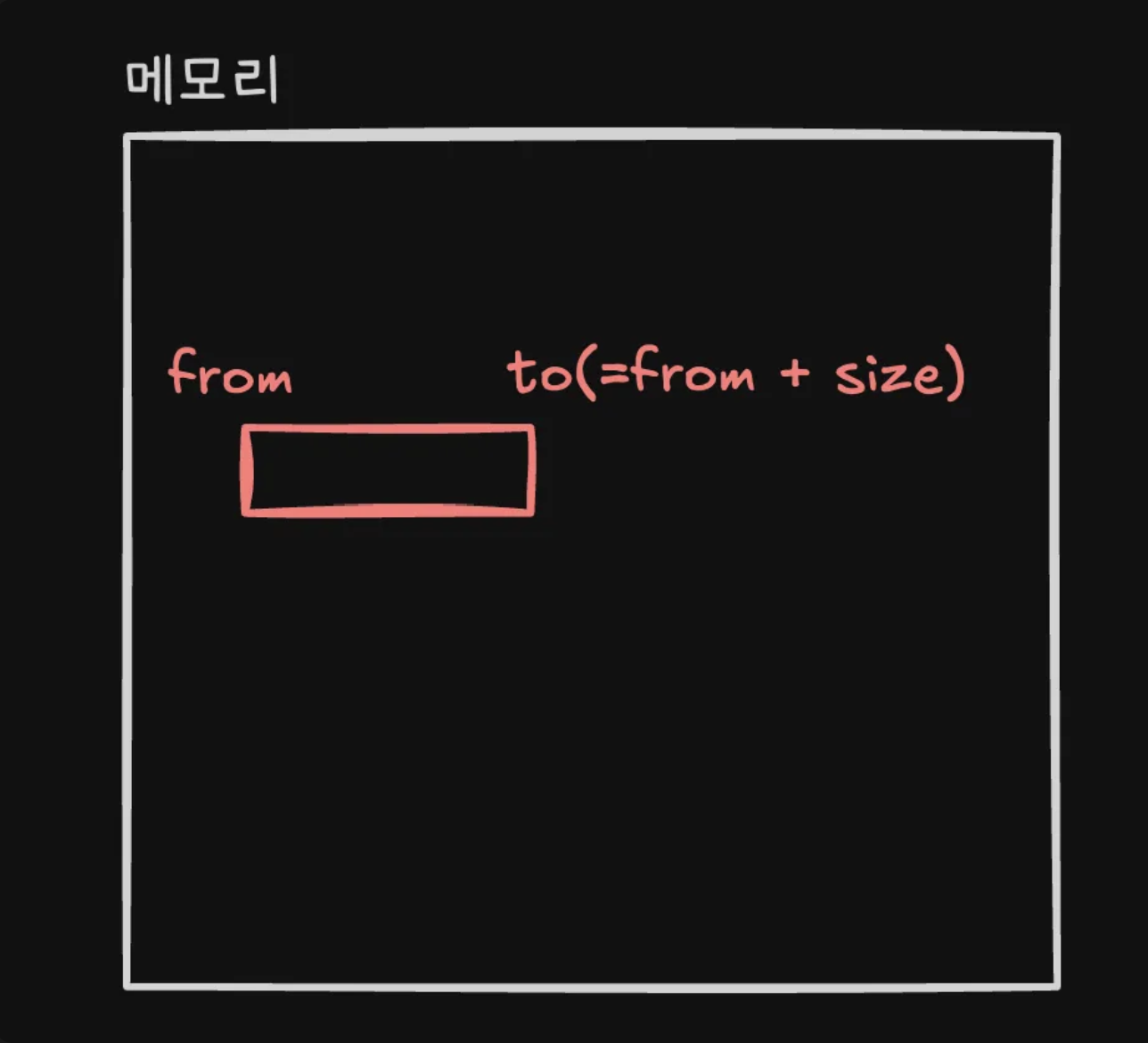
포인터와 타입 크기 모두 Java에서는 직접 관리해주기 때문에 개발자가 신경쓰지 않았던 부분인데 Go에서는 이를 직접 다뤄야 했습니다.
함수에 넣는 인자
Java에서는 어떤 함수를 실행하고 그 결과값을 받고 싶을 때 보통 함수의 return값을 변수에 대입합니다.
Scanner sc = new Scanner(System.in);
String s = sc.nextLine();Go역시 Java처럼 할 수 있지만, Go는 포인터라는 개념이 있어 결과값을 받고 싶은 변수를 함수의 인자로 전달하는 경우가 많습니다.
var a string
n, err = fmt.Scanln(&a)
- Go의 Scanln은 스캔한 아이템의 개수와 에러를 반환하지 스캔한 값을 반환하지 않습니다. 스캔한 값은 인자로 전달한 변수에 저장합니다.
