2부 : GNN
우리는 이런 문제를 풀고 싶다.
논문을 분류하려고 한다.
근데, Feature만 보면 애매하다.
-> 근데 논문 인용 관계를 보면?
-> 비슷한 논문끼리 연결되어 있다.
그래서 등장한것이 GNN이다.
논문을 분류한다고 생각해보자.
논문은 단어(Feature)로 표현할 수 있다.
하지만 이것만으로는 부족하다.
왜냐하면, 논문은 서로 인용 관계를 가지기 때문이다.
비슷한 주제의 논문은 서로를 많이 인용한다.
즉, "연결 구조 자체가 정보"다.
-> 이 정보를 활용하는 모델이 바로 GNN이다.
사용할 데이터셋 :
- Cora Dataset
- Facebook Page-Page dataset
Cora Dataset
Cora는 논문 citation 그래프 데이터셋이다.
2008년에 Sen et al. 이 소개 했다.
Cora는 그래프 구조가 강하게 의미를 가지는 데이터다.
그래서, GNN 성능이 크게 향상된다.
논문수 : 2708개
이 의미는
논문 A가 논문 B를 참고했다.
즉,
- 노드 = 논문
- 엣지 = 참고 관계
각 논문은 1433개의 단어 Feature을 가진다.
논문을 이렇게 표현한다.
[0, 1, 0, 0, 1, 1, 0, 0, 0, 1, ...]
길이 = 1433
- 1 : 해당 단어가 존재
- 2 : 해당 단어 없음
이 표현 방식의 이름
이름 : Binary Bag Of Words
자연어 처리(NLP)에서 사용하는 방법이다.
의미 : 문서를 "어떤 단어가 있는지"로 표현하는 방법
우리가 해야 할 목표
목표 : Node Classification
즉, 각 논문을 7개의 카테고리 중 하나로 분류해야 한다.
논문 A -> Neural Networks
논문 B -> Reinforcement Learning
논문 C -> Probabilistic Methods
즉,
Node -> Category
그래프 시각화 이야기
데이터를 이해할때, Visualization가 중요하다.
하지만 문제는 그래프가 커질때,
networkx 같은 Python 라이브러리로는 시각화가 어렵다.
그래서, 전용 그래프 시각화 툴을 사용한다.
1. yED Live
2. Gephi
Cora 그래프 모습
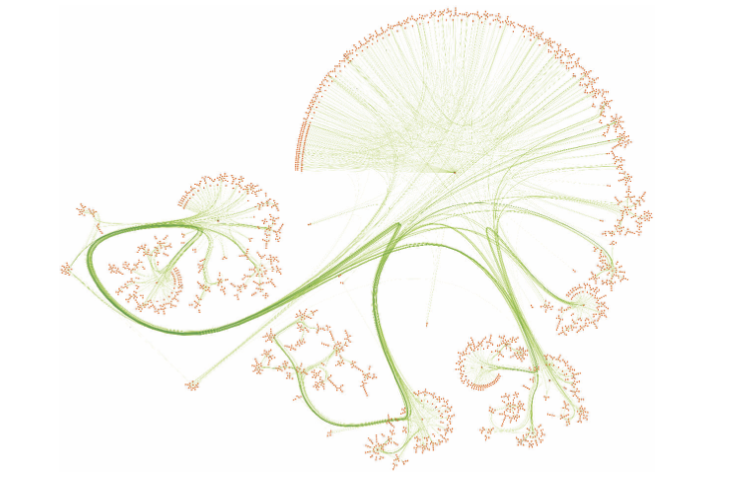
이 그림은 yED Live로 그린 Cora 그래프 이다.
- 노드 (주황색) -> 논문
- 엣지 (초록색) -> Citation
그래프 특징 :
어떤 논문들은 서로 많이 연결되어 있어서 Cluster를 만든다.
Cluster 안에 있는 노드는 분류하기 쉽다. 왜냐하면, 비슷한 논문들이 서로 연결되어 있기 때문이다.
