아니 벌써 연휴 마지막 날?;;
꿀같던 연휴 간 아주 쬐금 공부한 SQL 복습을 위하여 기본 문법 총 정리를 해보았다.
1. 데이터베이스 관리
데이터베이스 생성 및 삭제
- CREATE DATABASE: 새 데이터베이스를 생성
CREATE DATABASE database_name; - DROP DATABASE: 데이터베이스를 삭제
DROP DATABASE database_name;
2. 테이블 관리
테이블 생성 및 삭제
-
CREATE TABLE: 테이블을 생성
CREATE TABLE table_name ( column1 datatype, column2 datatype, ... ); -
DROP TABLE: 테이블을 삭제
DROP TABLE table_name; -
ALTER TABLE: 테이블을 수정 (컬럼 추가, 삭제, 수정 등)
- 컬럼 추가
ALTER TABLE table_name ADD column_name datatype; - 컬럼 삭제
ALTER TABLE table_name DROP COLUMN column_name;
- 컬럼 추가
3. 데이터 삽입, 조회, 수정, 삭제
데이터 삽입
- INSERT INTO: 테이블에 데이터를 삽입
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
데이터 조회
-
SELECT: 데이터를 조회
SELECT column1, column2, ... FROM table_name;- 모든 컬럼 조회
SELECT * FROM table_name;
- 모든 컬럼 조회
-
WHERE: 특정 조건에 맞는 데이터를 조회
SELECT column1, column2 FROM table_name WHERE condition; -
ORDER BY: 데이터를 정렬
SELECT column1, column2 FROM table_name ORDER BY column1 ASC/DESC; -
LIMIT: 조회할 데이터의 개수를 제한
SELECT column1, column2 FROM table_name LIMIT number;
데이터 수정
- UPDATE: 테이블의 데이터를 수정
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
데이터 삭제
- DELETE FROM: 테이블에서 데이터를 삭제
DELETE FROM table_name WHERE condition;
4. 조건문과 연산자
WHERE 조건문
-
=, <, >, <=, >=, <>: 비교 연산자
SELECT * FROM table_name WHERE column1 = 'value'; -
AND, OR: 여러 조건 결합
SELECT * FROM table_name WHERE column1 = 'value1' AND column2 = 'value2'; -
BETWEEN: 값의 범위를 조건으로 설정
SELECT * FROM table_name WHERE column1 BETWEEN value1 AND value2; -
LIKE: 특정 패턴과 일치하는 값을 조회
SELECT * FROM table_name WHERE column1 LIKE 'pattern%'; -
IN: 여러 값 중 하나와 일치하는 데이터를 조회
SELECT * FROM table_name WHERE column1 IN ('value1', 'value2', ...);
5. JOIN: 테이블 간 데이터 결합
-
INNER JOIN: 두 테이블 간 공통된 값을 기준으로 결합
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column; -
LEFT JOIN: 왼쪽 테이블의 모든 데이터와 매칭되는 오른쪽 테이블의 데이터를 결합
SELECT columns FROM table1 LEFT JOIN table2 ON table1.column = table2.column; -
RIGHT JOIN: 오른쪽 테이블의 모든 데이터와 매칭되는 왼쪽 테이블의 데이터를 결합
SELECT columns FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;
6. 집계 함수
-
COUNT(): 행의 개수를 계산
SELECT COUNT(column_name) FROM table_name; -
SUM(): 값들의 합을 계산
SELECT SUM(column_name) FROM table_name; -
AVG(): 값들의 평균을 계산
SELECT AVG(column_name) FROM table_name; -
MAX() / MIN(): 최대값과 최소값을 계산
SELECT MAX(column_name) FROM table_name; SELECT MIN(column_name) FROM table_name;
7. 그룹화 및 필터링
-
GROUP BY: 동일한 값들을 그룹화
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name; -
HAVING: 그룹화된 결과에 조건을 적용
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > value;
8. 서브쿼리
- 서브쿼리: 쿼리 내에 쿼리를 포함
SELECT column_name FROM table_name WHERE column_name = (SELECT MAX(column_name) FROM table_name);
위를 부분 활용하여 실습문제 하나 풀어보겠다.
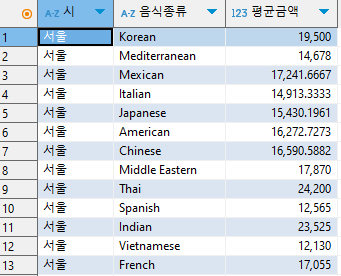
서울 지역의 음식별 평균 주문금액 구하기
여기서 필요한 컬럼은 지역을 뽑아올 수 있는 addr,
음식 종류가 담긴 테이블인 cuisine_type,
주문 금액이 담겨있는 price 가 필요하다.
여기서 우리는 서울시 OO구 OO동의 데이터를 서울만 뽑아내야 한다.
이 때 쓸 수 있는게 substring(컬럼,시작위치,글자수)
substring(addr,1,2) "시" 로 주소를 정제하였다.
다음, 평균 주문금액은 avg(컬럼명) 을 이용하여 구할 수 있다.
여기까지 적어보면,
SELECT substring(addr,1,2) "시", cuisine_type "음식종류", avg(price) "평균금액"
FROM food_orders이렇게 적을 수 있겠다.
이제 여기서 서울 지역이라는 조건이 있으니까 Where절에서 지정해주면
SELECT substring(addr,1,2) "시", cuisine_type "음식종류", avg(price) "평균금액"
FROM food_orders
WHERE addr LIKE '서울%' 위와 같이 적을 수 있고, 마지막으로 그룹핑을 해주게 되면 완성이다.
SELECT substring(addr,1,2) "시", cuisine_type "음식종류", avg(price) "평균금액"
FROM food_orders
WHERE addr LIKE '서울%'
GROUP BY 1,2여기서 GROUP BY 1,2 를 뜻하는 것은 SELECT로 지정한
첫번째와 두번째를 그룹핑 하겠다는 뜻이다.