
Problem 3.1 What kind of mapping from input to output would be created if the activation function in equation 3.1 was linear so that What kind of mapping would be created if the activation function was removed, so
equation 3.1:
선형 활성화 함수를 쓰거나 활성화 함수를 제거하면, 신경망 전체는 결국 y = A + Bx 형태의 affine mapping이 되어 비선형 함수를 표현할 수 없다.
Problem 3.2 For each of the four linear regions in figure 3.3j, indicate which hidden units are inactive and which are active (i.e., which do and do not clip their inputs).
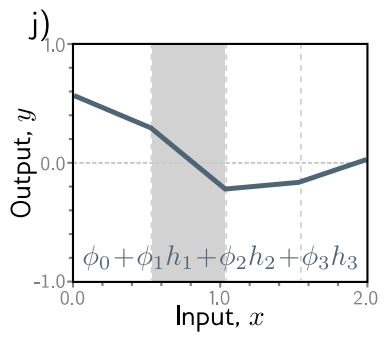
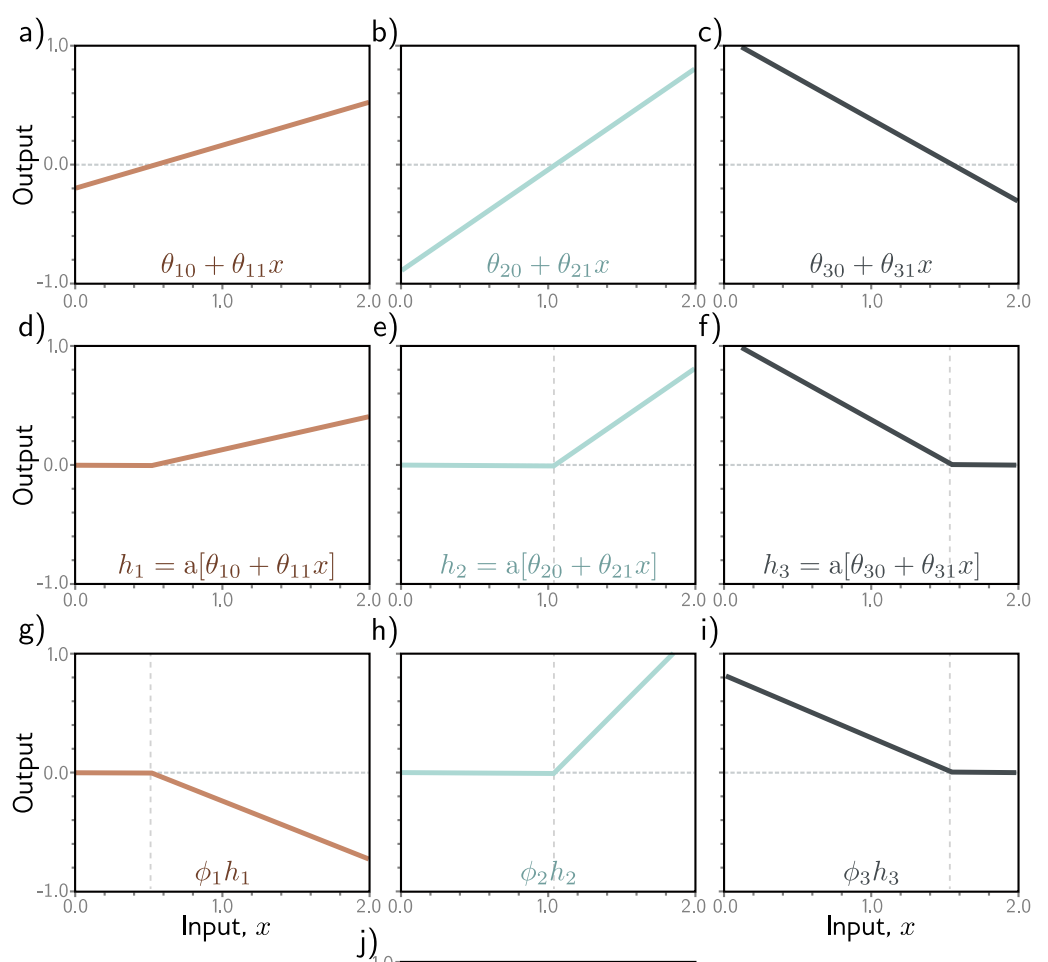
- Region 1:
h1 inactive, h2 inactive, h3 active- Region 2:
h1 active, h2 inactive, h3 active- Region 3:
h1 active, h2 active, h3 active- Region 4:
h1 active, h2 active, h3 inactive
Problem 3.3 Derive expressions for the positions of the "joints" in fuction in figure 3.3j in terms of the ten parameters and the input . Derive expressions for the slopes of the four linear regions.
