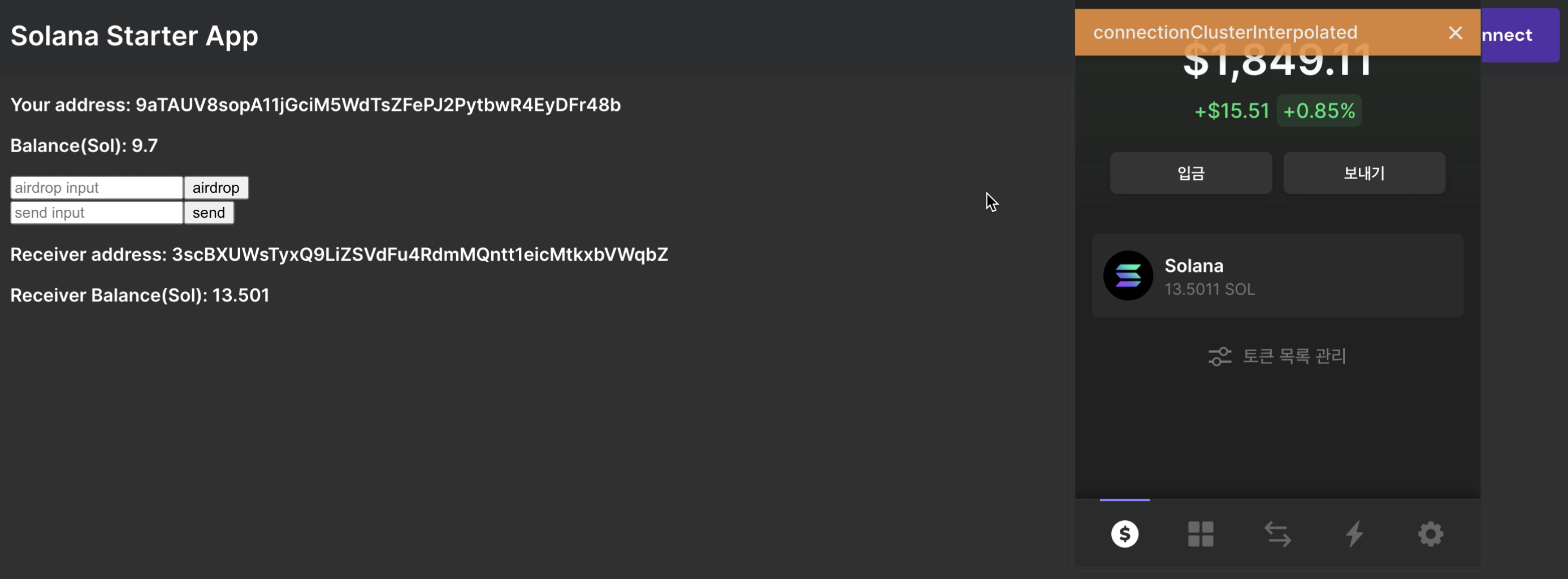
안녕하세요. 저는 요즘 핫한 블록체인 관련 개발을 하고 있습니다. 같이 프로젝트도 하고 오프라인 소통을 하고싶은데, 아직은 혼자 공부하고 싶은 내용들이 많아서 코로나가 잠잠해질때까지 열공해보겠습니다. 오늘은 솔라나 네트워크에 연결되는 1.팬텀지갑을 연동하고, 2.솔라나 토큰을 에어드랍 받아서 3.다른 지갑으로 전송하고 트랜잭션을 확인해보겠습니다. 먼저, 작업한 영상을 공유합니다.
깃헙 영상 확인하기
작업한 내용을 알아보기 전에, 크롬 확장프로그램인 Phantom Wallet을 깔아주세요.
1. 솔라나 지갑 연동
Solana-labs에서 dApp을 쉽게 만들 수 있도록 많은 것들을 개발하고 있는데요. 지갑은 @solana/wallet-adapter 라이브러리를 활용해서 쉽게 연동할 수 있었습니다.
