
Combining Two into One Network
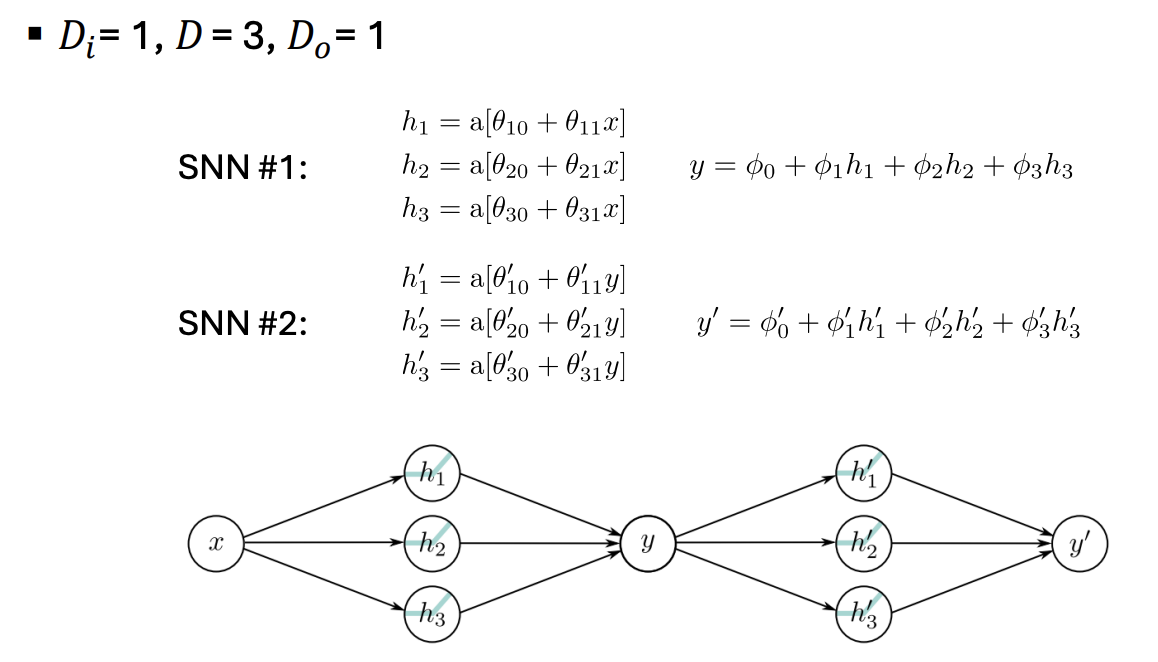
- 전체 구조 요약
- 두개의 신경망 SNN #1과 SNN #2가 연결되어 하나의 네트워크를 이룸
- 흐름 :
x -> SNN #1 -> y -> SNN #2 -> y'
즉, 첫 번째 네트워크 출력 y가 두 번째 네트워크 입력으로 들어감
- 차원 정보
- 입력 차원 :
- 은닉층 노드 수 :
- 출력 차원 :
즉, 구조는 입력 1개, 은닉 노드 3개, 출력 1개
- SNN #1 (첫 번째 신경망)
- 은닉층 계산
특징 :
- 입력 : x
- 각 노드 마다:
-> bias
-> weight - a[] : 활성화 함수
출력 :
- SNN #2 (두 번째 신경망)
-> 구조는 SNN#1과 동일하지만 입력이 y로 바뀜
즉, 이 그림은 하나의 입력 x가 두 개의 신경망을 거쳐 최종 출력 y'로 변환되는 구조이다.