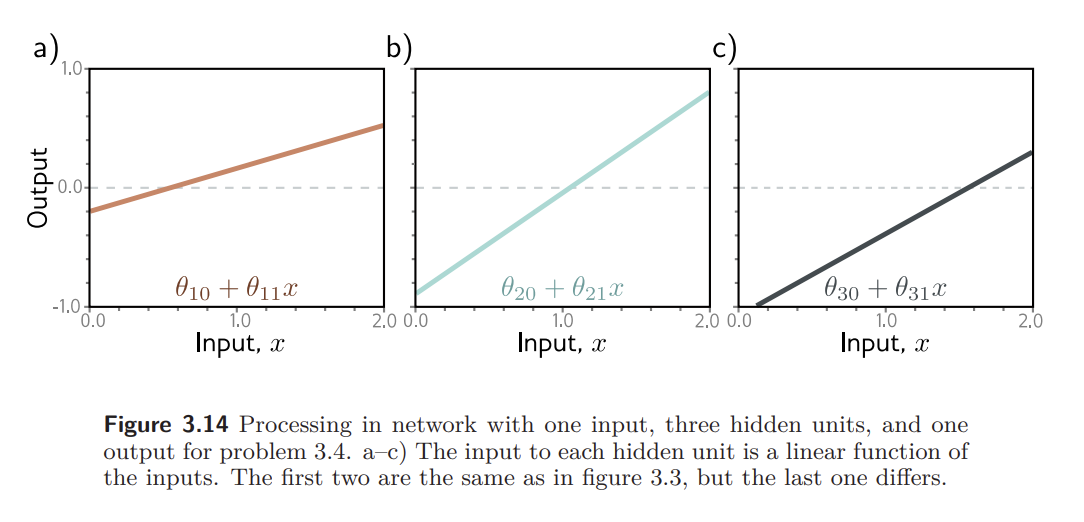
Problem 3.4 Draw a version of figure 3.3 where the y-intercept and slope of the third hidden unit have changed as in figure 3.14c. Assume that the remaining parameters remain the same.
figure 3.3 :
figure 3.14c :
Problem 3.5 Prove that the following property holds for
This is known as the non-negative homogeneity property of the ReLU function.
ReLU(z)=max(0,z)라 하자.
(1) z ≥ 0 이면 ReLU(z)=z 이고, α>0 이므로 αz ≥ 0 이다.
따라서 ReLU(αz)=αz=αReLU(z).
(2) z < 0 이면 ReLU(z)=0 이고, α>0 이므로 αz < 0 이다.
따라서 ReLU(αz)=0=αReLU(z).
따라서 모든 α ∈ R^+에 대하여
ReLU(αz)=αReLU(z)
가 성립한다.
Problem 3.6 Following on from problem 3.5, what happens to the shallow network defined in equations 3.3 and 3.4 when we multiply the parameters and by a positive constant and divide the slope by the same parameter ? What happens if is negative?
equation 3.3 :
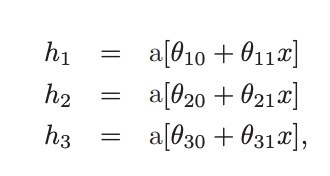
equation 3.4 :
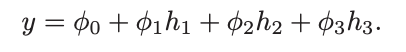
α가 양수일 때는 출력 y가 변하지 않는다.
원래 첫 번째 hidden unit의 항은
φ1 ReLU(θ10 + θ11x)
이다.
여기서 θ10, θ11을 α배 하고, φ1을 1/α배 하면
(φ1/α) ReLU(αθ10 + αθ11x)
= (φ1/α) ReLU(α(θ10 + θ11x))
가 된다.
α > 0 이므로 ReLU의 성질
ReLU(αz) = α ReLU(z)
를 적용할 수 있다. 따라서
(φ1/α) ReLU(α(θ10 + θ11x))
= (φ1/α) · α ReLU(θ10 + θ11x)
= φ1 ReLU(θ10 + θ11x)
가 되어 원래와 같아진다.