기술스택: react, typeScript, web3.js
간단하게 구현했고, 요즘은 Next.js 프레임워크에 TypeScript로 많이 개발하더라구요. 다음에는 이 기술스택을 적용해보겠습니다.
import { WalletAdapterNetwork, WalletError } from "@solana/wallet-adapter-base";
import {
ConnectionProvider,
WalletProvider,
} from "@solana/wallet-adapter-react";
import { WalletModalProvider } from "@solana/wallet-adapter-react-ui";
import {
LedgerWalletAdapter,
PhantomWalletAdapter,
SlopeWalletAdapter,
SolflareWalletAdapter,
SolletExtensionWalletAdapter,
SolletWalletAdapter,
TorusWalletAdapter,
} from "@solana/wallet-adapter-wallets";
import { clusterApiUrl } from "@solana/web3.js";
import React, { FC, useCallback, useMemo } from "react";
import toast, { Toaster } from "react-hot-toast";
import { Notification } from "../Notification";
import { Navigation } from "../Navigation";export const Wallet: FC = () => {
// devnet, testnet, mainnet-beta 중 하나의 네트워크에 연결합니다.
const network = WalletAdapterNetwork.Devnet;
const endpoint = useMemo(() => clusterApiUrl(network), [network]);
// network를 전환하더라도 바로 컴파일 될것이고, 로그인된 정보로 접속됩니다.
const wallets = useMemo(
() => [
new PhantomWalletAdapter(),
new SlopeWalletAdapter(),
new SolflareWalletAdapter(),
new TorusWalletAdapter(),
new LedgerWalletAdapter(),
new SolletWalletAdapter({ network }),
new SolletExtensionWalletAdapter({ network }),
],
[network]
);
// 접속에 문제가 생겼을 때 토스트로 에러메세지를 띄워줍니다.
const onError = useCallback(
(error: WalletError) =>
toast.custom(
<Notification
message={
error.message ? `${error.name}: ${error.message}` : error.name
}
variant="error"
/>
),
[]
);
return (
<ConnectionProvider endpoint={endpoint}>
<WalletProvider wallets={wallets} onError={onError} autoConnect>
<WalletModalProvider>
<Navigation />
</WalletModalProvider>
<Toaster position="bottom-left" reverseOrder={false} />
</WalletProvider>
</ConnectionProvider>
);
};이 페이지에서 궁금한 내용입니다.
const endpoint = useMemo(() => clusterApiUrl(network), [network]);endpoint는 web3.js 라이브러리에서 제공하는 clusterApiUrl에 사용하는 네트워크(devnet)을 전송해줌으로써 가져오는데요. 그럼 cluster가 뭘까요? 저는 잘 모르는 단어를 보면, 단어가 가진 역사를 먼저 훑어보고 접근하는 습관이 있는데요.
cluster에 대하여
1. 클러스터의 개념과 역사
컴퓨터 클러스터는 "단일 시스템으로 볼 수 있도록 함께 작동하는 컴퓨터 세트"입니다. 즉, 컴퓨터 여러 대가 모여 계산을 처리하지만, 하나의 대규모 문제를 푸는, 마치 단일 시스템처럼 보이는 것을 얘기합니다.
"Greg Pfister는 클러스터가 특정 공급업체에 의해 발명된 것이 아니라 한 컴퓨터에서 모든 작업을 수행할 수 없거나 백업이 필요한 고객이 발명했다고 말했습니다. 피스터는 날짜를 1960년대로 추정한다. 모든 종류의 병렬 작업을 수행하는 수단으로서 클러스터 컴퓨팅의 형식적인 엔지니어링 기반은 1967년 병렬 처리에 관한 획기적인 논문으로 여겨지는 Amdahl의 법칙을 발표한 IBM 의 Gene Amdahl에 의해 틀림없이 발명되었습니다."
