
Regression
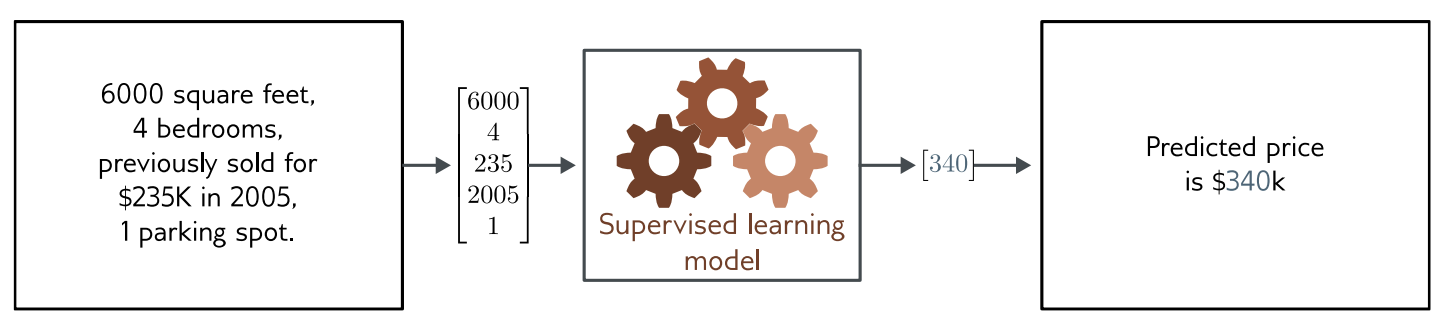
-
전체 흐름
이 그림은 현실 데이터 -> 모델 -> 예측 결과 흐름을 보여준다. -
Real World Input
집에 대한 정보가 들어옴 :
- 6000 square feet (면적)
- 4 Bedrooms (방 개수)
- 2005년에 235K에 판매됨
- 주차 1대 가능
-
Model input
위 정보를 숫자 형태 벡터로 변환 :[6000, 4, 235, 2005, 1]
-
Model (지도학습 모델)
- 입력 데이터를 받아서 출력 값을 계산하는 역할
-
Model output (모델 출력)
[340]
숫자 하나로 결과가 나온다. -
Real world output (현실 출력)