즉 첫 번째 hidden unit의 출력 기여가 그대로이므로 전체 네트워크의 출력 y도 변하지 않는다.
반면 α가 음수이면
ReLU(αz) = α ReLU(z)
가 성립하지 않으므로 같은 방식으로 상쇄되지 않는다.
따라서 α < 0 인 경우에는 일반적으로 출력 y가 변한다.
Problem 3.7 Consider fitting the model in equation 3.1 using a least squares loss function. Does this loss function have a unique minimum? i.e., is there a single "best" set of parameters?
equation 3.1:
least squares loss는 일반적으로 unique minimum을 가지지 않는다.
즉, 하나의 “best” parameter set만 존재하는 것이 아니라,
같은 출력을 만드는 여러 다른 parameter 조합이 존재할 수 있다.
특히 ReLU network에서는 한 hidden unit의 내부 파라미터를 양수 α배 하고,
바깥 가중치를 1/α배 하면 전체 출력은 그대로 유지된다.
따라서 서로 다른 parameter set들이 정확히 같은 함수와 같은 loss 값을 만들 수 있다.
즉, 최소 loss를 주는 해가 여러 개 존재할 수 있으므로
이 loss function의 minimum은 일반적으로 unique하지 않다.
Problem 3.8 Consider replacing the ReLU activation function with (i) the Heaviside step function , (ii) the hyperbolic tangent function , and (iii) the rectangular function , where:
Redraw a version of figure 3.3 for each of these functions. The original parameters were: . Provide an informal description of the family of functions that can be created by neural networks with one input, three hidden units, and one output for each activation function.
Problem 3.9 Show that the third linear region in figure 3.3 has a slope that is the sum of the slopes of the first and fourth linear regions.
figure 3.3 :

Problem 3.10 Consider a neural network with one input, one output, and three hidden units. The construction in figure 3.3 shows how this creates four linear regions. Under what circumstances could this network produce a function with fewer than four linear regions?
figure 3.3 :
이 네트워크가 4개보다 적은 linear region을 만드는 경우는,
일부 hidden unit이 새로운 joint(꺾이는 점)를 만들지 못할 때이다.
예를 들어,
1. 어떤 hidden unit이 모든 x 구간에서 항상 inactive이거나 항상 active인 경우
→ 새로운 꺾이는 점을 만들지 못한다.
2. 두 hidden unit의 joint가 같은 x 위치에서 겹치는 경우
→ 원래 두 번 꺾여야 할 것이 한 번만 꺾인다.
3. 어떤 hidden unit이 활성화되거나 비활성화되는 지점에서
전체 기울기가 실제로 변하지 않는 경우
(예: 해당 unit의 출력 가중치가 0이거나, 다른 unit의 변화와 상쇄되는 경우)
→ 그래프상 새로운 linear region이 생기지 않는다.
따라서 hidden unit이 실제로 distinct한 slope change를 만들지 못하면,
이 네트워크는 4개보다 적은 linear region을 가진 함수를 만들 수 있다.
Problem 3.11 How many parameters does the model in figure 3.6 have?
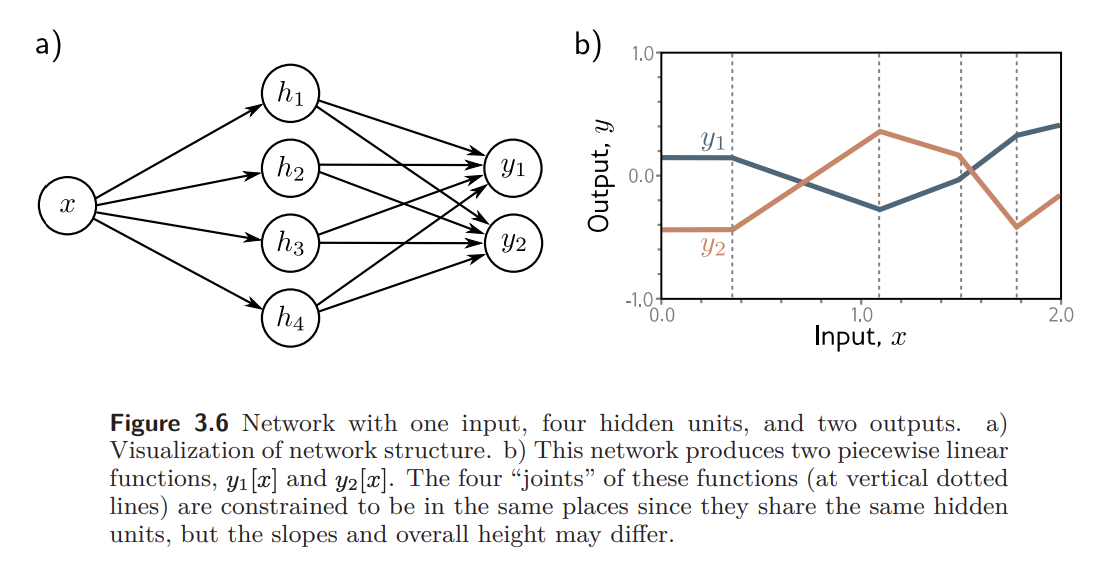
18개
Problem 3.12 How many parameters does the model in figure 3.7 have?
