
들어가기 앞서
- 이 글은 채널톡의 사용량 기반 과금 모델 구현하기: 문제편을 읽고 작성한 글입니다.
- 모든 이미지 및 내용 출처 역시 채널톡의 사용량 기반 과금 모델 구현하기: 문제편에서 비롯된 것임을 밝힙니다.
이 글은 채널톡의 사용량 기반 과금 모델 구현하기: 문제편에서 언급된 내용의 일부를 제 나름대로 구현해본 글입니다. 채널톡의 글에서 소개된 내용은 따로 설명하지 않으니 원 글과 함께 보시는 걸 추천드립니다. 저는 채널톡과 아무런 관련이 없는 사람이며 제가 작성한 내용 및 코드는 채널톡의 실제 코드와는 전혀 무관합니다.
틀린 내용이 있을 수 있습니다. 틀린 내용은 댓글로 알려주시면 감사하겠습니다.
또한 마지막 '스트림 처리 시스템'은 채널톡에서 해결편을 올려주신다고 합니다. 제가 글을 쓰는 현재는 아직 해답편이 올라오지 않은 상태라 실제 채널톡의 접근과는 많이 다를 수 있다는 점도 참고해 주시면 감사하겠습니다.

Race Condition
해당 내용과 비슷한 상황인 쿠폰 발급 기능을 구현하면서 동시성 문제를 해결했던 경험이 있습니다. 저는 당시 redis를 활용해 Race Condition문제를 해결했습니다. 해당 내용이 궁금하시다면 링크에 정리된 내용을 참고해 주시면 감사하겠습니다.
채널톡에서 소개한 raceCondition이 발생할 수 있는 상황(pseudoCode) 및 해결방법은 다음과 같습니다. 해당 내용을 하나씩 살펴보겠습니다.
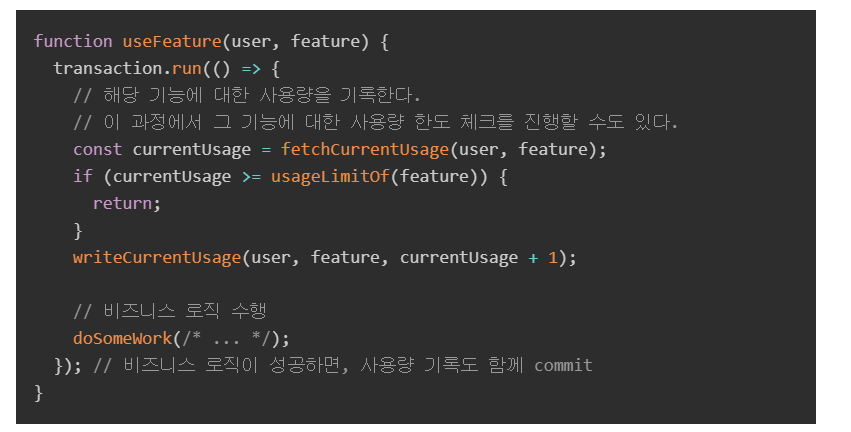

Race Condition 확인하기
채널톡의 pseudoCode를 Java, SpringBoot, Jpa를 이용해 간단히 구현해봤습니다.