- Predicted price is 340K
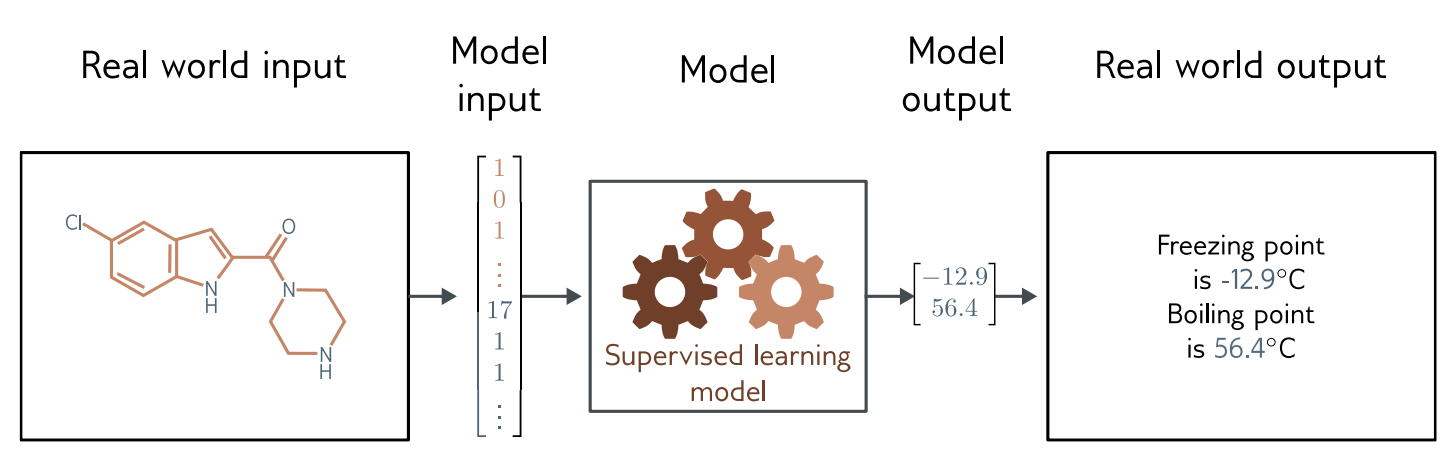
Multivariate Regression
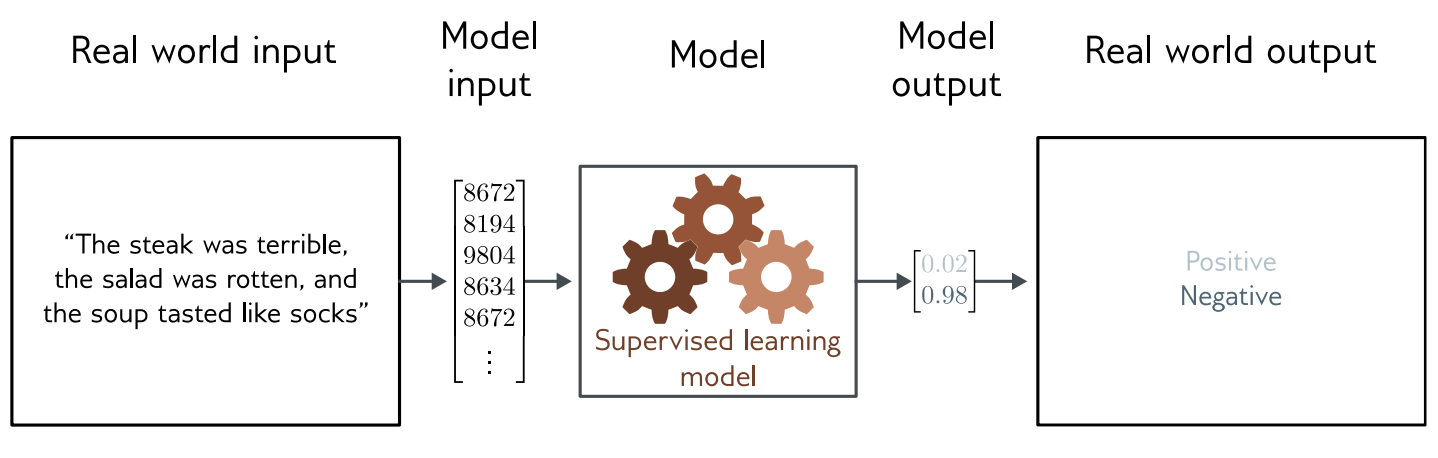
Binary Classification
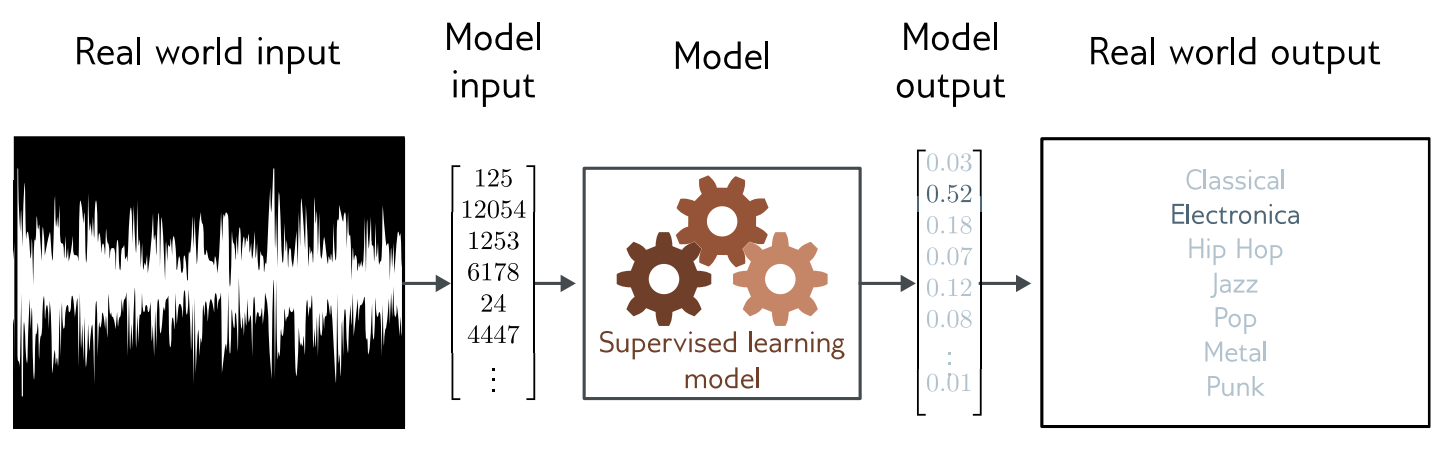
Multiclass Classification
Conditional Distributions of Outputs
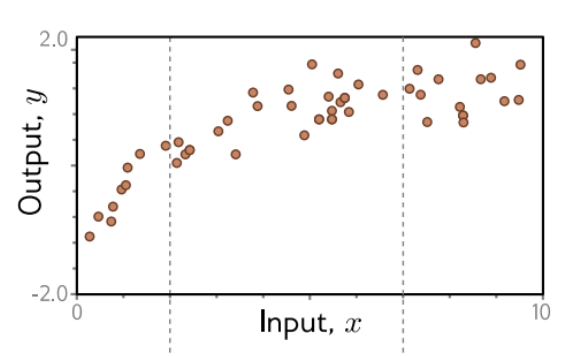
- x축 : Input (x)
- y축 : Output (y)
입력 x에 따라 출력 y 값들이 여러 개 찍혀있다.
중요한 개념
의미 :