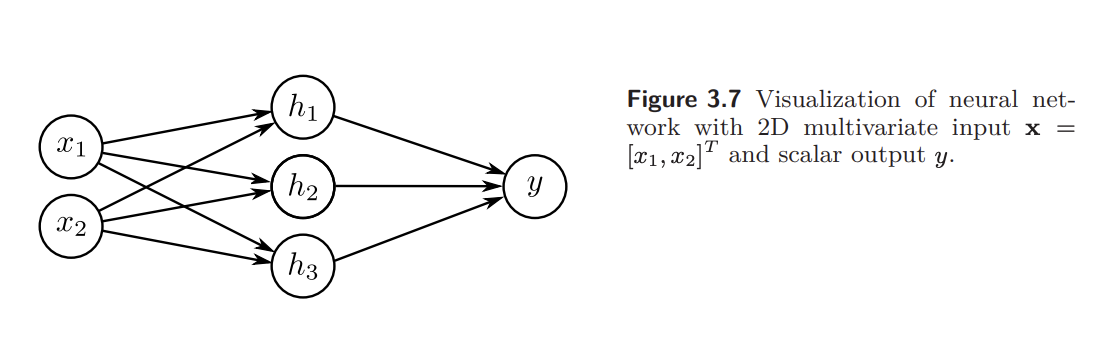
13개
Problem 3.13 What is the activation pattern for each of the seven regions in figure 3.8j? In other words, which hidden units are active (pass the input) and which are inactive (clip the input) for each region?
figure 3.8 :
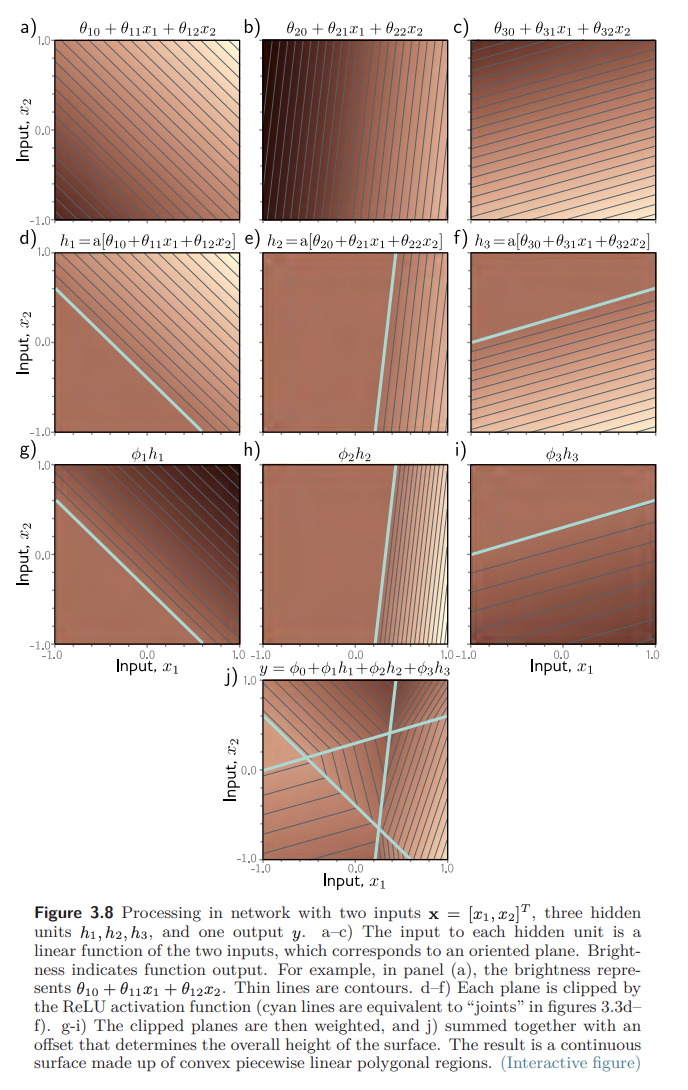
- 왼쪽 아래 영역:
- 왼쪽 가운데 쐐기 영역:
- 왼쪽 위 영역:
- 가운데 영역:
- 오른쪽 아래 작은 영역:
- 오른쪽 가운데 영역:
- 오른쪽 위 영역:
Problem 3.14 Write out the equations that define the network in figure 3.11. There should be three equations to compute the three hidden units from the inputs and two equations to compute the outputs from the hidden units.
