1부 : Node2Vec
그래프에서 가장 어려운 문제는 이것이다.
"그래프에서 추천, 분류를 하려면 결국 숫자로 바꿔야 한다.
그럼 노드를 어떻게 벡터로 만들까?"
Node2Vec은 이 문제를 해결하기 위해 등장했다.
Node2Vec은 DeepWalk를 발전시킨 방법이다.
그리고, 이 발전의 핵심은 머신러닝 모델을 더 복잡하게 만든 것이 아니라,
그래프 위를 걷는 방식인 Random Walk를 더 똑똑하게 바꿨다.
일반적인 DeepWalk는 노드의 Sequence를 만들 때, uniform distribution 방식 대신 노드를 선택할때 균등한 확률로 선택하는 방식이다.
Node2Vec에서는 Random Walk가 Biased 되도록 설계되어 있다. 즉, Node2Vec은 특정 방향으로 Biased가 있는 RandomWalk이다.
Neighborhood에서 노드를 어떻게 선택할까
- 우리는 노드 A의 이웃에서 3개의 노드를 탐색하려고 한다.
- 이렇게 노드를 선택하는 방식을 Sampling Strategy 이라고 부른다.
- 첫번째 Sampling Strategy는 연결 기준으로 가장 가까운 3개의 노드를 선택하는 것이다.
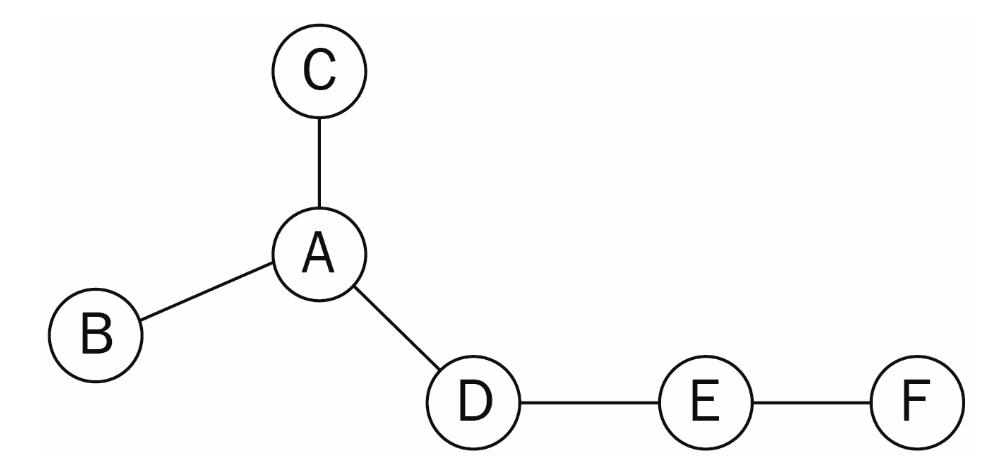
- 노드 A의 이웃은 N(A)라고 할때,첫번째 전략은 다음과 같다.
N(A) = {B, C, D}
이다. 그래프에서 A와 직접 연결된 노드들이 선택된다.
첫번째 전략은 BFS와 관련이 있는데, 노드 주변의 Local Network를 집중적으로 본다.
- 두번째 Sampling Strategy는 이전에 선택된 노드와 인접하지 않은 노드를 먼저 선택하는 방법이다.
N(A) = {D, E, F}
가 된다.
두번째 전략은 DFS와 관련이 있는데, 더 큰 범위의 시야를 제공한다.
두 방법 중 하나만 쓰면 안되는데, 보통 가까운 노드를 찾는다면 DFS보다는 BFS를 더 선호할 것이다. 하지만, Node2Vec의 저자들은 이것은 실수라고 말한다.
BFS와 DFS는 각각 다른 종류의 네트워크 정보를 잡아낸다. 그래서 둘 다 가치가 있다. Node2Vec 논문에서는 BFS/DFS를 두가지 그래프 성질과 연결한다. 노드들이 많은 이웃을 공유하면 그 노드들은 구조적으로 동등하다.
Homophily
정의 : 비슷한 노드들은 서로 연결된 가능성이 높다.
- BFS는 구조적 동등성을 강조하기 좋다. 랜덤 워크에서 노드들이 자주 반복되고, 서로 가까이 유지된다.
- DFS는 Homophily의 반대쪽을 강조한다. 멀리 떨어진 노드들의 시퀀스를 만든다. 그래프의 더 넓은 구조를 탐색하게 된다.