- x가 특정 값일 때, y가 어떻게 나오는지의 확률
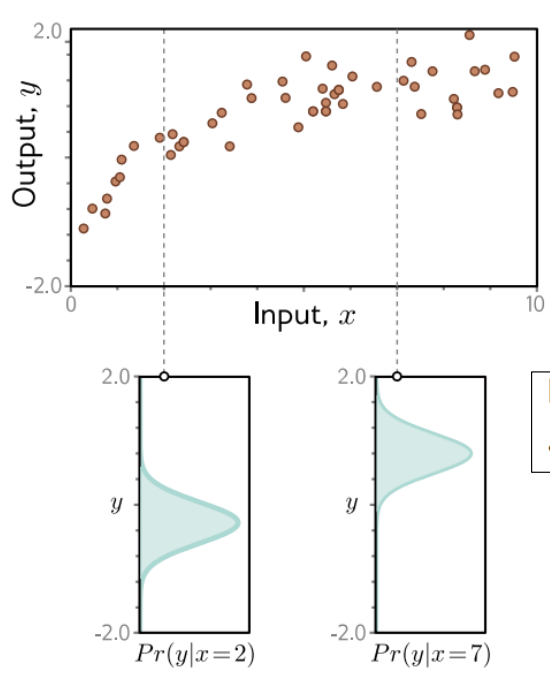
1) Pr(y|x=2)
- x = 2일 때
- y 값들이 하나로 딱 정해지는 게 아니라 분포로 나타남
2) Pr(y|x=7)
- x = 7일때도, y 값이 하나가 아니라 또 다른 형태의 분포를 가짐
Probability (확률)
확률 = 어떤 값이 나올 가능성
Probability Theory : Ability to reason in the presence of uncertainty
의미 : 데이터에는 불확실성이 있고, 그래서 확률을 사용해서 판단해야 함
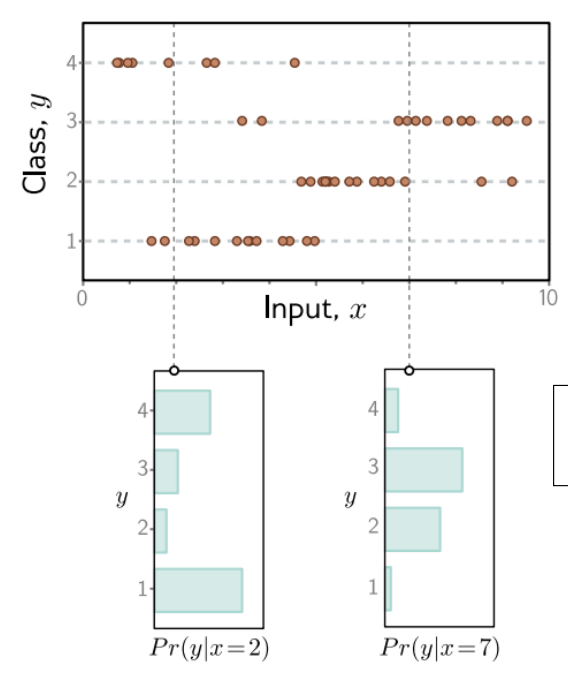
위 이미지는 이산확률분포일때이다.
Conditional Distributions (방향 데이터)
문제상황 : 이번 그림에서는 출력값 y가 일반 숫자가 아니라, 방향이다.
- 범위 :
-π ~ π
즉, 직선 값이 아니라 각도 데이터
기본 개념 :
의미 :
- 특정 입력 x가 주어져을 때 출력 y는 하나가 아니라, 확률 분포로 나타난다.
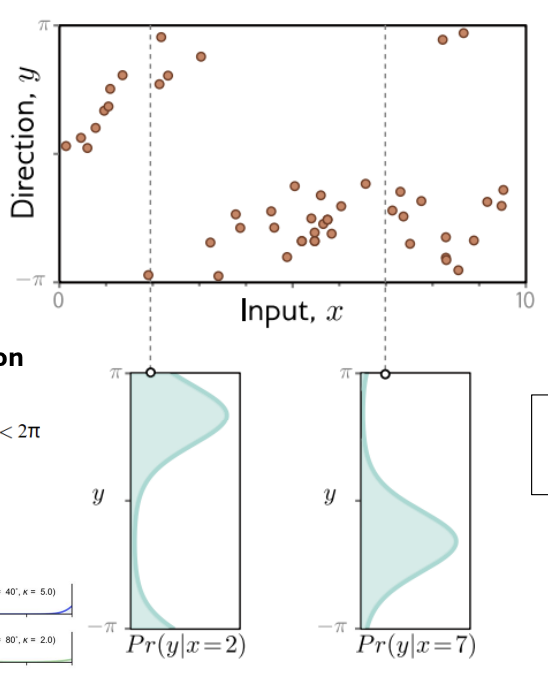
- x : 입력값
- y : 방향 (각도)
Von Mises Distribution
각도 데이터를 위한 확률 분포 :
방향 데이터는 일반 분포가 아니라, 원형 확률 분포를 사용해야 한다.
Loss Function
의미 : 손실함수는 모델이 얼마나 못 맞추고 있는지 측정하는 함수
수식 :
간단하게 쓰면,
결국 손실은 파라미터에 의해 결정된다.
모델 형태
입력 x를 받아서 파라미터로 출력 y를 계산
데이터 구조
그림 해석
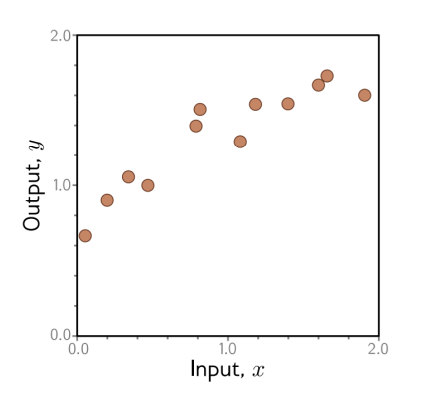
모델은 이 점들을 잘 맞추는 방향으로 학습된다.
