
Gabor Model
Nonlinear Model with two parameters
- 비선형 모델
- 2개의 파라미터가 있다
수식 :
1) sin 함수 부분
이 부분은 진동하는 형태를 만들어 냅니다. 즉, 출력이 위아래로 물결처럼 반복되는 성질을 가지게 됩니다.
2) 지수 함수 부분
이 부분은 진동의 크기를 조절하는 역할이다. 그래프를 보면 진동이 전체 구간에서 똑같이 유지되지 않고, 특정 구간에서 더 크게 나타나고 바깥으로 갈수록 줄어드는 모습이 있는데, 그 형태가 이 항과 연결되어 있습니다.
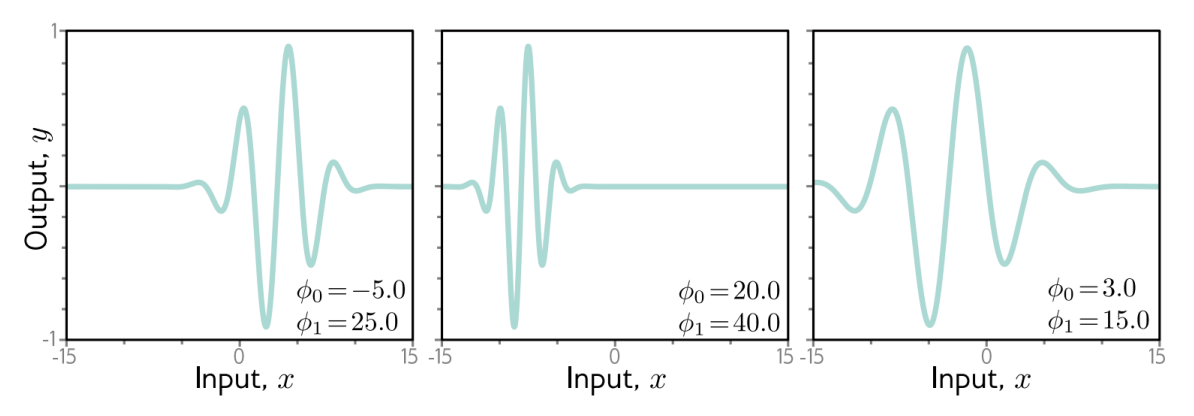
파라미터 값에 따라 그래프 모양이 달라진다.
Gabor Model은 두 개의 파라미터를 가지는 비선형 모델이며, 사인함수와 지수 함수를 결합해 진동하면서도 특정 구간에 집중된 출력 형태를 만든다. 또한 파라미터 값에 따라 진동의 위치와 모양이 달라진다.
, where
이 의미는, 실제 관측값 y는 모델이 만든값 f에 epsilon을 더해서 만들어진다는 뜻이다. 그리고 epsilon은 평균이 0이고 분산이 1인 정규분포를 따른다.
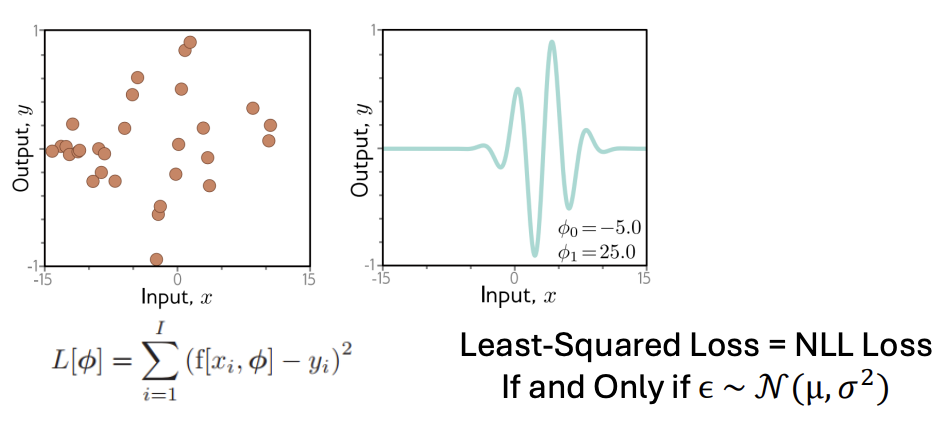
오차가 정규분포를 따른다면, least-squared loss는 MLL loss와 연결된다.