Two-Layer Deep Neural Network
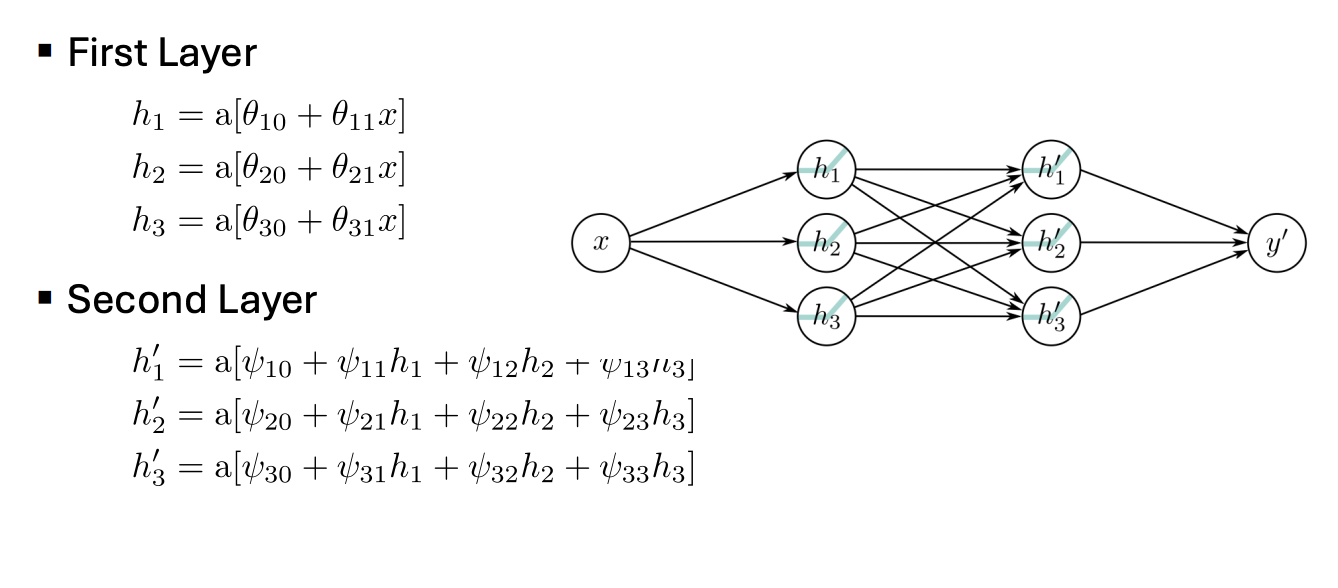
- 전체 구조 요약
- 2개의 레이어(층)로 구성된 신경망
- 흐름 :
x → First Layer → (h₁, h₂, h₃) → Second Layer → (h₁', h₂', h₃') → y'
- First Layer (첫 번째 레이어)
- 계산식
h₁ = a[θ₁₀ + θ₁₁ x]
h₂ = a[θ₂₀ + θ₂₁ x]
h₃ = a[θ₃₀ + θ₃₁ x]
- Second Layer
- 계산식
h₁' = a[ψ₁₀ + ψ₁₁ h₁ + ψ₁₂ h₂ + ψ₁₃ h₃]
h₂' = a[ψ₂₀ + ψ₂₁ h₁ + ψ₂₂ h₂ + ψ₂₃ h₃]
h₃' = a[ψ₃₀ + ψ₃₁ h₁ + ψ₃₂ h₂ + ψ₃₃ h₃]
모든 노드가 서로 연결되어 있는 Fully Connected이다. 각 노드는 이전 레이어의 모든 값을 사용한다.
-> 입력 x가 두 개의 레이어를 거치며 점점 더 복잡하게 변환되는 구조
Hyperparameters
개념 : 신경망에서 학습 과정 동안 학습되지 않는 외부 설정값
즉, 모델이 자동으로 배우는 값이 아닌, 사람이 미리 정해주는 값이다.
- Architectural Hyperparameters
개념 : 구조 관련 하이퍼파라미터
- hidden layer 개수
- hidden unit 개수
- activation function
의미 : 신경망의 모양을 결정하는 요소
- Optimization Hyperparameters
개념 : 학습 과정 관련 하이퍼파라미터
- learning rate
- learning epochs
- batch size
- Loss Function Design
의미 : 모델이 "어떻게 학습할지"를 결정
- Regularization Hyperparameters
개념 : 과적합 방지 관련
- dropout probabilities
- weight decay
의미 : 모델이 과하게 학습되는 것을 막는 설정
SNN vs DNN
좋은 성능은 많은 레이어를 가진 DNN에서 나온다.
레이어 수
대부분의 응용에서, 50 ~ 1000 layers를 사용한다.
즉, 얕은 네트워크 SNN가 아니라, 깊은 네트워크(DNN)가 사용된다.
성능이 좋은 분야
- Computer Vision (CV)
- Natural Language Processing (NLP)
- Graph Neural Networks (GNN)
- Generative models
- Reinforcement Learning (RL)
대부분의 중요한 AI 분야에서는 많은 레이어를 가진 DNN이 더 좋은 성능을 낸다.
얕은 신경망 (SNN)도 어떤 함수든 근사할 수 있지만, 더 정밀하게 만들려면 복잡도가 증가한다.