UsageInfo
@Entity
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UsageInfo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Integer currentUsage;
private Integer limitUsage;
public void updateCurrentUsage() {
currentUsage++;
}
}UsageInfoRepository
public interface UsageInfoRepository extends JpaRepository<UsageInfo, Long> {}UsageInfoService
@Service
@RequiredArgsConstructor
public class UsageInfoService {
private final UsageInfoRepository usageInfoRepository;
@Transactional
public void useFeature(Long usageInfoId) {
UsageInfo usageInfo = usageInfoRepository.findById(usageInfoId)
.orElseThrow(() -> new RuntimeException("Usage Not Exist"));
int currentUsage = usageInfo.getCurrentUsage();
int limitUsage = usageInfo.getLimitUsage();
if(currentUsage >= limitUsage) {
throw new RuntimeException("Limit Exceeded");
}
usageInfo.updateCurrentUsage();
doSomeWork();
}
private void doSomeWork() {
System.out.printf("I'm working in %s %n", Thread.currentThread().getName());
}
}UsageInfoTest
@SpringBootTest
@Transactional
class UsageInfoServiceTest {
@Autowired
private UsageInfoRepository usageInfoRepository;
@Autowired
private UsageInfoService usageInfoService;
@Test
@DisplayName("10개의 스레드에서 동시에 업데이트를 진행했을 때 raceCondition 문제가 발생한다")
void raceConditionProblem() throws InterruptedException {
// given
int count = 10;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch endSignal = new CountDownLatch(count);
UsageInfo usageInfo = UsageInfo.builder()
.currentUsage(0)
.limitUsage(count)
.build();
executorService.submit(() -> {
usageInfoRepository.save(usageInfo);
startSignal.countDown();
});
// when
for (int i = 0; i < 10; i++) {
executorService.execute(() -> {
try {
startSignal.await();
usageInfoService.useFeature(usageInfo.getId()); // myMethod
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
endSignal.countDown();
}
});
}
endSignal.await();
UsageInfo result = usageInfoRepository.findById(usageInfo.getId()).get();
System.out.println(result.getCurrentUsage());
Assertions.assertThat(result).isEqualTo(10);
}
} - currentUsage가 0인 UsageInfo를 만들고 저장합니다. 이후 서로 다른 스레드에서 update를 시도합니다
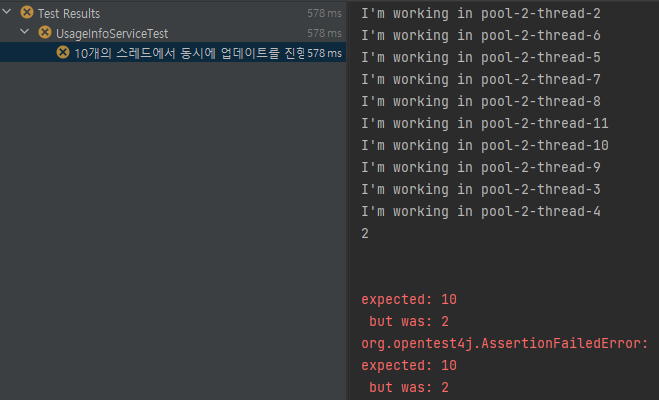
- raceCondition이 발생해 currentUsage의 최종값은 10이 아닌 2가 되었습니다
아래에서 소개하는 다른 코드들도 usageInfoService의 메서드를 호출하는 myMethod부분만 바꾼 동일한 환경에서 테스트를 진행했습니다. 위 테스트 코드와 관련된 내용은 여기를 참고해 주시면 감사하겠습니다.
