
스웨거를 보며 API 타입을 사람이 직접 옮겨 적고 있었다. 백엔드 API가 바뀌면 TypeScript 타입을 수정하고, Zod 스키마를 맞추고, 에러 코드를 확인하고, endpoint 상수를 다시 정리해야 했다. 수작업에 의존하면 변경 누락이나 타입 불일치가 생기기 쉽다.
OpenAPI generator를 붙이면 해결될 거라 생각했다. 외부 사례와 라이브러리 옵션을 조사하고 실제로 시도해보니, 핵심은 어떤 라이브러리를 고를 것인가가 아니었다. API 명세에서 생성할 수 있는 코드와 프론트엔드가 직접 해석해야 하는 코드를 어디서 나눌 것인가였다.
API 타입을 옮겨 적는 비용
프론트엔드에서 반복되던 작업은 크게 네 가지였다.
- API 응답과 요청에 맞는 TypeScript 타입 작성
- 런타임 검증을 위한 Zod 스키마 유지보수
- 백엔드 응답에서 에러 코드를 확인해 복사
- endpoint path와 method 상수 관리
백엔드에서 OpenAPI spec을 제공할 수 있다는 논의가 있었고, FSD 구조가 적용된 프로젝트부터는 이 spec을 프론트엔드 코드로 가져오는 codegen 흐름을 도입해보기로 했다. 기대효과는 API 변경사항을 더 빠르게 반영하고 휴먼 에러와 반복 공수를 줄이는 것이었다.
하지만 실제로 진행해보니 API spec의 형태와 프론트엔드 프로젝트 구조 사이를 어떻게 연결할 것인가가 무척 중요했다.
라이브러리에 맡길 일과 직접 다룰 일
목표는 빠르게 OpenAPI generator를 만들고 적용하는 것이었다. 그래서 필요한 기능을 먼저 정리하고, 기본적인 타입과 Zod 스키마 생성은 openapi-zod-client에 맡겼다.
openapi-zod-client는 OpenAPI spec을 기반으로 Zod 스키마와 TypeScript 타입을 함께 생성할 수 있었다. 다만 라이브러리의 기본 산출물만으로는 충분하지 않았다.
CLI로 만들기
별도 CLI로 만든 이유는 단순히 명령어로 실행하고 싶어서가 아니었다. 적용해야 할 프로젝트마다 구조와 규칙이 달랐기 때문이다.
CLI 대신 프로젝트마다 생성 스크립트를 복사해 넣는 방법을 먼저 검토했다.
- 설정을 세 프로젝트에 각각 맞춰야 하고,
- 그 작업을 모두 직접 해야 하며,
- 나중에 로직이 바뀌면 세 곳을 동시에 유지보수해야 한다.
프로젝트가 세 개라면 생성 로직 변경도 거의 세 번 반복되는 구조였다.
그래서 공통 생성 로직은 CLI 패키지로 분리하고, 프로젝트별 차이는 실행 옵션으로 받는 구조를 선택했다.
api-generator --outputDir=src/fsd/shared/generated각 프로젝트의 package.json에는 경로만 다르게 지정하면 된다.
{
"scripts": {
"codegen": "api-generator --outputDir=src/fsd/shared/generated"
}
}모듈 책임 구조
CLI 내부는 runApiGenerator()가 전체 파이프라인을 조립하고 각 단계는 모듈로 나눈 구조다. 각 모듈의 책임은 명확하게 분리했다.
| 모듈 | 역할 |
|---|---|
resolveSpecUrl() | Swagger UI URL을 실제 OpenAPI spec URL로 변환 |
loadSpec() | OpenAPI spec fetch |
SpecParser.parse() | 에러 코드, endpoint metadata 추출 |
CodeGenerator.generate() | openapi-zod-client 실행, 기본 타입/스키마 생성 |
GeneratedCodeTransformer.transform() | 생성 코드 후처리 |
FileWriter.write() | 파일 저장 |
openapi-zod-client는 TypeScript 타입과 Zod 스키마의 기본 생성만 담당한다. CLI는 --template, --output, --export-schemas 옵션으로 이 라이브러리를 호출하고, 나머지는 직접 처리한다.