Classifying nodes with Vanilla Neural Networks
Vanilla Neural Network
정의 : 그래프 구조를 쓰지 않고, 노드의 Feature만 가지고 학습하는 모델
기존 그래프 vs Vanilla Neural Network 차이
- 기존 : 그래프 구조 (연결 관계) 중심
- VNN : 노드 자체의 정보 (Feature) 사용
핵심 아이디어
- 노드들을 그래프가 아니라 일반 데이터셋처럼 취급, 즉 tabular dataset으로 본다
학습 방식
- 각 노드는 입력 feature, 정답 label. 그래서 일반적인 신경망 처럼 Node Classification 수행
중요한 한계
- Topology를 전혀 사용하지 않음
MLP vs Vanilla GNN
MLP
import pandas as pd
dataset = Planetoid(root=".", name="Cora")
data = dataset[0]
df_x = pd.DataFrame(data.x.numpy())
df_x['label'] = pd.DataFrame(data.y)
import torch
torch.manual_seed(0)
from torch.nn import Linear
import torch.nn.functional as F
def accuracy(y_pred, y_true):
"""Calculate accuracy."""
return torch.sum(y_pred == y_true) / len(y_true)
class MLP(torch.nn.Module):
"""Multilayer Perceptron"""
def __init__(self, dim_in, dim_h, dim_out):
super().__init__()
self.linear1 = Linear(dim_in, dim_h)
self.linear2 = Linear(dim_h, dim_out)
def forward(self, x):
x = self.linear1(x)
x = torch.relu(x)
x = self.linear2(x)
return F.log_softmax(x, dim=1)
def fit(self, data, epochs):
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(self.parameters(),
lr=0.01,
weight_decay=5e-4)
self.train()
for epoch in range(epochs+1):
optimizer.zero_grad()
out = self(data.x)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
acc = accuracy(out[data.train_mask].argmax(dim=1),
data.y[data.train_mask])
loss.backward()
optimizer.step()
if(epoch % 20 == 0):
val_loss = criterion(out[data.val_mask], data.y[data.val_mask])
val_acc = accuracy(out[data.val_mask].argmax(dim=1),
data.y[data.val_mask])
print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Train Acc:'
f' {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | '
f'Val Acc: {val_acc*100:.2f}%')
@torch.no_grad()
def test(self, data):
self.eval()
out = self(data.x)
acc = accuracy(out.argmax(dim=1)[data.test_mask], data.y[data.test_mask])
return acc
# Create MLP model
mlp = MLP(dataset.num_features, 16, dataset.num_classes)
print(mlp)
# Train
mlp.fit(data, epochs=100)
# Test
acc = mlp.test(data)
print(f'\nMLP test accuracy: {acc*100:.2f}%')MLP(
(linear1): Linear(in_features=1433, out_features=16, bias=True)
(linear2): Linear(in_features=16, out_features=7, bias=True)
)
Epoch 0 | Train Loss: 1.959 | Train Acc: 14.29% | Val Loss: 2.00 | Val Acc: 12.40%
Epoch 20 | Train Loss: 0.110 | Train Acc: 100.00% | Val Loss: 1.46 | Val Acc: 49.40%
Epoch 40 | Train Loss: 0.014 | Train Acc: 100.00% | Val Loss: 1.44 | Val Acc: 51.00%
Epoch 60 | Train Loss: 0.008 | Train Acc: 100.00% | Val Loss: 1.40 | Val Acc: 53.80%
Epoch 80 | Train Loss: 0.008 | Train Acc: 100.00% | Val Loss: 1.37 | Val Acc: 55.40%
Epoch 100 | Train Loss: 0.009 | Train Acc: 100.00% | Val Loss: 1.34 | Val Acc: 54.60%
MLP test accuracy: 53.40%
MLP는 각 노드를 독립적으로 본다.
즉, 논문 A가 어떤 논문과 연결되어 있는지는 전혀 고려하지 않는다. 그래서, 연결 정보를 버리는 셈이다.
Vanilla GNN
class VanillaGNNLayer(torch.nn.Module):
def __init__(self, dim_in, dim_out):
super().__init__()
self.linear = Linear(dim_in, dim_out, bias=False)
def forward(self, x, adjacency):
x = self.linear(x)
x = torch.sparse.mm(adjacency, x)
return x
from torch_geometric.utils import to_dense_adj
adjacency = to_dense_adj(data.edge_index)[0]
adjacency += torch.eye(len(adjacency))
class VanillaGNN(torch.nn.Module):
"""Vanilla Graph Neural Network"""
def __init__(self, dim_in, dim_h, dim_out):
super().__init__()
self.gnn1 = VanillaGNNLayer(dim_in, dim_h)
self.gnn2 = VanillaGNNLayer(dim_h, dim_out)
def forward(self, x, adjacency):
h = self.gnn1(x, adjacency)
h = torch.relu(h)
h = self.gnn2(h, adjacency)
return F.log_softmax(h, dim=1)
def fit(self, data, epochs):
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(self.parameters(),
lr=0.01,
weight_decay=5e-4)
self.train()
for epoch in range(epochs+1):
optimizer.zero_grad()
out = self(data.x, adjacency)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
acc = accuracy(out[data.train_mask].argmax(dim=1),
data.y[data.train_mask])
loss.backward()
optimizer.step()
if(epoch % 20 == 0):
val_loss = criterion(out[data.val_mask], data.y[data.val_mask])
val_acc = accuracy(out[data.val_mask].argmax(dim=1),
data.y[data.val_mask])
print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Train Acc:'
f' {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | '
f'Val Acc: {val_acc*100:.2f}%')
@torch.no_grad()
def test(self, data):
self.eval()
out = self(data.x, adjacency)
acc = accuracy(out.argmax(dim=1)[data.test_mask], data.y[data.test_mask])
return acc
# Create the Vanilla GNN model
gnn = VanillaGNN(dataset.num_features, 16, dataset.num_classes)
print(gnn)
# Train
gnn.fit(data, epochs=100)
# Test
acc = gnn.test(data)
print(f'\nGNN test accuracy: {acc*100:.2f}%')VanillaGNN(
(gnn1): VanillaGNNLayer(
(linear): Linear(in_features=1433, out_features=16, bias=False)
)
(gnn2): VanillaGNNLayer(
(linear): Linear(in_features=16, out_features=7, bias=False)
)
)
Epoch 0 | Train Loss: 2.381 | Train Acc: 7.86% | Val Loss: 2.16 | Val Acc: 18.80%
Epoch 20 | Train Loss: 0.100 | Train Acc: 99.29% | Val Loss: 1.52 | Val Acc: 74.80%
Epoch 40 | Train Loss: 0.007 | Train Acc: 100.00% | Val Loss: 2.29 | Val Acc: 74.00%
Epoch 60 | Train Loss: 0.002 | Train Acc: 100.00% | Val Loss: 2.50 | Val Acc: 74.20%
Epoch 80 | Train Loss: 0.002 | Train Acc: 100.00% | Val Loss: 2.50 | Val Acc: 74.00%
Epoch 100 | Train Loss: 0.002 | Train Acc: 100.00% | Val Loss: 2.46 | Val Acc: 74.20%
GNN test accuracy: 75.10%
MLP는 "논문을 혼자 본다"
GNN은 "논문을 주변과 같이 본다"
adjacency Matrix를 곱하는 의미는,
이웃 노드들의 Feature를 모은다는 뜻이다.
GNN의 핵심은 aggregation이다.
adjacency matrix를 곱하면
각 노드는 자신의 이웃 노드들의 정보를 받게 된다.
즉,
h_i = sum(neighbors of i)
👉 노드는 혼자가 아니라, 주변과 함께 표현된다.
MLP는 53%의 정확도를 보였다.
반면 GNN은 75%까지 상승했다.
👉 단순히 "연결 정보"를 사용했을 뿐인데 성능이 크게 향상되었다.
이게 GNN의 핵심이다.