Atomic Write
UsageInfoRepository
public interface UsageInfoRepository extends JpaRepository<UsageInfo, Long> {
@Modifying
@Query(value = "update UsageInfo u set u.currentUsage = u.currentUsage + 1 where u.id = :id")
void atomicWrite(@Param("id") Long usageInfoId);
}UsageInfoService
@Service
@RequiredArgsConstructor
public class UsageInfoService {
private final UsageInfoRepository usageInfoRepository;
@Transactional
public void useFeatureWithAtomicWrite(Long usageInfoId) {
UsageInfo usageInfo = usageInfoRepository.findById(usageInfoId)
.orElseThrow(() -> new RuntimeException("Usage Not Exist"));
int currentUsage = usageInfo.getCurrentUsage();
int limitUsage = usageInfo.getLimitUsage();
if(currentUsage >= limitUsage) {
throw new RuntimeException("Limit Exceeded");
}
usageInfoRepository.atomicWrite(usageInfoId);
doSomeWork();
}
private void doSomeWork() {
System.out.printf("I'm working in %s %n", Thread.currentThread().getName());
}
} 테스트 결과
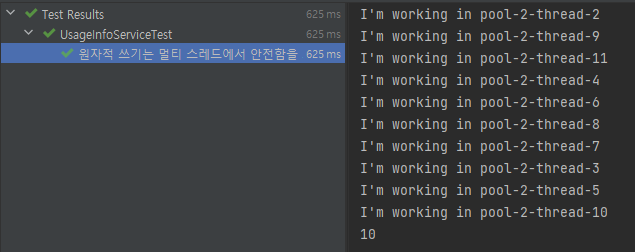
Mutex
UsageInfoRepository
public interface UsageInfoRepository extends JpaRepository<UsageInfo, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query(value = "select u from UsageInfo u where u.id = :id")
UsageInfo findByIdWithPessimisticLock(@Param("id") Long usageInfoId);
}UsageInfoService
@Service
@RequiredArgsConstructor
public class UsageInfoService {
private final UsageInfoRepository usageInfoRepository;
@Transactional
public void useFeatureWithPessimisticLock(Long usageInfoId) {
UsageInfo usageInfo = usageInfoRepository.findByIdWithPessimisticLock(usageInfoId);
int currentUsage = usageInfo.getCurrentUsage();
int limitUsage = usageInfo.getLimitUsage();
if(currentUsage >= limitUsage) {
throw new RuntimeException("Limit Exceeded");
}
usageInfo.updateCurrentUsage();
doSomeWork();
}
private void doSomeWork() {
System.out.printf("I'm working in %s %n", Thread.currentThread().getName());
}
}테스트 결과
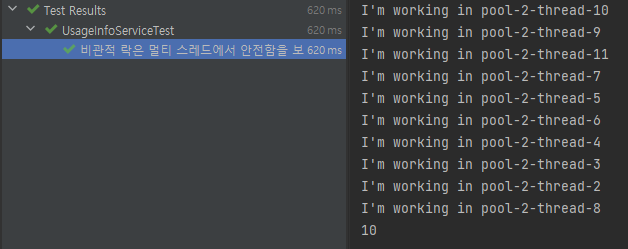
Optimistic Update
UsageInfo
@Entity
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UsageInfo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Integer currentUsage;
private Integer limitUsage;
// version 추가
@Version
private Integer version;
public void updateCurrentUsage() {
currentUsage++;
}
}UsageInfoService
@Service
@RequiredArgsConstructor
public class UsageInfoService {
private final UsageInfoRepository usageInfoRepository;
public static Map<Long, Integer> cache = new ConcurrentHashMap<>();
@Transactional
public void useFeatureWithCaching(Long usageInfoId) {
UsageInfo usageInfo = usageInfoRepository.findById(usageInfoId)
.orElseThrow(() -> new RuntimeException("Usage Not Exist"));
int currentUsage = usageInfo.getCurrentUsage();
int limitUsage = usageInfo.getLimitUsage();
if(currentUsage >= limitUsage) {
throw new RuntimeException("Limit Exceeded");
}
cache.compute(usageInfoId, (k,v) -> v == null ? 1 : v+1);
doSomeWork();
}
private void doSomeWork() {
System.out.printf("I'm working in %s %n", Thread.currentThread().getName());
}
}테스트 결과
처음 Race Condition을 확인할 때 사용했던 메서드(usageInfoService.useFeature)를 그대로 사용했습니다. 이때 테스트 코드의 결과는 초록불이지만 로그를 보면 스레드 내에서 에러가 발생한 걸 알 수 있습니다.
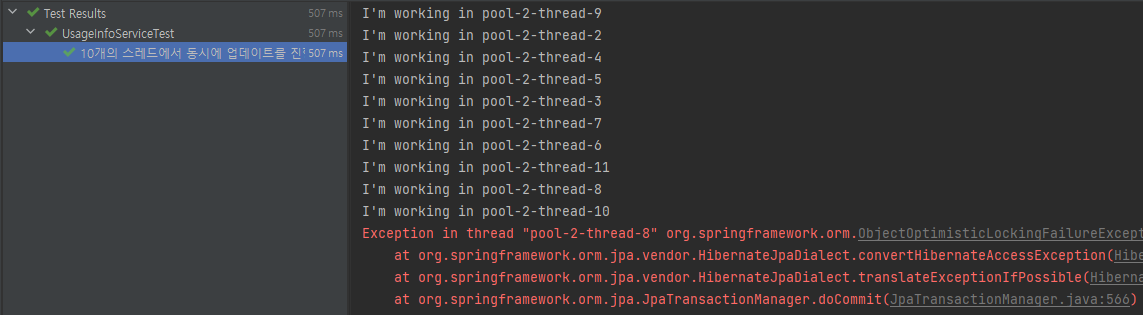
- 초록불인 이유는 스레드 내에서의 예외가 테스트 코드를 실행하는 스레드까지 전파되지 않기 때문입니다.
에러를 자세히 살펴봅시다.
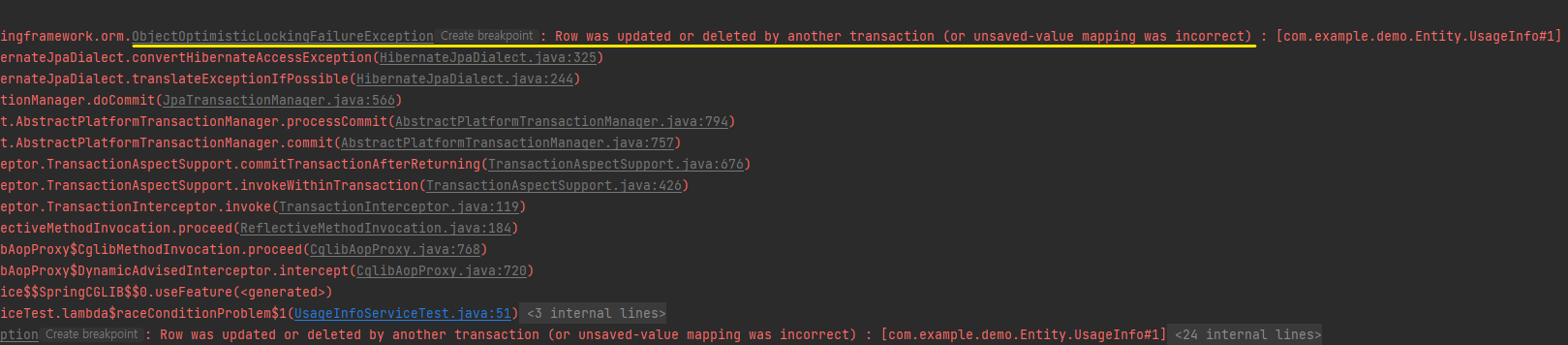
- 다른 트랜잭션에 의해 값이 변경됐다는 내용과 함께 OptimisticLockingFailureException이 발생했습니다.
- 낙관락은 최초의 변경만 허용하고 나머지 변경에 대해 예외를 반환해 줍니다. 따라서 낙관락으로 모든 요청을 실행시키려면 예외를 감지해 재시도하는 로직이 필요합니다
요청 수 줄이기
저는 스케줄러를 이용해 주기적으로 update를 실행하는 코드를 만들어 봤습니다.
