샤딩이란 ?
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미한다.
application level에서도 가능하지만database level에서도 가능하다.Horizontal Partitioning이라고 볼 수 있다.
샤딩을 적용한다는 것은 ?
- 프로그래밍, 운영적인
복잡도는 더 높아지는 단점이 있다.
가능하면 Sharding을 피하거나 지연시킬 수 있는 방법을 찾는 것이 우선되어야 한다.
- Scale-in
Hardware Spec이 더 좋은 컴퓨터를 사용한다.
- Read 부하가 크면?
Cache나 Database의 Replication을 적용하는 것도 하나의 방법입니다.
- Table의 일부 컬럼만 자주 사용한다면 ?
Vertically Partition도 하나의 방법입니다.
Data를 Hot, Warm, Cold Data로 분리하는 것입니다.
샤딩에 필요한 원리
1. 분산된 Database에서 Data를 어떻게 Read할 것인가?
2. 분산된 Database에 Data를 어떻게 잘 분산시켜서 저장할 것인가?
- 분산이 잘 되지 않고, 한 쪽으로 Data가 몰리게 되면 자연스럽게 Hotspot이 되어 성능이 느려지게 됩니다.
- 그렇기 때문에
균일하게 분산하는 것이 중요한 목표입니다.
샤딩(Sharding)방법에 대해
Shard Key를 어떻게 정의하느냐에 따라 데이터를 효율적으로 분산시키는 것이 결정됩니다.
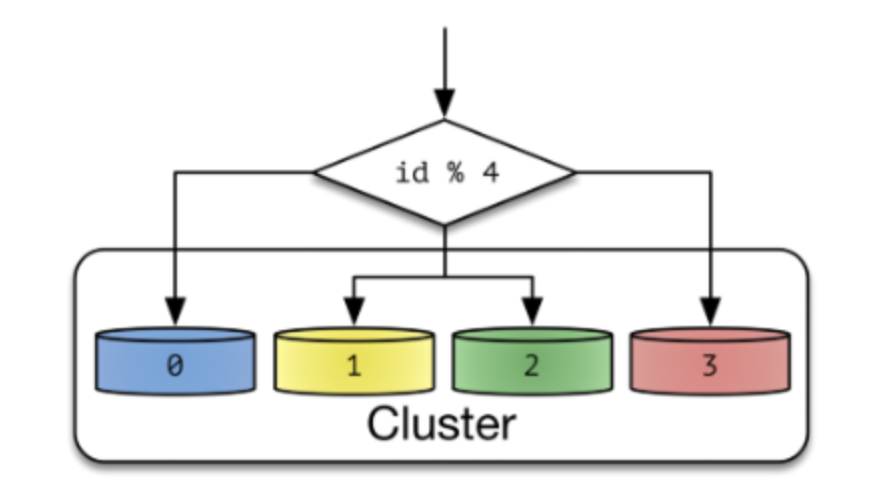
Hash Sharding
- Shard Key: Database id를 Hashing 하여 결정한다.
Hash 크기는 Cluster안에 있는 Node 개수로 정하게 된다.- 아주 간단한 Sharding 기법이다.
단점은 없을까요 ?
- Cluster가 포함하는 Node 개수를 늘려보거나 줄여보면 어떨까요 ?
- Hash 크기가 변하게 되고 Hash Key 또한 변하게 된다.
- 그러면 기존에 있던 Hash Key에 따라 분배된 Data 분산 Rule이 다 어긋나게 되고, 결국엔 ReSharding이 필요하게 된다.
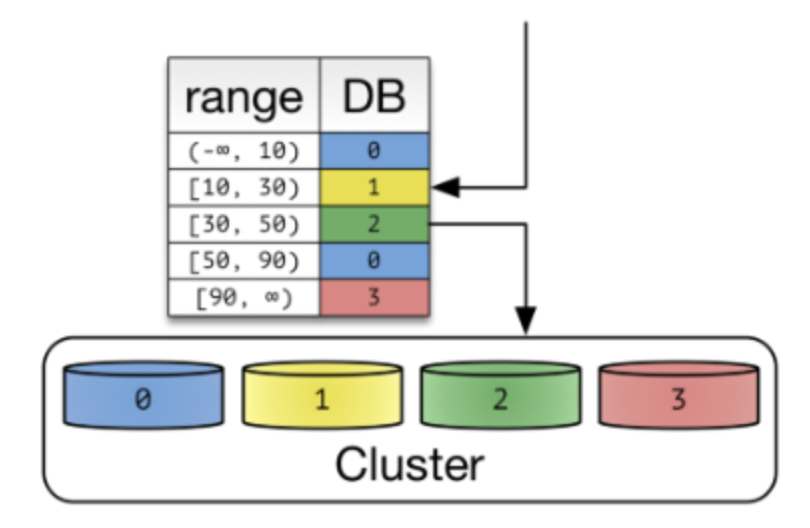
Dynamic Sharding
- Naming 그대로 Dynamic으로 바꿀 수 있다.
- Locator Service를 통해 Shard Key를 얻습니다.
Cluster가 포함하는 Node 개수를 늘려본다면 ?
- Locator Service에 Shard Key를 추가만 하면 됩니다.
- 기존의 Data의 Shard Key는 변경이 없습니다.
- 확장에 유연한 구조입니다.
단점은 없을까요 ?
Data Relocation을 하게 된다면 ?
Locator Service의 Shard Key Table도 일치시켜줘야 합니다.
Locator가 성능을 위해 Cache하거나 Replication을 하면 어떨까요 ?
- 잘못된 Routing을 통해 Data를 찾지 못하고 Error가 발생합니다.
- Locator에 의존할 수 밖에 없는 단점이 있습니다.