후처리는 postProcess → applyErrors → applyEndpoints의 고정 순서로, post-processor, error-generator, endpoint-generator 모듈이 각각 담당한다. 흐름 자체는 고정 파이프라인이지만, 각 단계를 모듈로 쪼개두었기 때문에 생성 규칙이 바뀌면 해당 모듈만 교체하면 된다.
한 문장으로 정리하면, ‘OpenAPI에서 스키마와 타입을 안정적으로 뽑는 일’은 라이브러리에 맡기고, ‘우리 프론트엔드 구조에 맞는 계약 산출물로 바꾸는 일’은 CLI가 책임지는 구조다.
열어둔 지점과 닫아둔 지점
확장성을 플러그인 시스템처럼 크게 열어두지는 않았다. 지금 필요한 지점만 옵션으로 열어두었다.
가장 중요한 지점은 --outputDir다. 프로젝트마다 FSD 적용 상태나 generated 디렉터리 위치가 달라서 출력 루트를 CLI 옵션으로 받도록 했다. 템플릿은 내부적으로 교체 가능한 형태지만 공개 옵션으로 열어두지는 않았다. 모든 프로젝트에서의 산출물을 동일하기 위함으로 ‘내부 설계상 교체 가능’이지 ‘공개 확장 API’는 아니다.
반대로 명확히 닫아둔 경계도 있다. CLI는 shared/generated까지만 생성하고 entities/*는 만들지 않는다. OpenAPI spec은 API Spec을 설명하지만, 클라이언트의 모델링 의사결정까지 담고 있지는 않기 때문이다. 그래서 CLI는 생성 완료 후 entity 작업 안내만 출력하고 멈춘다.
에러 코드는 response examples에서 읽기
에러 코드 자동화는 생각보다 까다로웠다. 이상적으로는 백엔드가 도메인별 에러 enum을 명확하게 전달해주면 좋겠지만, 당시 구조에서는 에러 코드를 프론트엔드가 원하는 단위로 별도 제공받기 어려웠다. 이를 위해 서버 구조를 마이그레이션하는 건 현실적으로 볼륨이 너무 컸다.
그래서 서로의 현재 상황에서 타협할 수 있는 방식을 찾았다. 각 operation의 4xx/5xx response examples에 에러 코드와 메시지를 명시하고, 해당 도메인의 전체 에러 코드도 함께 실어두면 프론트엔드에서 이를 읽어 매핑하는 방식이었다.
responses:
'409':
content:
application/json:
examples:
ACCOUNT_ALREADY_REGISTERED:
value:
code: ACCOUNT_ALREADY_REGISTERED
message: 이미 등록된 계정입니다백엔드 입장에서 examples 관리가 부담이 될 수 있다고 걱정했는데, 논의해보니 에러 케이스를 문서화하는 것 자체가 API 설계 과정의 일부라는 점에서 자연스럽게 합의됐다. generator는 이 examples를 읽어서 error code, status, message를 추출하고, operation별 에러정보를 생성한다.
// pperation별 에러 정보 예시
export type DeleteResourceErrorCode =
| 'RESOURCE_NOT_FOUND'
| 'MAIN_RESOURCE_NOT_DELETABLE';
export const ResourceApiErrorMap = {
RESOURCE_NOT_FOUND: { status: 404, message: 'resource missing' },
MAIN_RESOURCE_NOT_DELETABLE: {
status: 409,
message: "can't delete main resource",
},
} as const;generator의 구현보다 API spec에 어떤 정보를 실을 것인가에 가까운 문제였다. codegen은 결국 spec에 있는 정보를 코드로 드러내는 작업이기 때문이다.
