
Loss Functions
정의 : 모델이 얼마나 못했는지 측정하는 함수이다. 파라미터가 주어졌을때, 성능을 숫자로 평가한다.
General Goal of Optimization Algorithm
머신러닝에서 우리가 궁긍적으로 하고 싶은 것은 모델의 성능을 최대한 좋게 만드는 것이다. 이 목표는 수식으로 다음과 같이 표현된다.
Loss Function의 파라미터로 만든 모델이 데이터에 얼마나 안맞는지를 수치로 표현한 것이다.
Gradient Descent
Gradient Descent는 Loss를 최소화 하는 파라미터를 찾는 대표적인 최적화 알고리즘이다.
기본 설정
-
파라미터 :
-
Loss 함수 :
Step 1 : Gradient 계산
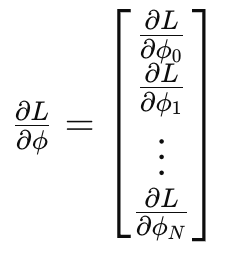
이 벡터는 각 파라미터에 대한 기울기이다.
의미 :
- 각 요소는 이 파라미터를 조금 바꾸면 Loss가 얼마나 편하는지를 보인다.
즉, Loss가 증가하는 방향을 알려주는 벡터이다.
Step 2 : 파라미터 업데이트
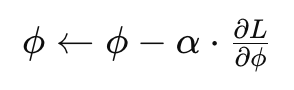
의미 :
기울기의 반대방향으로 이동한다. (내리막 방향)
Gradient 는 가장 가파르게 올라가는 방향이고, 우리는 최소값을 찾는중이다. 즉, 그 반대로 가야 내려간다.
Gradient Descent는 Loss를 줄이기 위해 기울기의 반대방향으로 파라미터를 계속 업데이트하는 방법이다.
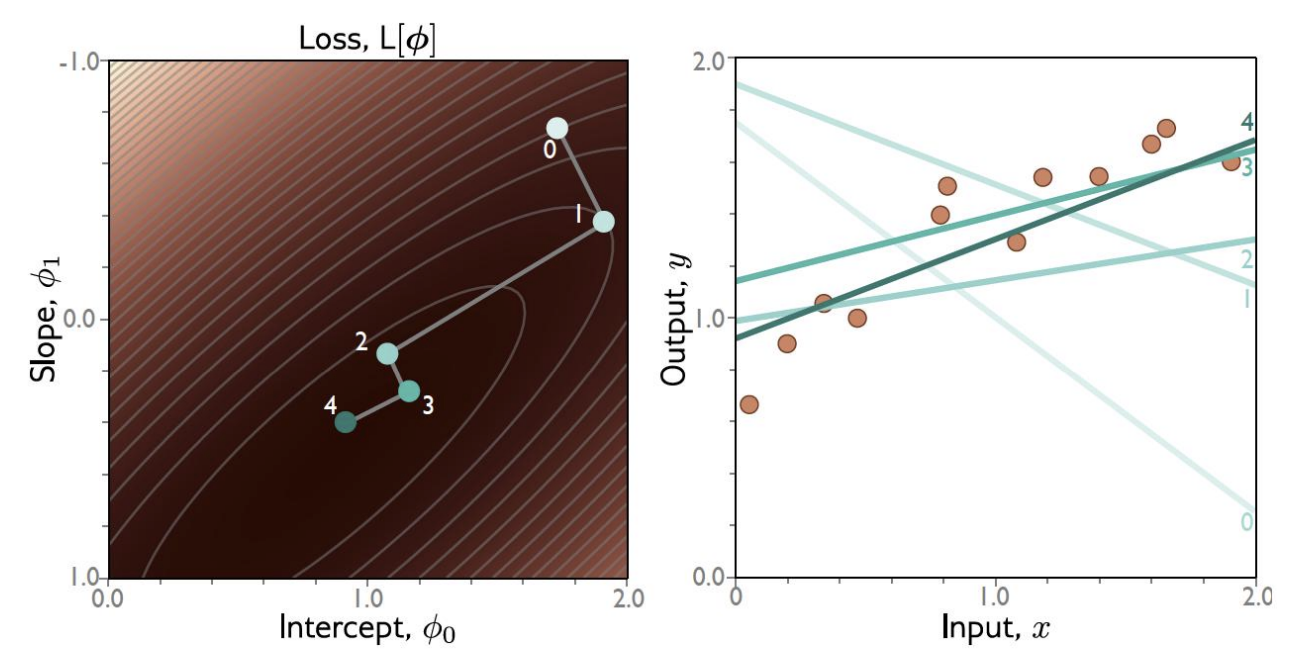