DemoApplication
@EnableScheduling
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}UsageInfoRepository
public interface UsageInfoRepository extends JpaRepository<UsageInfo, Long> {
@Modifying
@Query(value = "update UsageInfo u set u.currentUsage = u.currentUsage + :count where u.id = :id")
void atomicWriteWithCaching(@Param("id") Long usageInfoId, @Param("count") Integer count);
}UsageInfoService
@Service
@RequiredArgsConstructor
public class UsageInfoService {
private final UsageInfoRepository usageInfoRepository;
public static Map<Long, Integer> cache = new ConcurrentHashMap<>();
@Transactional
public void useFeatureWithCaching(Long usageInfoId) {
UsageInfo usageInfo = usageInfoRepository.findById(usageInfoId)
.orElseThrow(() -> new RuntimeException("Usage Not Exist"));
int currentUsage = usageInfo.getCurrentUsage();
int limitUsage = usageInfo.getLimitUsage();
if(currentUsage >= limitUsage) {
throw new RuntimeException("Limit Exceeded");
}
cache.compute(usageInfoId, (k,v) -> v == null ? 1 : v+1);
doSomeWork();
}
@Scheduled(fixedDelay = 30000)
@Transactional
void periodicUpdate() {
for (var entries : cache.entrySet()) {
Long key = entries.getKey();
Integer value = entries.getValue();
usageInfoRepository.atomicWriteWithCaching(key,value);
}
cache.clear();
}
private void doSomeWork() {
System.out.printf("I'm working in %s %n", Thread.currentThread().getName());
}
}
- 스케줄링을 적용한 periodicUpdate메서드를 통해 주기적으로 update를 실행합니다. 하지만 채널톡에서 얘기한 graceful termination이 충실하게 구현되어 있지 못합니다.
graceful termination
ContextClosedEvent를 받는 ApplicationListener를 정의하고 빈으로 등록했습니다.
@Component
@RequiredArgsConstructor
public class GracefulShutdownEventListener implements ApplicationListener<ContextClosedEvent> {
private final UsageInfoRepository usageInfoRepository;
@Override
public void onApplicationEvent(ContextClosedEvent event) {
for (var entries : UsageInfoService.cache.entrySet()) {
Long key = entries.getKey();
Integer value = entries.getValue();
usageInfoRepository.atomicWriteWithCaching(key,value);
}
UsageInfoService.cache.clear();
}
}- ContextClosedEvent는 SIGTERM(kill -15)을 감지할 수 있지만 SIGKILL(kill -9)은 감지하지 못합니다. 따라서 강제종료의 경우 여전히 유실이 발생하게 됩니다.
in-memory에 값을 저장할 때마다 로그를 남기고 비정상적인 종료가 발생했을 때 해당 로그를 이용해 이전 상태로 복구하는 방법도 가능할 거 같습니다.
스트림 처리 시스템
채널톡이 문제를 해결하기 위해 설계한 시스템 아키텍처는 다음과 같습니다.
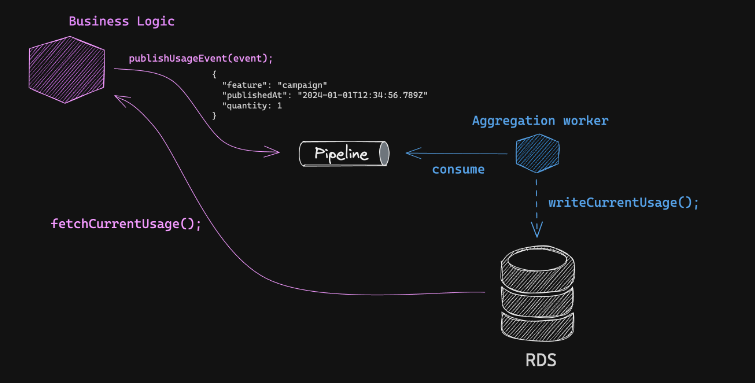
채널톡의 글은 아키텍처와 더불어 설계시 고민했던 부분에 대해서도 소개해 주고 있습니다. 해당 부분까지 종합적으로 고려했을 때 저는 카프카 스트림즈를 사용하는게 가장 적절해 보였습니다. 그 이유는 카프카 스트림즈가 내부적으로 exactly once를 보장해 주는 것으로 알려져 있기 때문입니다.