Stochastic Gradient Descent
정의 : 확률적 경사하강법
-
최적화 과정에 노이즈가 들어간다. 즉, 파라미터를 업데이트할 때 완전히 똑같고 결정적인 방향으로만 가는것이 아니라, 어느정도 불규칙성이 섞인다.
-
어떤 지점은 낮아 보이지만 진짜 최저점이 아닐 수 있고, SGD는 noise때문에 그런 곳에 갇히지 않고 더 좋은 곳, 즉 global minimum 쪽으로 갈 가능성이 있다.
Full-Batch GD
수식 :
즉, 모든 데이터 i = 1 부터 I 까지의 gradient를 다 더해서 업데이트하는 형태입니다. Full-Batch GD는 매 step마다 전체 데이터를 사용합니다. 그래서 업데이트 방향이 전체데이터를 기준으로 계산됩니다.
Mini-Batch SGD
Mini 배치는 전체 데이터가 아닌, 현재 배치에 들어있는 일부 데이터만 사용해서 gradient를 계산합니다. 배치 크기는 사용자가 정합니다.
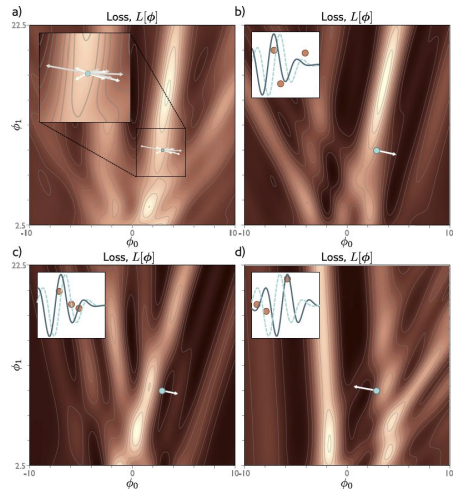
- loss landscape는 단순하지 않다.
- 골짜기처럼 보이는 여러 영역이 있다.
- 어떤 곳은 Local하게 낮아 보여도 global minimum이 아닐 수 있다.
- noise가 섞인 SGD는 이런 복잡한 지형에서 더 유연하게 움직일 수 있다.
SGD의 gradeint가 왜 말이 되는가?
SGD는 전체 데이터 대신 일부 데이터만 사용하므로 업데이트에 noise가 들어간다. 하지만 슬라이드에서는 이 noisy gradient가 unbiased estimate 라는 점을 강조한다. 랜덤하게 선택한 데이터 에 대한 gradient 를 생각하면,
즉, 하나의 샘플로 계산한 gradient는 매번 달라질 수 있지만, 그 기대값은 전체 데이터의 gradient와 같다. 또한 전체 loss는 각 샘플 Loss의 평균으로 표현된다.
SGD는 일부 데이터만 써서 noisy하게 업데이트하지만, 그 gradient의 기대값은 전체 gradient와 같아서 평균적으로 올바른 방향으로 학습한다.
Momentum
Oscillating SGD : SGD가 최적화 과정에서 진동할 수 있다는 문제
이 식은 새로운 값을 을 정의합니다.
구조를 보면,
- 이전의 를 만큼 반영하고,
- 현재 배치 gradient를 만큼 반영합니다.
즉 m은 이전 정보와 현재 gradient를 섞어서 만든 어떤 누적된 방향 정보라고 볼 수 있습니다.
기존 SGD는 현재 gradient만 보고 바로 이동했다면, Momentum은 현재 gradient뿐 아니라 이전까지의 방향 정보도 함께 반영해서 이동합니다. 그래서 업데이트 방향이 더 매끄럽고 안정적이 되도록 하려는 목적이 있다.