2. 전통적인 직렬처리 방식에서 병렬 처리 방식의 도입
2-1. 전통적인 직렬처리 방식
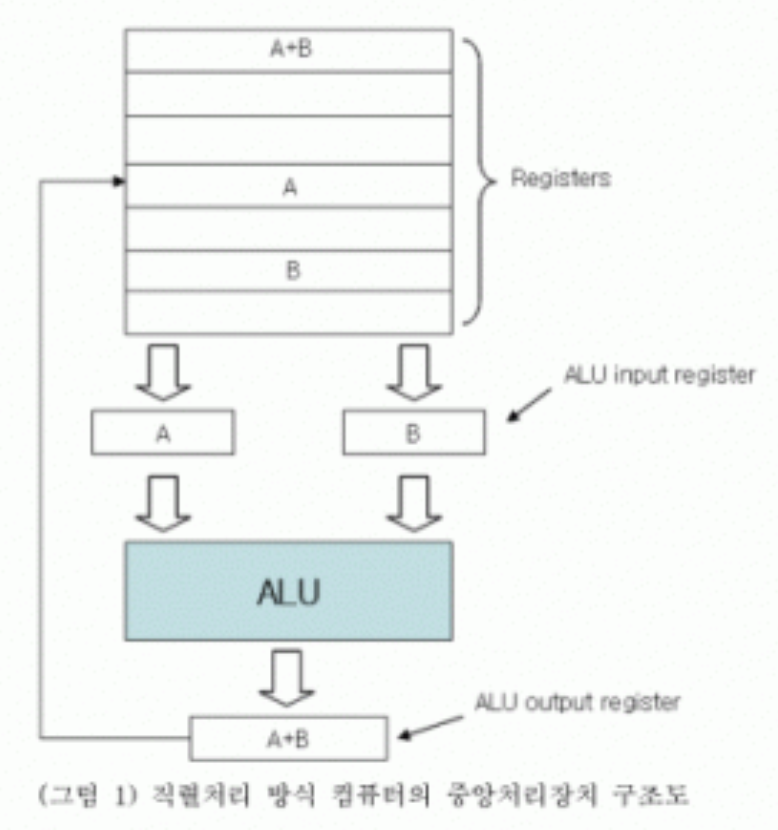
전통적인 직렬처리 방식은 위 사진과 같다. 그러나 오늘날 컴퓨터의 주된 이용 분야는 데이터, 정보, 그리고 지식이나 지능처리 등이다. 과거부터 대규모의 계산이 요구되는 이들 문제를 좀 더 효율적으로 처리하기 위한 더욱더 우수한 성능의 컴퓨터 개발이 절실하게 대두되었다. 그러나 컴퓨터의 성능은 대개 그 규모가 클수록 향상되고 일반적으로 그로시의 법칙에 의하여 대형 컴퓨터일수록 성능 대 가격비가 커진다고 생각하여 컴퓨터는 점점 대형화되어 왔다. 대형화에는 회로기술 및 소프트웨어의 기술면에서 한계가 있어 결국 대황하하는 것만으로는 고성능 컴퓨터에 대한 요구를 충족시킬 수가 없었다. 그러므로 이들을 효과적으로 처리하기 위한 대안으로 문제를 병렬로 처리하는 기법이 도입되었다. 즉, 비싸고 대규모의 계산도 처리하기 힘들고, 크기도 큰 대형 컴퓨터보다 저렴하고 작은 컴퓨터를 여러대로 나누어서 계산을 처리하는 방법이 도입된 것이다.
2-2. 병렬처리 방식의 도입

병렬처리는 하나의 대규모 문제를 푸는데 다수의 프로세서가 서로 통신하고 협조하면서 하나의 큰 문제를 세분화하여 초고속으로 해결하는 방법이다. 병렬처리를 위해 둘 이상의 CPU를 가진 컴퓨터를 병렬 프로세서라 하고, 방대한 하드웨어를 가장 효율적으로 움직이는 소프트웨어를 병렬 소프트웨어라고 부른다.