figure 3.11 :
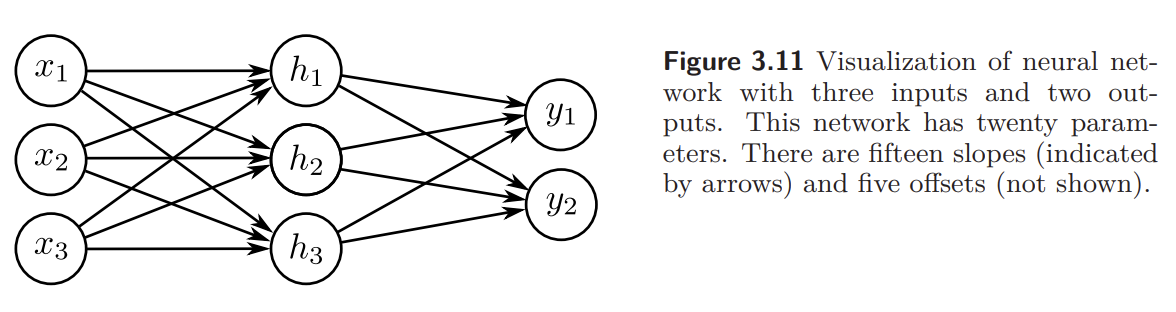
Problem 3.15 What is the maximum possible number of 3D linear regions that can be created by the network in figure 3.11?
figure 3.11 :
8개 (nC0 + nC1 + nC2 + nC3) , n 은 hidden unit의 개수
Problem 3.16 Write out the equations for a shallow network with two inputs, four hidden units, and three outputs. Draw this model in the style of figure 3.11.
figure 3.11 :
Problem 3.17 Equations 3.11 and 3.12 define a general neural network with inputs, one hidden layer containing hidden units, and outputs. Find an expression for the number of parameters in the model in terms of , , and .
equation 3.11 :
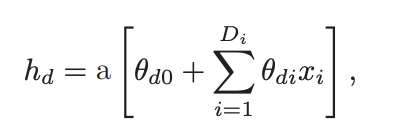
equation 3.12 :
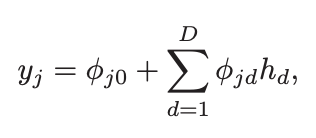
파라미터 개수 :
Problem 3.18 Show that the maximum number of regions created by a shallow network with -dimensional input, -dimensional output, and hidden units is seven, as in figure 3.8j. Use the result of Zaslavsky (1975) that the maximum number of regions created by partitioning a -dimensional space with hyperplanes is . What is the maximum number of regions if we add two more hidden units to this model, so ?
주어진 결과에 따르면, 차원 공간을 개의 hyperplane으로 나눌 때 만들 수 있는 최대 영역 수는
이다.
1. , 인 경우
입력 차원이 2차원이므로,
각 항을 계산하면
따라서, hidden unit이 3개인 shallow network가 만들 수 있는 최대 영역 수는
이다.
즉, figure 3.8j의 7개 영역과 일치한다.
2. hidden unit을 2개 더 추가해서 인 경우
이제 , 이므로,
계산하면
따라서 hidden unit이 5개일 때 만들 수 있는 최대 영역 수는
이다.
최종 답
- , 일 때 최대 영역 수:
- , 일 때 최대 영역 수:
