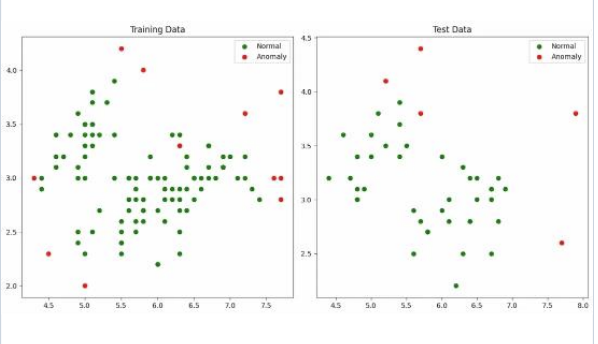
이상치 탐지 (Anomaly Detection)
정의 : 데이터셋에서 정상적인 분포(Normal Distribution) 혹은 패턴에서 현저하게 벗어난 관측치를 식별하는 기법
- Rareness : 발생 빈도가 매우 낮음
- Heterogeneity : 정상 데이터와 다른 생성 메커니즘
이상탐지 및 예측 산업응용 사례
1) 예측 보전
설비 센서 데이터 분석을 통한 고장 징후 조기 포착
2) 품질 관리
제조 공정 중 불량품 자동 검출 및 공정 이상 감지
3) 보안 및 사기
네트워크 침입 탐지 및 카드 부정사용(FDS) 적발
4) 에너지 관리
비정상적인 전력 소비 패턴 감지를 통한 에너지 절감
이상치 탐지 기법의 종류
1) Statistical / Probabilistic
- 데이터 분포를 가정하고 확률 밀도가 낮은 지점을 탐색
- Z-score, GMM, KDE
2) Density-based
- 데이터 포인트 간의 거리나 지역적 밀도를 측정
- k-NN, LOF, DBSCAN
3) Model-based / Boundary
- 정상 데이터의 경계를 학습하거나 나무 구조로 고립
- Isolation Forest, OC-SVM
통계기반 방법 : Z-Score
데이터가 가우시안 분포를 따른다고 가정할 때, 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 계산합니다.
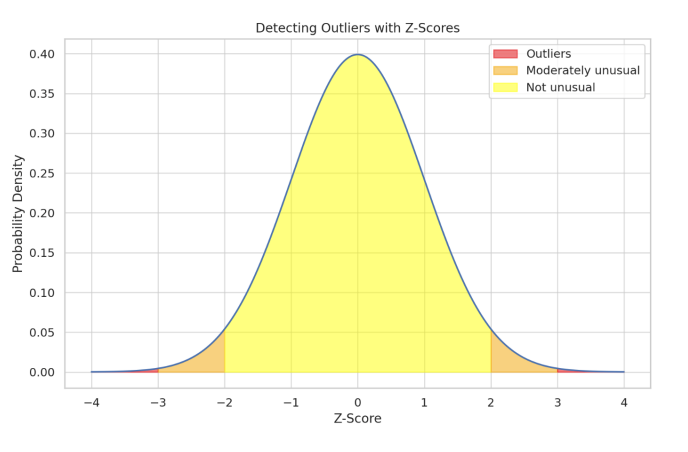
- Decision Rule : 일반적으로 abs(Z) > 3 인 경우 이상치로 판단한다. (99.7% 신뢰구간 이탈)
- 장점 : 매우 빠르고 직관적이다.
- 한계 : 다변량 및 비선형 관계 포착 불가
GMM (Gaussian Mixture Model)
정의 : 데이터가 여러 개의 정규분포(Gaussian)가 섞여서 만들어졌다고 가정하는 모델
"데이터는 여러 개의 종 모양 분포가 섞인 것"
- 특징 :
1) soft clustering(확률로 소속) - K-means : 딱 하나만 속함
- GMM : "A일 확률 0.7, B일 확률 0.3"
2) 타원형 클러스터 가능 - K-means보다 유연함
3) 학습 방법 : EM 알고리즘EM 알고리즘 : 숨겨진 정답을 확률로 추정(E)하고, 그걸로 모델을 다시 학습(M)하는 반복 알고리즘
클러스터링, 데이터 분포 모델링, 이상치 탐지할때 쓴다.
GMM 연습 문제
1) 기초 확률 계산
가우시안 2개가 있다.
데이터 x = 1이 주어졌을때, 각 클러스터에 속할 확률
풀이
정규분포 :
1) 정규분포 값 계산
-
클러스터 1
-
클러스터 2
2) 가중치 곱
=> 0.36
=> 0.00012
3) 확률 정규화
결론 : x = 1은 거의 100%로 클러스터 1에 속한다.
KDE (Kernel Density Estimation)
개념 : 데이터로부터 확률밀도함수 (PDE)를 직접 추정하는 방법
KDE : 데이터 하나당 작은 정규분포(커널) 하나씩 올림
- 각 데이터 포인트 마다 bell curve를 하나씩 올리는데, 그걸 다 더하면 전체분포가 된다.
- 데이터 분포 시각화, 이상치 탐지, 확률밀도추정할때 쓴다.
KDE 연습문제
데이터가 다음과 같다 :
커널 :
평균 :
KNN (K - Nearest Neighbors)
새로운 데이터가 들어왔을때, 가장 가까운 K개의 데이터를 보고, 그들의 정보를 이용해서 예측하는 방법
LOF (Local Outlier Factor)
데이터의 지역적 밀도(Local Density)를 주변 이웃들과 비교합니다. 클러스터마다 밀도가 다를 때 전역적 방식보다 강력합니다.
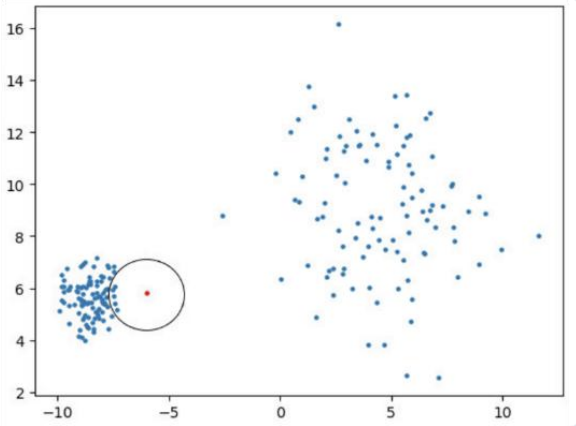
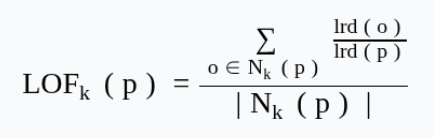
- Ird (p) : Local Reachability Density
- Interpretation : LOF 값이 1보다 훨씬 크면 이상치
LOF 연습문제
데이터 :
k = 2
질문 :
1) D의 k-이웃은 누구인가?
유클리드 거리에서, BD 거리는 9, CD거리는 8로 B와 C가 D의 k-이웃이다.
2) D는 밀도가 높은가 낮은가?
D의 이웃들과의 거리는 8, 9 이러지만 BC는 서로 거리가 1 로 엄청 가깝다. B, C는 밀도가 높고, D는 상대적으로 밀도가 낮다.
3) LOF 값은 1보다 크겠는가 작겠는가?
LOF = 이웃밀도/내밀도
내 밀도는 낮지만 이웃 밀도는 커서 1보다 훨씬 크다.
DBSCAN
개념 : 데이터밀도를 기준으로 클러스터를 찾는 알고리즘
특징 :
- 클러스터 개수 미리 정할 필요 없다
- 이상치 자동 탐지
DBSCAN 연습문제
다음 1차원 데이터가 있다.
DBSCAN의 조건이 다음과 같을 때,
-
각 점이 핵심점(Core Point)인지 판별하시오.
-> 거리 차이가 1 이하이면 이웃이다.
A 이웃 : {A, B}
B 이웃 : {A, B, C}
C 이웃 : {B, C}
D 이웃 : {D} -
어떤 클러스터에 속하는지 판별하시오
Minpts가 2 이상이면 핵심점이므로,
A, B, C가 Core Point 이다. -
Noise인지 판별하시오.
{A, B, C}는 하나의 클러스터가 된다. D는 주변에 연결된 점이 없어서 클러스터에 못들어간다. D는 Noise이다.
Isolation Forest
개념 : 정상 데이터를 프로파일링하는 대신, 이상치를 고립시키는 속도를 측정합니다.
- 이상치는 소수이며 속성이 특이하여 트리 분할 시 적은 횟수(Short Path)만으로 고립됩니다.
- Anomaly Score (s) : 경로 길이 h(x)에 반비례
Isolation Forest 연습문제
어떤 Isolation Forest에서 3개의 데이터 포인트 A, B, C의 평균 경로 길이
E(h(x))가 다음과 같다고 하자.
또한 정규화 상수는 다음과 같다고 하자.
이때 anomaly score
를 이용하여,
1. A, B, C의 anomaly score를 각각 구하여라
-
A의 점수
-
B의 점수
-
C의 점수
- 가장 이상치일 가능성이 큰 점을 고르시오
A가 가장 크므로, A가 이상치일 가능성이 제일 크다.
OC-SVM (One-Class SVM)
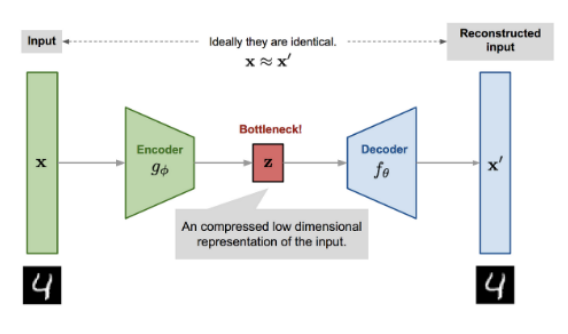
딥러닝 기반 방법 : AutoEncoder
정상 데이터만으로 네트워크를 학습시켜, 입력 데이터를 압축(Encode)후 다시 복원(Decode)하여 오차 측정
Mechanism : 정상 패턴 학습 -> 이상치 입력 시 복원 실패 -> 높은 복원 오차 발생
- 비정형 데이터 (이미지, 시계열) 처리에 매우 효율적임
방법론적 특성
| 분류 | 대표알고리즘 | 핵심 장점 | 주요 한계 |
|---|---|---|---|
| 통계 기반 | Z-score, GMM | 빠른 속도, 해석력 우수 | 복잡한 데이터 대응 한계 |
| 근접도 기반 | LOF | 지역적 밀도 반영 (Local) | 연산 복잡도가 높음 |
| 트리 기반 | Isolation Forest | 대용량 데이터에 효율적 | 고차원에서 성능 저하 기능 |
| 딥러닝 기반 | Autoencoder | 고차원/비선형 패턴 학습 | 학습 시간이 길고 해석 어려움 |
최신 트렌드
-
Explainable AI(XAI) : 단순히 이상치 판정뿐 아니라 "왜" 이상치인지 설명하는 기법이 중요해지고 있음
-
Graph AD : 소셜 네트워크, 금융 사기 탐지 등 관계 중심의 데이터 처리
-
Self-supervised Learning : 라벨 없는 상황에서 모델의 성능을 극대화 하는 기법
데이터의 차원, 용량, 분포를 고려한 최적의 알고리즘 선택이 성공의 열쇠
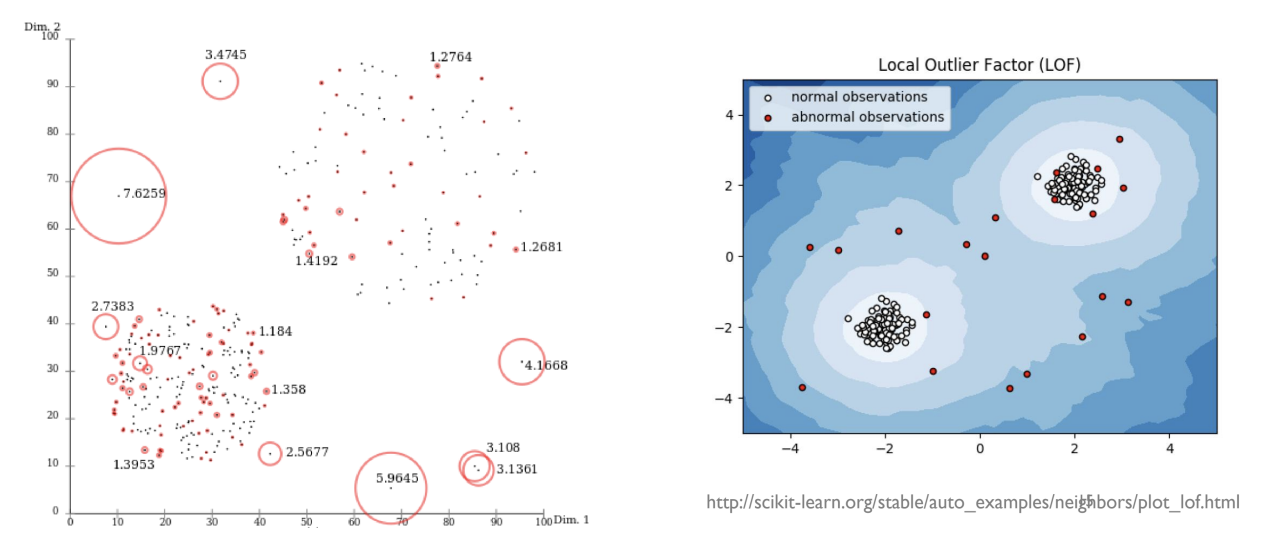
LOF : Identifying Density-Based Local Outliers
의미 : 밀도 기반 이상치 탐지 알고리즘
- 정상 데이터는 지역적으로 서로 비슷한 밀도를 가지는 반면, 이상치는 주변 데이터보다 상대적으로 낮은 밀도를 가진다는 가정을 기반
- 각 데이터 포인트에 대해 k-distance를 계산하여 이웃 집합을 정의한 뒤, 이를 바탕으로 reachability distance(이웃과의 거리 기반 값)와 local reachability density(주변 지역 밀도)를 구하고 마지막으로 LOF (local Outlier factor) 값을 산출함
GLobal Outlier의 한계
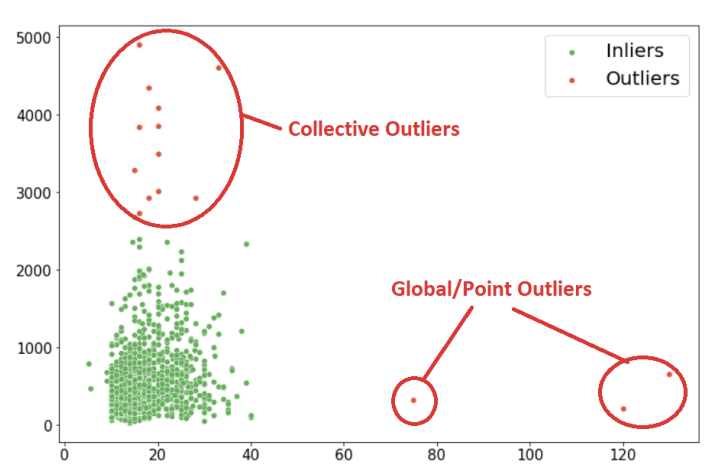
기존의 거리 기반 방식 (k-NN 등)은 전체 데이터 분포에서의 거리만 측정함. 그러나 데이터의 밀도가 서로 다른 여러 클러스터가 존재할 경우, 밀도가 높은 곳의 이상치는 전역적인 거리 기준으로는 발견되지 않을 수 있음
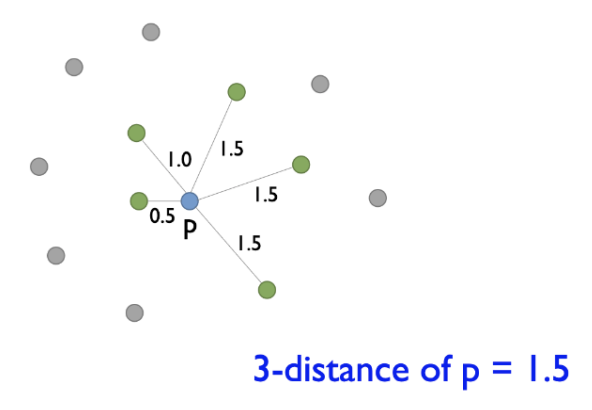
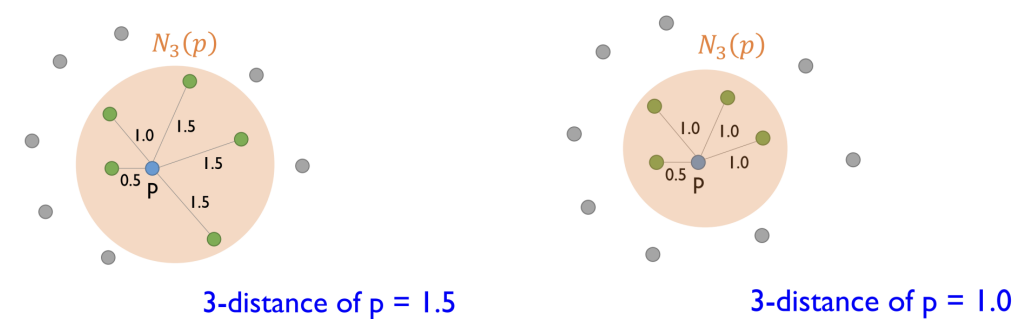
K-Distance
정의 : k-distance of an object p
- 객체 p로부터 k번째 가까운 이웃까지의 거리
- K=3이면 3번째 가까운 점까지의 거리
K-Distance Neighborhood
정의 : k-distance neighborhood of an object p
- P로부터의 거리가 k-distance(p)보다 작거나 같은 모든 점들의 집합
- 거리가 같은 점이 여러 개 있을 경우, 이웃 집합의 수는 K보다 많을 수 있음
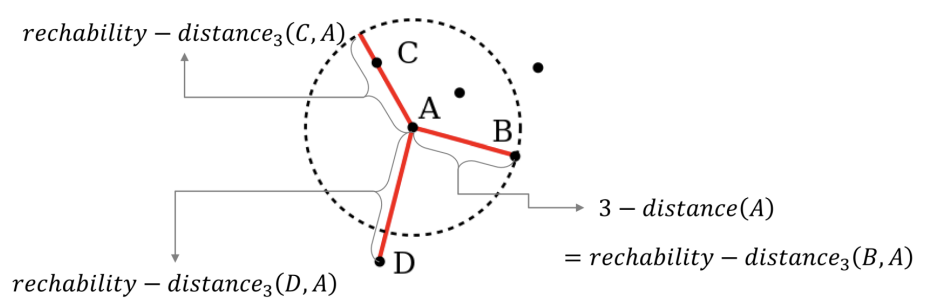
Reachability distance
- 도달가능 거리 : p가 q의 k-distance내에 있는가 측정
- 만약, p가 q의 k-distance내에 있다면 그냥 k-distance (q)로 표시
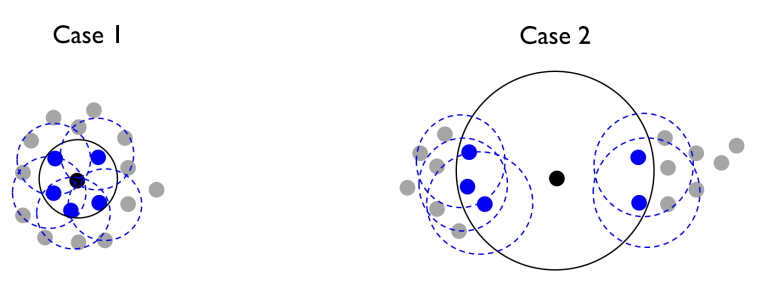
Local reachability density (LRD)
- P에서 이웃들까지의 평균 도달 밀도
- 수식을 보면 평균 도달 거리의 역수임. 거리가 짧을 수록 밀도는 커진다.
Local Outlier Factor (LOF)
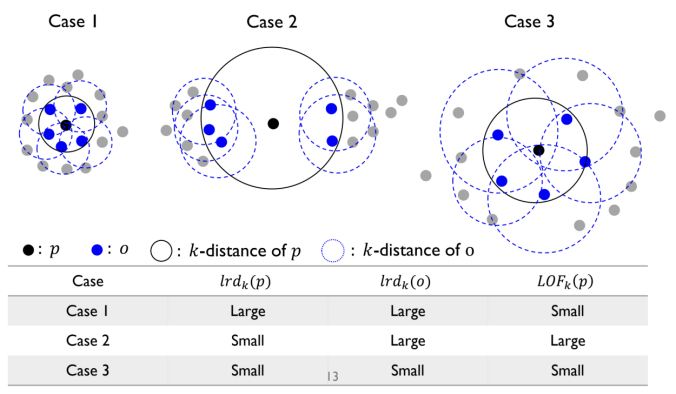
LOF 방식 요약
|단계|계산 내용|결과 의미|
|1|k-distance 파악|주변 반경 확인|
|2|이웃 집합(k-neighborhood) 결정|비교 대상 선정|
|3|Reach-distance 계산|안정된 거리 측정|
|4|Local Reachability density(lrd) 계산|지역적 밀도 산출|
|5|LOF 점수 최종 산출|이상치 여부 판단|
LOP 적용 예제
Isolation Forest
등장 배경 :
- 이상치는 정상 데이터에 비해 개수가 매우 적다.
- 이상치는 정상 데이터와 특성(Feature) 값이 크게 다르다.
이 두 가지 특성 때문에 이상치는 무작위 분할하여 결정 트리를 만들 때 빠르게 고립될 수 있다!!
재귀적 공간 분할
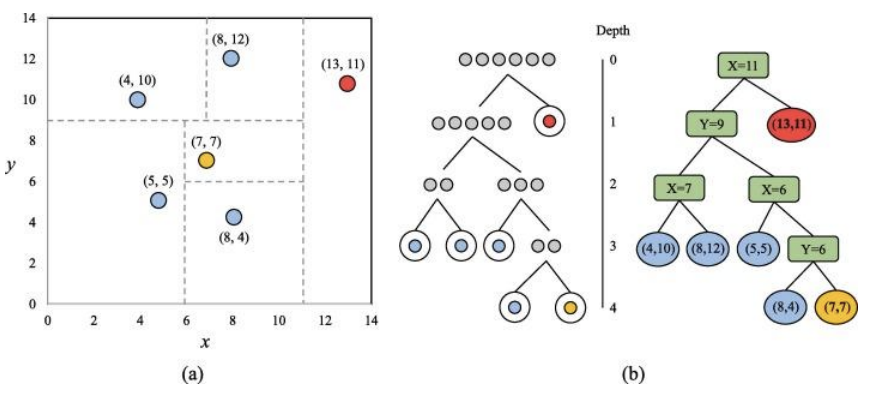
- 무작위 결정 트리 생성
1) 무작위로 변수를 선택
2) 선택한 변수의 최대값과 최소값 사이에서 무작위 분할점 결정
3) 해당 포인트로 공간 분할
4) 데이터가 일정한 수(예를 들어, 한가만 남을때 까지) 과정을 반복