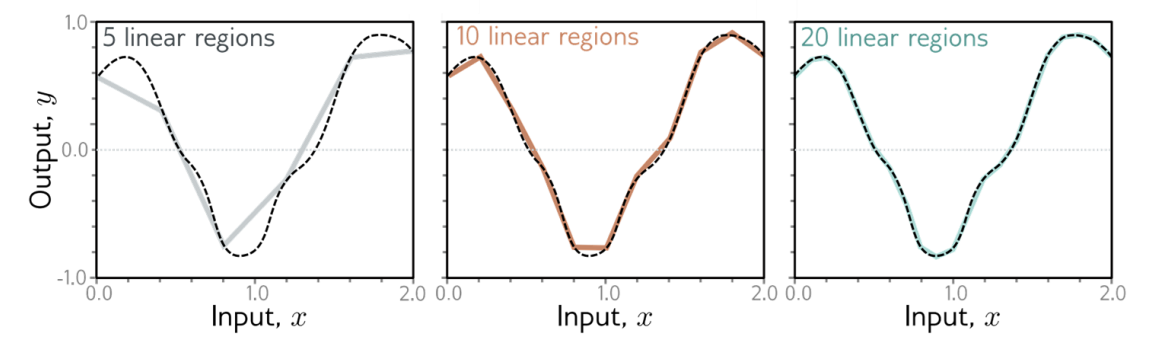
파라미터 수 대비 얼마나 많은 "Linear Region"을 만들 수 있는가?
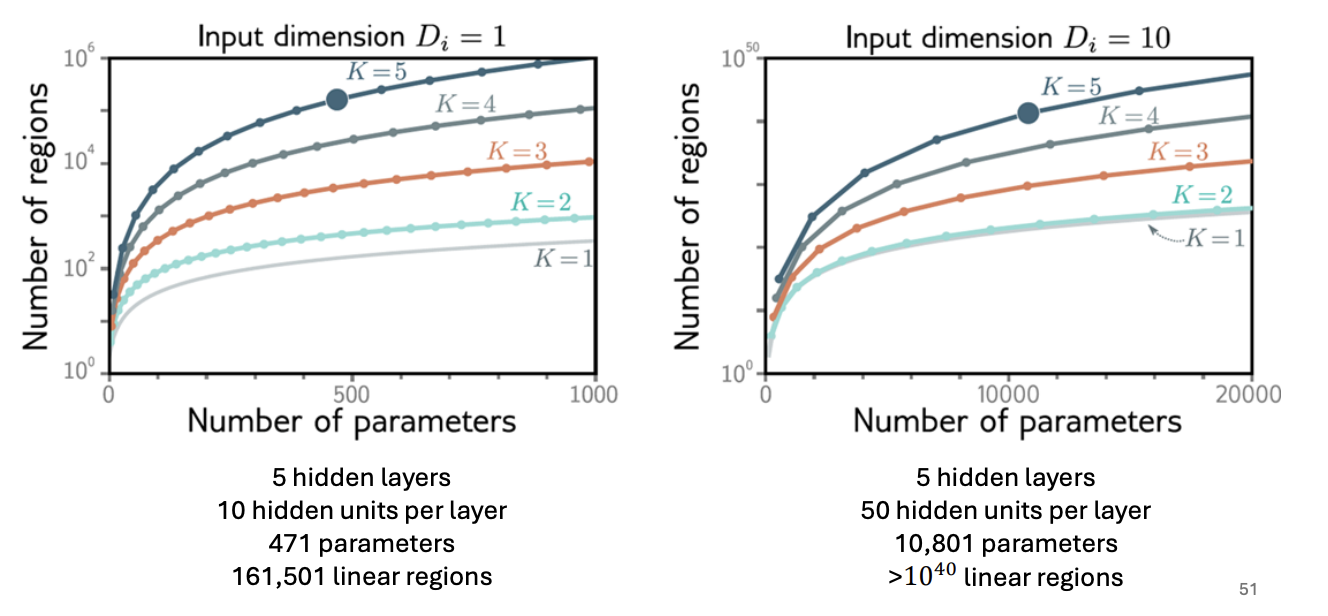
K값이 증가할수록 더 많은 linear region을 생성한다. 레이어가 많아질수록 파라미터 대비 표현력이 폭발적으로 증가한다. 즉, 단순히 파라미터가 많다고 좋은 게 아니라, depth가 중요하다.
DNN은 같은 파라미터로도 훨씬 더 많은 함수 구간(Linear Regions)을 만들어 더 강력한 표현력을 가진다.
Large Structured Networks

- 문제 상황
이미지를 입력으로 생각해보자. (예 : 1000 x 1000 = 1M 픽셀)
의미 :
- 입력 차원이 매우 크다.
-
Fully Connected의 한계
Fully Connected Network는 비현실적이고, 위치 불변성이 없다.
모든 픽셀이 서로 연결되면, 파라미터 수가 너무 많고 위치가 바뀌면 다른 입력으로 취급된다. -
해결 아이디어
가중치는 "local하게만" 작동하고, 이미지 전체에 공유된다
-> Convolutional Networks (CNN) -
핵심 구조
- 작은 영역만 보고, 같은 필터를 전체에 적용한다.

처리흐름 :
Low-Level Feature → Mid-Level Feature → High-Level Feature → Classifier
중요 :
이미지 같은 큰 구조 데이터에서는
단순 SNN이 아니라
구조를 활용한 DNN(CNN)이 필요