미완성 코드
아래는 카프카 스트림즈를 학습해보고 예제 코드를 만들기 위해 작성한 미완성 코드입니다(제대로 동작하지 않습니다. 그러니 참고용으로 훑어보거나 또는 보시지 않고 넘어가도 됩니다).
Processor
public class Processor {
private static String APPLICATION_NAME = "MY_APPLICATION";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String SOURCE_TOPIC = "source_topic";
private static String SINK_TOPIC = "sink_topic";
private static Map<Long, Integer> cache = new ConcurrentHashMap<>();
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
StreamsBuilder builder = new StreamsBuilder();
KStream<Long, EventDto> kStream = builder.stream(SOURCE_TOPIC, Consumed.with(Serdes.Long(),CustomSerdes.eventDto()));
KStream<Long, EventDto> filterStream = kStream.filter(
(key, value) -> {
if(cache.containsKey(key)) {
cache.put(key, cache.get(key) + value.getQuantity());
}else {
cache.putIfAbsent(key, value.getQuantity());
}
value.setQuantity(cache.get(key));
return true;
}
);
filterStream.to(SINK_TOPIC);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
}
}- 스트림즈는 기본적으로
토픽에서 데이터를 가져온 뒤 해당 데이터를 가공하여 다른 토픽으로 전달하는 작업으로 구성됩니다.
CustomSerdes
public class CustomSerdes {
private CustomSerdes() {}
public static Serde<EventDto> eventDto() {
JsonSerializer<EventDto> serializer = new JsonSerializer<>();
JsonDeserializer<EventDto> deserializer = new JsonDeserializer<>(EventDto.class);
return Serdes.serdeFrom(serializer, deserializer);
}
}- 스트림즈는 토픽에서 데이터를 꺼내면서 동시에 토픽에 데이터를 넣는 역할을 합니다. 직렬화 및 역직렬화 작업이 모두 필요하기 때문에 Serde타입이 필요하고 우리가 원하는 객체(EventDto)로 직렬화 및 역직렬화를 진행하기 위해 CustomSerdes를 만들었습니다.
BusinessController
@RestController
@RequiredArgsConstructor
public class BusinessController {
private final KafkaTemplate<Long, EventDto> template;
@GetMapping
public void publishUsageEvent() {
Long userId = 1L;
EventDto eventDto = EventDto.builder()
.feature("feature")
.quantity(1)
.publishedAt(LocalDateTime.now())
.build();
template.send("source_topic",userId,eventDto);
}
} - 비즈니스 로직으로 유저의 요청을 처리한 뒤 카프카 스트림즈가 바라보고 있는 토픽(source_topic)에 이벤트를 전달합니다.
References
- https://clack2933.tistory.com/46
- https://isntyet.github.io/jpa/JPA-%EB%B9%84%EA%B4%80%EC%A0%81-%EC%9E%A0%EA%B8%88(Pessimistic-Lock)/
- https://blog.naver.com/horajjan/220584946854
- https://velog.io/@developer_khj/Spring-Boot-Scheduler-Scheduled
- https://0soo.tistory.com/176
- https://www.bucketplace.com/post/2022-05-20-%EA%B4%91%EA%B3%A0-%EC%A0%95%EC%82%B0-%EC%8B%9C%EC%8A%A4%ED%85%9C%EC%97%90-kafka-streams-%EB%8F%84%EC%9E%85%ED%95%98%EA%B8%B0/
- https://tzara.tistory.com/137
- https://velog.io/@jwpark06/Kafka-%EC%8A%A4%ED%8A%B8%EB%A6%BC%EC%A6%88-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0
- https://velog.io/@limsubin/kafka-Streams%EB%A5%BC-java%EB%A1%9C-%EA%B5%AC%ED%98%84%ED%95%B4%EB%B3%B4%EC%9E%90