3. 도커(Docker)가 가져온 서버관리 방식의 변화
전통적으로 서버관리 방식은 아래와 같이 각 단계별로 흐름이 있었고, 각 단계가 업데이트 되거나 어떤 문제가 발생하면 전체 흐름이 중단되는 문제가 있었다.
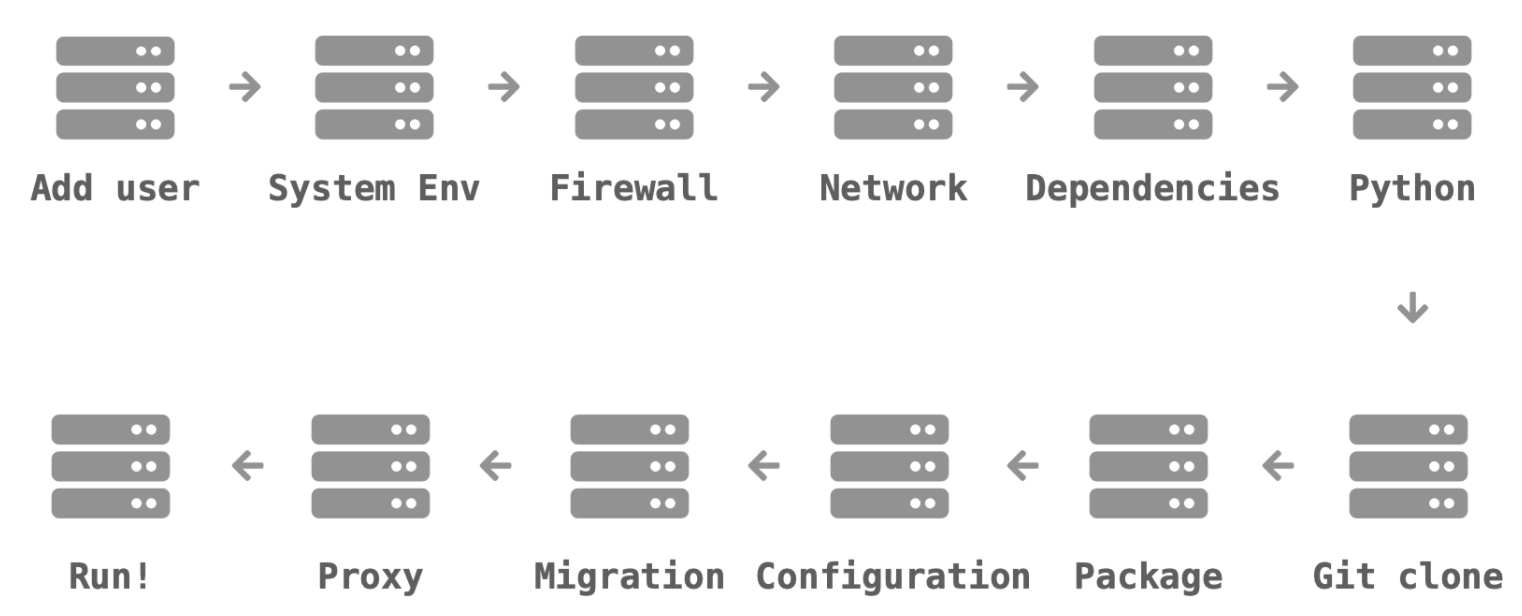
여기서 도커가 등장한 이후에 어떠한 프로그램도 컨테이너로 만들 수 있게 되었다. 서로 다른 프로그램이더라도 컨테이너로 규격화된 것이다! 컨테이너는 AWS, Azure, Google cloud 등 어떤 클라우드 환경에서도 돌아간다.