우리는 구조적 동등성과 Homophily 사이의 균형을 찾으려고 한다. 어떤 그래프에서는 homophily가 더 중요할 수 있고, 다른 그래프에서는 구조적 동등성이 더 중요할 수도 있다. Node2Vec에서는 두 샘플링 전략을 모두 사용한다.
Biases in Random Walks
Random Walk는 그래프에서 랜덤하게 선택된 노드들의 시퀀스이다. Random walk는 시작 노드가 있다. 시작 노드 또한 랜덤하게 선택될 수 있다.
Word2Vec과의 연결
Random Walk에서 자주 같이 등장하는 노드들은 문장에서 같이 등장하는 단어와 비슷하다. Homophily 가정에서는 같이 등장하는 노드들은 비슷한 의미를 가진다. 그래서, 비슷한 Representation을 갖게 된다.
Node2Vec의 목표
Node2Vec의 목표는 Random Walk의 랜덤성을 Bias 시키는 것이다. 즉, 랜덤하게 걷지만, 완전히 랜덤이 아니라 특정 방향을 더 선택하도록 만든다.
두가지 방향
- 이전에 방문했던 노드와 연결되지 않은 노드를 더 선택하도록 한다. 이것은 DFS와 비슷한 행동이다. 즉, 그래프에서 더 멀리 탐색하는 방향이다.
- 이전에 방문했던 노드와 가까운 노드를 더 선택하도록 한다. 이것은 BFS와 비슷한 행동이다. 즉, 그래프에서 가까운 노드 위주로 탐색한다.
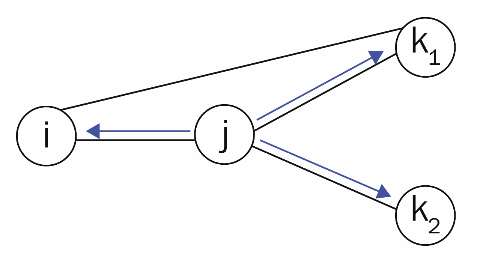
i는 이전 노드이고, j는 현재 노드, k는 다음 노드 후보이다.
이 수식은 노드 j에서 k로 이동할 확률 (정규화 전) 이다.
이 확률의 구성
수식 :
즉, transition probability는 두 요소의 곱이다.
는 search bias, 즉 이동 방향을 조절하는 bias 값이다.
이 것은 j -> k 간선의 weight이다.
즉, 전체 이동 확률은
이동확률 = bias * edge weight
이다.
DeepWalk와 Node2Vec 차이
모든 노드 쌍에서 동일하다.
Node2Vec 값이 노드 사이의 distance, 두개의 파라미터 p와 q에 의해 결정됩니다.
- p : Return Parameter
- q : In-out Parameter
그리고, 이 두 값은 DFS, BFS를 근사하기 위한 역할을 한다고 설명되어 있습니다.
노드거리에 따라, 값이 달라집니다.
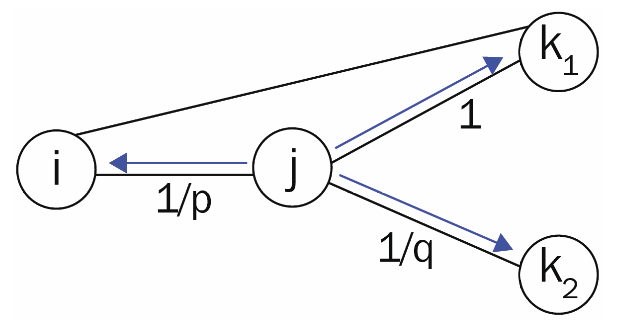
Zachary's Karate Club
import networkx as nx
import matplotlib.pyplot as plt
# Create graph
G = nx.erdos_renyi_graph(10, 0.3, seed=1, directed=False)
# Plot graph
plt.figure()
plt.axis('off')
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
node_size=600,
cmap='coolwarm',
font_size=14,
font_color='white'
)
import random
random.seed(0)
import numpy as np
np.random.seed(0)
def next_node(previous, current, p, q):
alphas = []
# Get the neighboring nodes
neighbors = list(G.neighbors(current))
# Calculate the appropriate alpha value for each neighbor
for neighbor in neighbors:
# Distance = 0: probability to return to the previous node
if neighbor == previous:
alpha = 1/p
# Distance = 1: probability of visiting a local node
elif G.has_edge(neighbor, previous):
alpha = 1
# Distance = 2: probability to explore an unknown node
else:
alpha = 1/q
alphas.append(alpha)
# Normalize the alpha values to create transition probabilities
probs = [alpha / sum(alphas) for alpha in alphas]
# Randomly select the new node based on the transition probabilities
next = np.random.choice(neighbors, size=1, p=probs)[0]
return nextdef random_walk(start, length, p, q):
walk = [start]
for i in range(length):
current = walk[-1]
previous = walk[-2] if len(walk) > 1 else None
next = next_node(previous, current, p, q)
walk.append(next)
return walkrandom_walk(0, 8, p=1, q=1)[0, 4, 7, 6, 4, 5, 4, 5, 6]
p와 q가 균일하면, 그래프 탐색을 보다 효율적으로 한다.