generated와 entity를 분리하기
생성 결과물을 어디에 둘지에 대해 고민이 많았다. FSD 구조가 있으면 shared와 entities 레이어는 이미 나뉘어 있다. 하지만 generated 코드를 entities/{domain} 안에 직접 넣을지, shared/generated에 따로 둘지는 여전히 결정이 필요했다.
entities 안에 넣는 방식도 가능했지만, 그렇게 하면 CLI나 AI가 각 프로젝트의 FSD entity 폴더 구조를 직접 이해하고 수정해야 한다. (여기서 AI의 역할은 entity 레이어의 보일러 플레이트를 만들때 사용된다.) auto-generated 코드와 사람이 작업하는 코드 사이의 경계가 흐려지면, 나중에 무엇을 건드려도 되는지 알기 어려워진다.
그래서 명확한 기준을 두었다. shared/generated는 자동 생성된 코드로 사람과 AI가 수정할 수 없는 영역, entities/{domain}은 AI 또는 사람이 자유롭게 작업할 수 있는 영역이다.
shared/generated/ 서버 계약이 바뀔 때 변경, 직접 수정 금지
entities/{domain}/api generated를 수정하지 않고 re-export
entities/{domain}/model 클라이언트 해석이 바뀔 때 변경변경 이유 기준으로 다음처럼 나눴다. OpenAPI spec은 서버 계약이다. 서버가 어떤 요청을 받고 어떤 응답을 주는지는 알 수 있지만, 클라이언트가 그 데이터를 어떻게 해석해서 사용할지는 알 수 없다. 예를 들어 이런 것들은 spec만 보고 결정하기 어렵다.
- snake_case를 camelCase로 바꿀지
- 날짜 문자열을 어떤 포맷으로 변환할지
- 여러 API 응답을 합쳐 클라이언트 모델을 만들지
- UI 전용 computed field를 둘지
이런 결정은 기획, 화면, 프론트엔드 모델링 방식에 따라 달라진다. 따라서 서버 계약에서 나온 generated 코드와 클라이언트 해석이 들어가는 entity 코드는 분리하는 편이 안전하다고 판단했다.
AI Skill은 선택지로만 두기
entity 레이어는 애매한 위치에 있었다. 완전히 결정론적으로 생성하기는 어렵지만, 반복되는 보일러플레이트가 많은 것도 사실이었다.
AI를 필수 자동화로 쓰는 것도 고려했지만, 현재 팀에서 AI 사용 방식이 아직 통일되어 있지 않았다. 모든 작업자가 동일한 방식으로 AI를 활용한다고 보장하기 어려운 상황이었다. AI 사용을 강제하면 오히려 워크플로우가 더 복잡해질 수 있었다.
그래서 이 부분은 필수 자동화가 아니라 선택지로 두었다. codegen이 끝난 뒤 AI Skill에 generated 파일과 FSD 컨벤션을 입력으로 제공하면 entity 보일러플레이트 초안을 만들 수 있게 했다. AI를 쓰지 않아도 shared/generated만 있으면 entity는 직접 작성할 수 있다. AI를 쓰는 경우에도 최종 판단과 수정은 작업자가 한다.
AI가 generator 자체를 대체하지는 않는다. 타입, Zod 스키마, 에러 코드처럼 재현 가능해야 하는 산출물은 CLI가 담당한다. AI는 프로젝트 맥락이 필요한 보일러플레이트 초안을 만드는 보조 도구로만 사용한다.