슬라이스와 append
슬라이스를 처음 공부하고 들었던 생각은 '사이드 이펙트가 발생할 위험이 너무 큰거 같은데 이걸 실무에 어떻게 사용하지?'였습니다. 슬라이스는 배열에 대한 view로 reference type입니다. 따라서 슬라이스의 값을 변경하면 원본 배열의 값이 변경되고 이는 다른 슬라이스에도 영향을 미치게 됩니다.
arr := [3]int{1, 2, 3}
slice := arr[:]
slice[1] = 100
fmt.Println(arr) // [1 100 3]- 슬라이스는 배열의 값을 변화시킵니다.
arr := [3]int{1, 2, 3}
slice1 := arr[:]
slice2 := arr[:]
slice1[1] = 100
fmt.Println(slice2) // [1 100 3]- slice1에서 값을 변경해 원본 배열이 변화했고, 이는 slice2에도 영향을 미칩니다
특히 append함수로 slice에 요소를 추가할 때는 여유 공간이 있으면 해당 슬라이스를 반환하지만, 여유 공간이 없으면 새로운 슬라이를 만들어 반환합니다.
var slice1 = make([]int,3,5)
slice1[0] = 1
slice1[1] = 2
slice1[2] = 3
var slice2 = append(slice1,4,5)
slice1[1] = 100
fmt.Println(slice2) // [1 100 3 4 5]- slice1은 len 3, cap 5로 4와 5를 넣을 여유공간이 충분합니다. 따라서 append의 결과로 기존의 슬라이스를 반환하고, slice1과 slice2는 같은 배열을 참조합니다.
- slice1에서 값을 변경했을 때 slice2도 영향을 받습니다.
func main() {
var slice1 = make([]int, 3, 5)
slice1[0] = 1
slice1[1] = 2
slice1[2] = 3
var slice2 = append(slice1, 4, 5, 6)
slice2[1] = 999
fmt.Println(slice2) // [1 999 3 4 5 6]
fmt.Println(slice1) // [1 2 3]
}- slice1은 len 3, cap 5로 4,5,6을 넣을 여유공간이 부족합니다. 따라서 append의 결과로 새로운 슬라이스를 반환하고, slice1과 slice2는 다른 배열을 참조합니다.
- slice2에서 값을 변경해도 slice1은 영향을 받지 않습니다.
그래서 원본 배열을 공유하길 원치 않을때는 copy함수를 사용하는걸로 알고 있습니다. 그 외에 실무에서는 어떤 방법으로 슬라이스를 안전하게 사용하는지 궁금합니다.
모듈과 패키지
지금은 자바에 비해 모듈 및 패키지 관리가 불편하다고 느껴집니다. 아직 프로젝트를 진행해본건 아니라 프로젝트까지 한번 만들어봐야 제대로 알 것 같습니다.
고루틴
Go의 하이라이트라 생각합니다. 'Go는 병렬 처리가 쉽고 간편하다'라는 얘기를 많이 들었었는데 왜 그런지 단번에 느꼈습니다. 함수 앞에 go라는 키워드만 붙이면 해당 작업을 병렬로 실행할 수 있습니다.
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func PrintHangul() {
hanguls := []rune{'가', '나', '다', '라', '마', '바', '사'}
for _, v := range hanguls {
time.Sleep(300 * time.Millisecond)
fmt.Printf("%c ", v)
}
wg.Done()
}
func PrintNumbers() {
for i := 1; i <= 5; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%d ", i)
}
wg.Done()
}
func main() {
wg.Add(2)
go PrintHangul()
go PrintNumbers()
wg.Wait()
}
자바도 얼른 Virtual Thread가 안정화되어 고루틴과 같은 경량 스레드를 편리하게 사용할 수 있으면 좋겠습니다.
느낀점
이전에는 Go언어를 그저 '성능이 좋은 언어' 정도로만 알고 있었습니다. 하지만 찾아보면 Java와 성능 차이가 크지 않다는 얘기도 있고(물론 일반적으로 Go가 Java보다 성능이 더 좋긴 합니다), 성능을 원한다면 차라리 C++을 선택하라는 얘기도 많습니다. 저 또한 아직 Go를 이용한 서비스를 만들고 운영해본건 아니다보니 성능적인 강점을 체감해보지는 못했습니다.
그것보다 제가 느낀 Go의 장점은 언어의 간결함 입니다. Java를 공부한 상태로 Go를 공부했기 때문일 수도 있겠지만, 전반적으로 내용이 어렵지 않고 직관적이다는 생각이 많이 들었습니다.
하지만 Java의 거대한 생태계 및 강력한 프레임워크가 주는 이점도 무시할 수 없다고 생각합니다. Go언어에 어떤 웹 프레임워크가 있는지 아직 잘 모르지만, 만약 Java의 Spring, SpringBoot와 같은 강력한 프레임워크가 없는 상황에서 단순한 웹 어플리케이션을 만들어야 한다면 굳이 Go를 선택할 필요는 없을거 같다는 생각이 듭니다.
Go에 대해 더 공부해보고 느낀점이 있다면 다시 한번 글을 쓰도록 하겠습니다.