random_walk(0, 8, p=1, q=10)[0, 9, 1, 9, 1, 9, 1, 0, 1]
q가 크면 BFS 쪽으로 그래프 탐색을 시도한다.
random_walk(0, 8, p=10, q=1)p가 크면 DFS 쪽으로 그래프 탐색을 시도한다.
from gensim.models.word2vec import Word2Vec
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load dataset
G = nx.karate_club_graph()
# Process labels (Mr. Hi = 0, Officer = 1)
labels = []
for node in G.nodes:
label = G.nodes[node]['club']
labels.append(1 if label == 'Officer' else 0)
# Create a list of random walks
walks = []
for node in G.nodes:
for _ in range(80):
walks.append(random_walk(node, 10, 3, 2))
# Create and train Word2Vec for DeepWalk
node2vec = Word2Vec(walks,
hs=1, # Hierarchical softmax
sg=1, # Skip-gram
vector_size=100,
window=10,
workers=2,
min_count=1,
seed=0)
node2vec.train(walks, total_examples=node2vec.corpus_count, epochs=30, report_delay=1)
# Create masks to train and test the model
train_mask = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24]
test_mask = [0, 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33]
labels = np.array(labels)
# Train Node2Vec classifier
clf = RandomForestClassifier(random_state=0)
clf.fit(node2vec.wv[train_mask], labels[train_mask])
# Evaluate accuracy
y_pred = clf.predict(node2vec.wv[test_mask])
acc = accuracy_score(y_pred, labels[test_mask])
print(f'Node2Vec accuracy = {acc*100:.2f}%')Node2Vec accuracy = 86.36%
from io import BytesIO
from urllib.request import urlopen
from zipfile import ZipFile
url = 'https://files.grouplens.org/datasets/movielens/ml-100k.zip'
with urlopen(url) as zurl:
with ZipFile(BytesIO(zurl.read())) as zfile:
zfile.extractall('.')import pandas as pd
ratings = pd.read_csv('ml-100k/u.data', sep='\t', names=['user_id', 'movie_id', 'rating', 'unix_timestamp'])
ratings
movies = pd.read_csv('ml-100k/u.item', sep='|', usecols=range(2), names=['movie_id', 'title'], encoding='latin-1')
movies
# Only consider ratings with the highest score
ratings = ratings[ratings.rating >= 4]
ratings
from collections import defaultdict
pairs = defaultdict(int)
# Loop through the entire list of users
for group in ratings.groupby("user_id"):
# List of IDs of movies rated by the current user
user_movies = list(group[1]["movie_id"])
# Count every time two movies are seen together
for i in range(len(user_movies)):
for j in range(i+1, len(user_movies)):
pairs[(user_movies[i], user_movies[j])] += 1# Create a networkx graph
G = nx.Graph()
# Try to create an edge between movies that are liked together
for pair in pairs:
movie1, movie2 = pair
score = pairs[pair]
# The edge is only created when the score is high enough
if score >= 20:
G.add_edge(movie1, movie2, weight=score)
print("Total number of graph nodes:", G.number_of_nodes())
print("Total number of graph edges:", G.number_of_edges())Total number of graph nodes: 410
Total number of graph edges: 14936
from node2vec import Node2Vec
node2vec = Node2Vec(G, dimensions=64, walk_length=20, num_walks=200, p=2, q=1, workers=1)
model = node2vec.fit(window=10, min_count=1, batch_words=4)Generating walks (CPU: 1): 100%|██████████| 200/200 [00:25<00:00, 7.76it/s]
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
Exception ignored in: 'gensim.models.word2vec_inner.our_dot_float'
def recommend(movie):
movie_id = str(movies[movies.title == movie].movie_id.values[0])
for id in model.wv.most_similar(movie_id)[:5]:
title = movies[movies.movie_id == int(id[0])].title.values[0]
print(f'{title}: {id[1]:.2f}')
recommend('Star Wars (1977)')Return of the Jedi (1983): 0.60
Raiders of the Lost Ark (1981): 0.56
Godfather, The (1972): 0.48
Indiana Jones and the Last Crusade (1989): 0.47
Monty Python and the Holy Grail (1974): 0.43