실제 실행 흐름
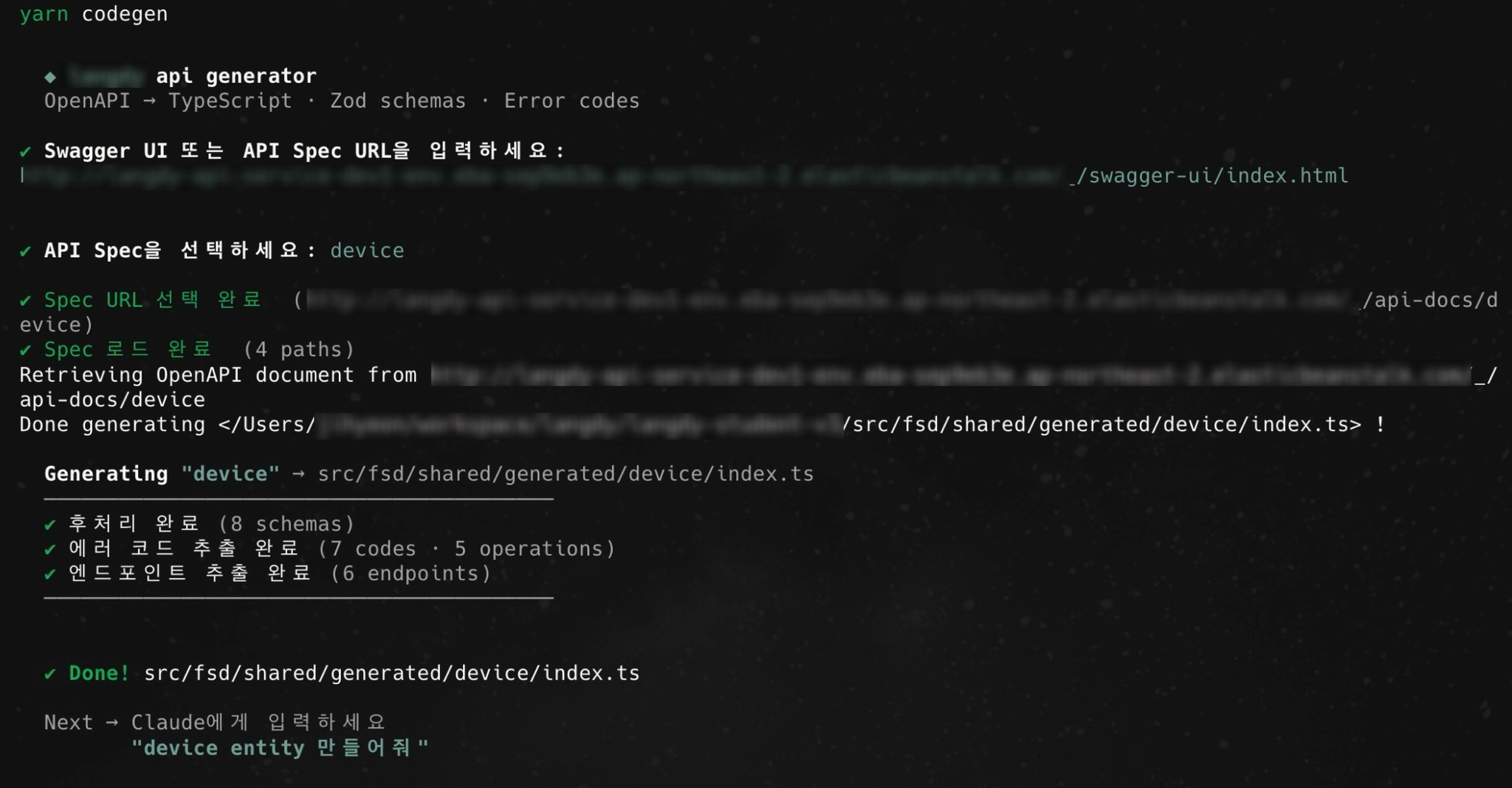
실행하면 먼저 Swagger UI URL을 입력받는다. --url 옵션으로 넘기면 바로 사용하고, 없으면 CLI가 직접 물어본다.
$ yarn codegen
? Swagger UI 또는 API Spec URL을 입력하세요: (*예시 URL 제공*)URL에 urls.primaryName=resource 같은 쿼리스트링이 있으면 바로 spec URL로 변환해 생성을 시작한다. 없으면 swagger-config를 읽어 선택지를 띄운다.