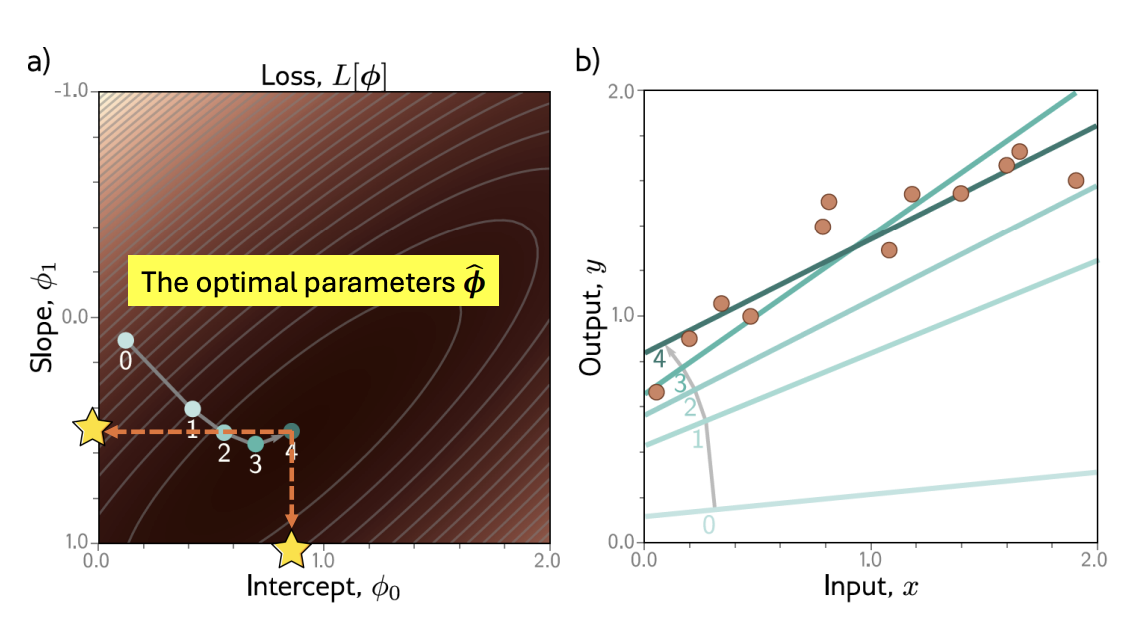
Construct Loss Functions
- 두 가지 모델 관점
❌ (Deterministic) 모델
입력 x가 들어오면 출력 y가 딱 하나로 결정됨
✅ (Probabilistic) 모델
입력 x가 주어졌을 때 출력 y는 하나가 아니라, 확률 분포로 표현됨
-
핵심 차이
| 구분 | Deterministic | Probabilistic |
| -- | ------------- | ------------- |
| 출력 | 하나의 값 | 확률 분포 |
| 형태 | y = f(x) | Pr(y | x) | -
중요한 문장
모델이 예측한 결과가 실제 데이터에서 높은 확률을 가지도록 만드는것
Construct Loss Functions 핵심 아이디어
출력 y를 그냥 숫자로 보는게 아니라, 확률 분포로 모델링 한다.
사용하는 분포 (Gaussian)
확률 분포 식
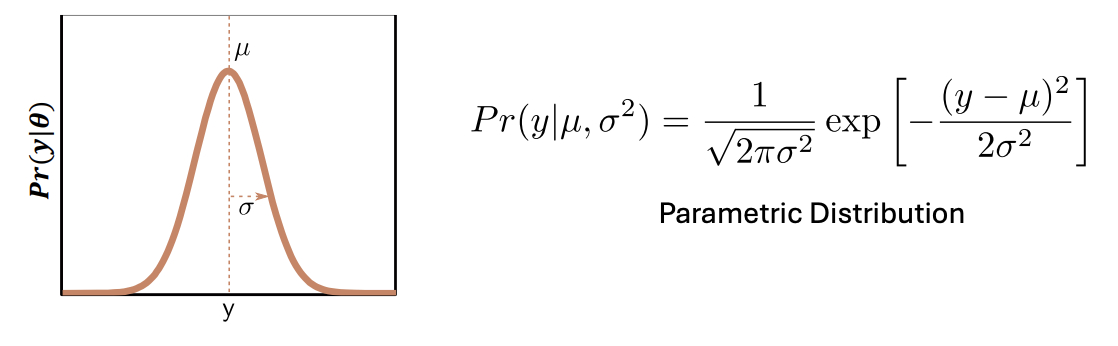
- 종 모양(bell curve) 분포
모델의 역할
모델은 y를 직접 맞추는 게 아니라, y의 확률 분포를 예측한다.
Maximum Likelihood (최대 우도)
핵심 개념 : probability를 파라미터 ϕ의 함수로 보면 -> likelihood
- 어떤 데이터가 가장 잘 나올 것 같은 파라미터를 찾는 방법
"이 데이터가 나왔을 때, 어떤 파라미터가 가장 그럴듯한가?"
의미 :
- 원래 Pr(y|x)는 확률
- 이를 파라미터 ϕ기준으로 보면, likelihood(우도) 라고 부름
모델 & 데이터
의미 :
- 모델은 입력으로 부터 파라미터 생성
- 데이터는 (입력, 정답) 쌍
수식 구조
Model:
Dataset :
수식흐름 :
-> 결국 모델이 만든 출력 기반으로 확률을 계산한다.
MLE = 데이터가 가장 잘 설명되도록 만드는 파라미터 찾기
Independent and Identically Distributed (I.I.D)
핵심개념 :
i.i.d = 독립 + 동일한 분포
-
Independent (독립)
데이터끼리 서로 영향 없다 -
Identically Distributed (동일 분포)
모든 데이터가 같은 규칙에서 생성됨
각 데이터는 서로 영향 없이, 같은 방식으로 생성된다.
MLE 가정 (고딩때 배운 독립시행)
Chain Rule
i.i.d가 하는일
독립으로 만들어서, 모두 곱할수 있게 한다
MLE에 Log를 쓰는 이유
문제 :
- 확률들을 계속 곱하면 0에 가까워진다.
- 컴퓨터가 너무 작은 값을 표현하지 못한다. 0으로 날라간다.
해결 : Log를 쓰자
아까 독립에서의 곱은 합으로 바뀐다.
log함수는 단조 증가 함수라, 최적화 문제도 그대로 유지할 수 있다.
Log Likelihood 최대화 = Loss 최소화
이걸로 경사 하강법으로 학습 할 수 있다.
Inference
모델은 값이 아니라 확률분포를 예측한다. 즉, 확률이 가장 높은 것을 답으로 추론한다.
연습문제
1번
- Choose a suitable probability distribution defined over the domain of the predictions with distribution parameters .
예측값 𝑦가 따르는 확률분포를 하나 선택하고, 그 분포를 결정하는 파라미터 𝜃를 정하라
Answer
2번
- Set the machine Learning model to predict one or more of these parameters, so and $Pr(y|\theta) = Pr(y|f[x, \phi]).
"확률분포의 파라미터 𝜃를 직접 정하는 게 아니라,
입력 𝑥를 받아서 모델 𝑓(𝑥,𝜙)가 예측하도록 만들어라"
Answer
모델 𝑓(𝑥,𝜙)를 사용하여 분포의 파라미터 𝜃를 입력 𝑥의 함수로 정의한다. 즉,
𝜃 =𝑓(𝑥,𝜙)이고, 따라서 𝑃𝑟(𝑦∣𝜃)=𝑃𝑟(𝑦∣𝑓(𝑥,𝜙))로 표현된다.
3번
- To train the model, find the network parameters that minimize the negative log-likelihood loss function over the training dataset pairs :
모델이 예측한 분포가 실제 데이터 𝑦를 가장 잘 설명하도록,
파라미터ϕ를 찾으라
Answer
모델 파라미터 𝜙를 학습하기 위해, 각 데이터에 대한 로그 우도를 최대화하는 대신 음의 로그우도를 최소화한다. 즉, 실제 데이터 𝑦_i가 모델이 예측한 분포에서 높은 확률로 나타나도록 𝜙를 최적화한다.
4번
- To perform inference for a new test example x, return either the full distribution $Pr(y|f[x, \hat{\phi}]) or the value where this distribution is maximized.
학습이 끝난 모델로, 새로운 입력 𝑥가 들어왔을 때
결과 𝑦를 어떻게 뽑을지 정해라
Answer
학습된 모델 𝜙^를 이용하여 새로운 입력 𝑥에 대해 조건부 확률분포 𝑃𝑟(𝑦∣𝑓(𝑥,𝜙^))를 얻고, 그 중 최대 확률을 갖는 𝑦를 예측값으로 선택한다.