잠깐, 블록체인에서 EVM(이더리움 가상 머신)이 있는데, 도커는 가상머신과 비슷한점도 있지만 다른점도 있다. 가상머신처럼 독립적으로 실행되지만 가상머신보다 빠르고 쉽고 효율적이다. (가상머신은 EVM을 다루게 되면 추후 포스팅 하겠습니다.)
도커는 컨테이너 기반의 오픈소스 가상화 플랫폼으로 서버관리와 개발 방식에 혁신을 가져다주었다. 도커가 가져온 변화를 6가지로 간단하게 정리해보면, 1. 클라우드 이미지보다 관리하기 쉽다. 2. 다른 프로세스와 격리되어 가상머신처럼 사용하지만 성능 저하가 거의 없다. 3. 복잡한 기술(nameSpace, network...)을 몰라도 사용할 수 있다. 4. 이미지 빌드 기록이 남는다. 5. 코드와 설정으로 관리하여 재현 및 수정이 가능하다. 6. 오픈소스이므로 특정 회사 기술에 종속적이지 않다.
4. 도커(컨테이너)를 관리하는 쿠버네티스
앞서 도커에 대해 장황하게 설명한 이유는 도커를 관리하는 쿠버네티스를 알아보기 위함이었다. 구글에 클러스터를 검색해보면 쿠버네티스에 관련된 글이 잔뜩있는데.. 그래서 나도 찾아보게 된 것! 혹시 지금까지 읽으셨다면 정말.. 칭찬해ㅠㅠ 감사합니당ㅠ 아무튼! 쿠버네티스는 다수의 서버와 다수의 서비스를 관리하기 쉽도록 컨테이너들(도커들)을 관리하는 툴이다. 과거부터 현재에 이르기까지 배포과정의 변화를 살펴보면 다음과 같다.

쿠버네티스가 필요한 이유를 알아보자. 프로덕션 환경에서는 애플리케이션을 실행하는 컨테이너를 관리하고 가동 중지 시간이 없는지 확인해야 한다. 예를 들어 컨테이너가 다운되면 다른 컨테이너를 다시 시작해야 한다. 이 문제를 시스템에 의해 처리하기 위해서는 쿠버네티스만 있으면 된다! 그리고 분산 시스템을 탄력적으로 실행하기 위한 프레임워크를 제공한다. 애플리케이션의 사용자는 급격히 증가할 수도 있고, 많이 없을 때가 있을 수도 있다. 최대 사용자가 100만, 최저 사용자가 100명이라면, 서버비용을 100만에 맞게 내는 건 비효율적이다. 트래픽 과부하도 해소하고, 이에 맞게 적당한 비용만 청구한다는 것은 혁신이라고 생각한다. 또한 자동화된 롤아웃과 롤백, 복구기능은 사용자에게 주는 불편감을 원천봉쇄한다.
5. 쿠버네티스에서 풍기는 클러스터의 향기! 클러스터링이란?
이러한 이유때문에 클러스터를 검색하면 쿠버네티스가 잔뜩 검색되었던 것이다. (검색 알고리즘도 있겠지만..) 마지막으로, 클러스터링이란 여러 개의 서버를 하나의 서버처럼 사용하는 것이다. 작게는 몇 개 안되는 서버부터 많게는 수천 대의 서버를 하나의 클러스터로 사용할 수 있다. 여기저기 흩어져 있는 컨테이너도 가상 네트워크를 이용하여 마치 같은 서버에 있는 것처럼 쉽게 통신한다.
한 줄의 코딩을 완벽히 이해하고 싶은 욕심때문에 늦어졌지만 왠지 뿌듯하다. 내일도 화이팅!
참고문헌: 직렬처리와 병렬처리 방식의 비교, 컴퓨터 클러스터 위키피디아, 공유메모리 위키피디아, 도커란 무엇인가? 블로그, 쿠버네티스, 인프런 QA