? API Spec을 선택하세요:
❯ resource
account
session선택이 끝나면 파싱, 생성, 후처리, 저장이 순서대로 실행된다.
✔ Spec URL 선택 완료 (*Spec URL*)
✔ Spec 로드 완료 (4 paths)
Retrieving OpenAPI document from *Spec URL*
Done generating *파일 생성 위치* !
Generating "resource" → src/fsd/shared/generated/resource/index.ts
─────────────────────────────────────────
✔ 후처리 완료 (8 schemas)
✔ 에러 코드 추출 완료 (7 codes · 5 operations)
✔ 엔드포인트 추출 완료 (6 endpoints)
─────────────────────────────────────────
✔ Done! src/fsd/shared/generated/resource/index.ts
Next → Claude에게 입력하세요
"resource entity 만들어줘"yarn codegen 한 번으로 아래와 같은 파일이 생성된다.
// AUTO-GENERATED — DO NOT EDIT
export const ResourceSchema = z.object({
// ...
});
export type Resource = z.infer<typeof ResourceSchema>;
export const ResourceErrorCodeSchema = z.enum([
'RESOURCE_NOT_FOUND',
'MAIN_RESOURCE_NOT_DELETABLE',
]);
export type GetResourceDetailErrorCode = 'RESOURCE_NOT_FOUND';
export const RESOURCE_ENDPOINTS = {
getResourceDetail: {
method: 'GET',
path: '/v1/resources/{resourceId}',
pathParams: ['resourceId'],
},
} as const;생성된 파일은 직접 수정하지 않는다. spec이 바뀌면 다시 codegen을 실행해 덮어쓴다. CLI는 여기까지만 만들고 끝낸다. entity 레이어는 자동 생성하지 않고, 후속 작업 안내만 출력한다.
구현하며 확인한 제약
Spring OpenAPI spec에서는 path parameter가 path-level이 아니라 operation-level에 반복 정의되어 있었다.
/resources/{resourceId}:
get:
parameters:
- name: resourceId
in: path
delete:
parameters:
- name: resourceId
in: path확인해보니 Spring 기반 OpenAPI 생성에서 자연스럽게 나오는 형태였고, path-level parameter로 변경하려면 별도 커스터마이징이 필요했다. 현재는 그 방향으로 변경할 계획이 없었기 때문에 generator도 inline parameter를 읽는 방식으로 구현했다.
또한 현재 구현은 $ref로 연결된 response examples나 parameters를 제한적으로만 다룬다. 백엔드 spec이 inline 위주라 실제로 걸리는 케이스는 없지만, spec 관리 방식이 바뀌면 다시 손봐야 하는 부분이다.
마무리
이 흐름은 특정 프로젝트에 먼저 적용한 상태이고, 모든 서비스에 정착된 표준 워크플로우는 아니다. spec versioning이 없어 최신 여부를 자동 판단하기 어렵다는 점은 남아 있는 한계다. entity 생성 이후 단계는 CLI가 개입하지 않지만, 컨벤션 문서와 AI Skill을 입력으로 제공하면 보일러플레이트 초안을 만들 수 있고, 직접 작성하더라도 컨벤션 문서로 기준을 맞출 수 있다.
이번 작업을 돌아보면, 이번 작업을 돌아보면, generator는 spec에 있는 정보를 코드로 변환할 뿐이다. 에러 코드를 examples에 싣기로 한 것은 백엔드와의 협의였고, entity 모델링을 자동화하지 않기로 한 것은 프로젝트 구조와 팀 흐름을 고려한 판단이었다. 어떤 라이브러리를 쓸지보다 이 결정들이 먼저였다. 그런 의미에서 codegen 도입은 코드 생성 문제라기보다 어디까지 자동화하고 어디부터 판단할 것인가의 문제에 가까웠다.