Linear Regression
Step 1. Compute the derivatives of the loss with respect to the parameters:
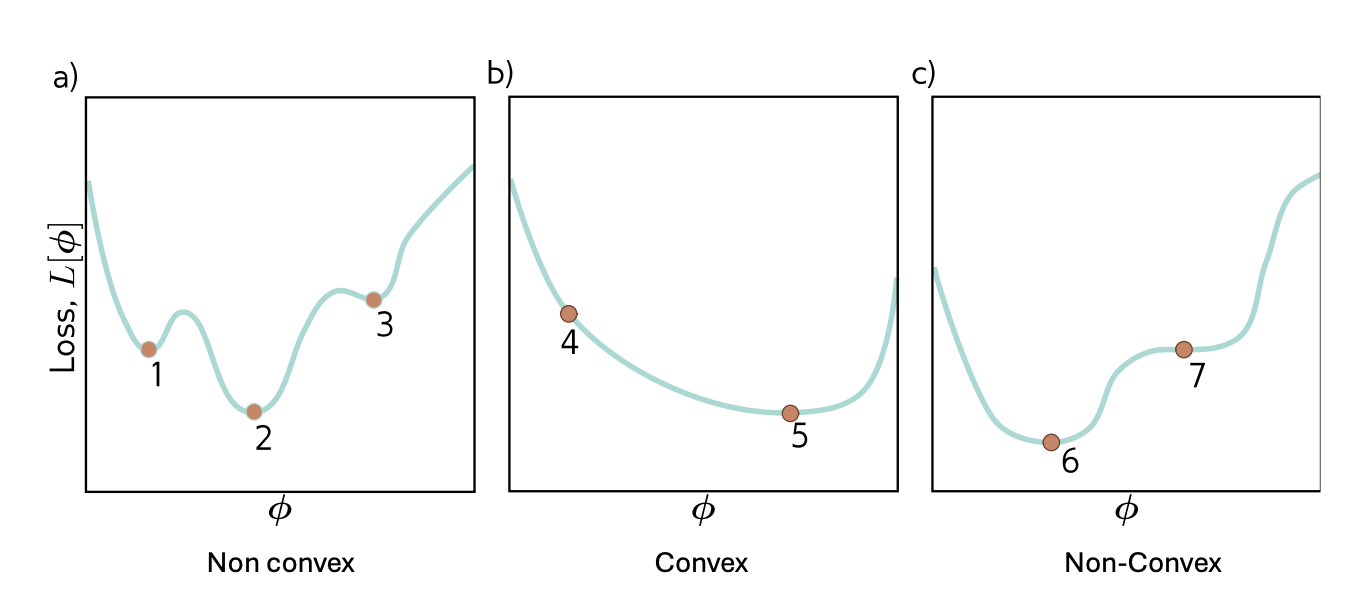
Convexity
Hessian Matrices
Hessian : 2차 미분 모아놓은 행렬
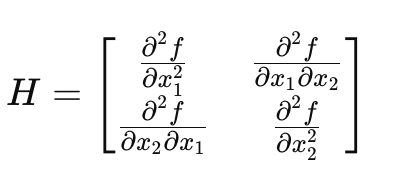
Gradient(1차 미분) = 어디로 가야 내려가는지 방향
Hessian(2차 미분) = 곡률, 얼마나 휘어있는지
고등학교때로 치면 이계도함수 느낌.
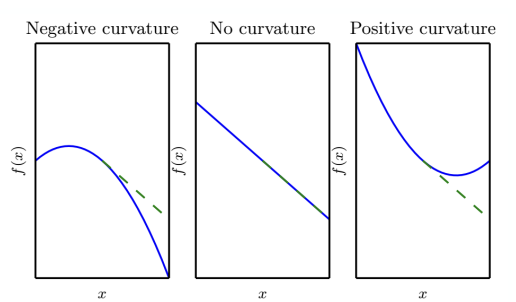
- : 방향 (좌표축 회전)
- : 고유값
Hessian은 결국 각 방향별 곡률을 고유값으로 표현한 것이다. 고유값이 0보다 크면, 아래로 볼록이고, 고유값이 0보다 작으면 위로 볼록형태이다.
고3때는 이차원에서 해서, 이계도 함수하면 하나의 값밖에 나오지 않았지만, 고차원에서는 여러 방향이 있어서, 각 방향마다 따로 고유값이 존재한다. 여기서 위로 볼록인지, 아래로 볼록인지 알수있다.
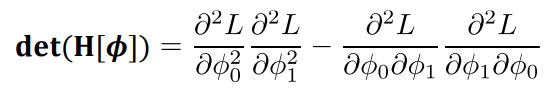
det(H)는 곡률 방향이 통일됐나, 아니면 꼬였나를 판단하는 값이다. 이것은 극값을 판별하는 핵심 수식이다. det(H)가 0보다 크면, 고유값이 모두 같은 부호이고, det(H)가 0보다 작으면, 고유값 부호가 다르다.
