
모든 프로그램은 작업 집합을 특정한 순서로 데이터에 적용하는 것으로 볼 수 있고, 이것은 프로그램이 데이터를 처리하는 방식을 나타낸다. 언어간의 기본 차이점으로 허용되는 데이터 유형, 가능한 연산 유형, 작업 순서를 제어하는 메커니즘이 있다.
데이터 객체 (数据对象)
데이터는 컴퓨터에 비트 문자열로 구성된 바이트로 저장된다. 언어의 가상 머신에서는 더 복잡하게, 배열, 스택, 숫자, 문자열 등 형태가 있다. 가상 머신에서는 다양한 조작 방식들을 통해 서로 다른 데이터 객체가 형성된다.
프로그램 실행 중엔 여러 유형의 객체가 존재하고, 일부는 프로그래머들에 의해 정의되고 생성, 조작 가능하며 일부는 시스템에 의해 정의되고, 런타임 저장 스택, 서브루틴 활성화 레코드, 파일 버퍼, 자유 공간 목록 등이 있고, 필요할때 자동 생성 및 삭제된다.
객체의 종류
표준 데이터 객체는 단일 값을 나타내고, 정수, 실수, bool값, 열거 형이 포함된다.
복합 객체는 여러 값을 하나로 묶고, 문자열과 포인터가 여기 속한다.
구조화된 객체는 배열, 레코드, 리스트, 집합과 같이 더 복잡한 구조다.
추상 데이터 객체는 클래스와 같이 추상화 수준이 더 높은 유형이고, 활동 개체는 작업과 프로세스같은 병행성을 가진 객체다.

객체는 데이터 값을 저장하고 검색하는 컨테이너로, 메모리 상의 특정 비트 패턴으로 데이터 값을 나타낸다. 대부분의 언어에서 객체와 값은 명확히 구분된다.
각 객체들은 생명주기를 가지고, 이 기간동안 데이터 값을 저장하기 위해 사용된다. 단순 데이터 객체와 데이터 구조로 분류되고, 데이터 구조는 다른 데이터 객체들의 집합이다. 객체는 생명주기 동안 여러가지 바인딩을 포함할 수 있고, 속성은 일정히 유지되지만 바인딩은 동적으로 변경될 수 있다.
객체의 속성과 바인딩
속성
- 유형 (类型): 프로그램 번역 시, 데이터 객체와 가능한 값의 집합을 연결한다.
- 위치 (位置): 대부분 프로그래머의 지정 없이 시스템이 담당한다.
- 값: 할당 연산을 통해 바인딩이 완료된다.
- 이름: 선언 시 바인딩이 완료되지만, 서브루틴 호출과 반환에 의해 수정 가능하다.
- 부품 (部件): 포인터 값으로 연결되며, 포인터 수정을 통해 변경 가능하다.
변수
컴파일러는 저장 위치 (데이터 객체)와 값, 두가지의 객체를 생성한다. 우리는 변수를 통해 이 객체를 명시적으로 정의하고, 이름을 지정한다. 변수는 이름이 있는 데이터 객체로, 내용 변경이 가능하며, 이름과 저장 위치 사이의 바인딩이다.
L-값과 R-값
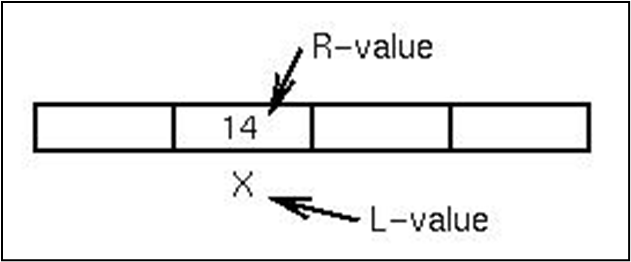
L값은 대에터 객체의 저장 위치, R값은 해당 저장 위치의 내용을 의미한다.
A=B+C의 실행을 예시로 보자. 우선 저장 위치 B의 내용을 가져오고, 저장위치 C의 내용을 더하고 결과를 주소 A에 저장한다. 각각 이름이 있는 객체에 대해, 할당 문장의 오른쪽에 있다면 그 값이 사용되고, 왼쪽에 있으면 주소가 사용된다. 주소를 가져오면 L-값, 값을 가져오면 R-값이 되는 것이다.
데이터 타입
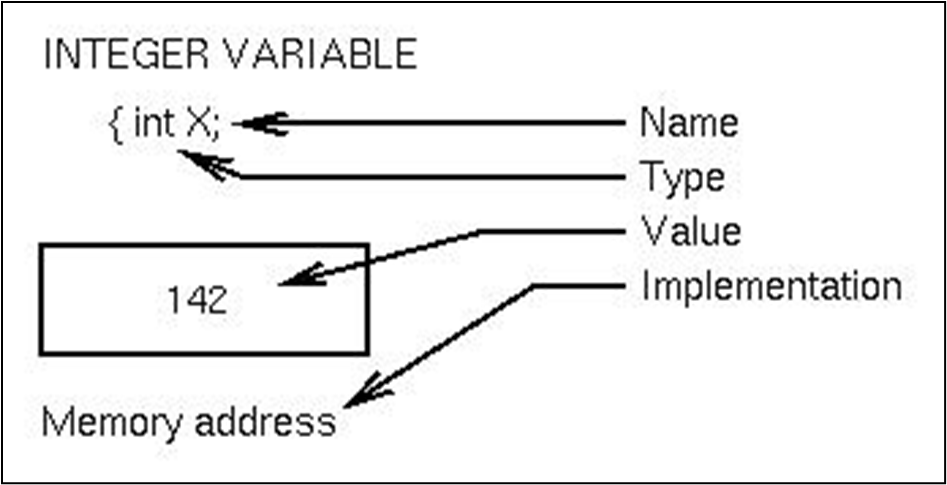
각 객체는 특정 타입을 가진다. 타입은 객체의 분류와, 그들을 생성하고 조작하는 연산의 집합을 포함한다.
데이터 타입은 성질들을 포함하는 규약과, 컴퓨터 내부의 구현을 포함한다. 해당 타입의 데이터 객체를 구분후나는 속성, 가질 수 있는 값, 처리 가능한 연산의 정의들이 규약에 포함된다.
예를 들어 배열 데이터 타입의 규약은 아래와 같다:
- 속성: 차원, 차원의 인덱스 범위, 원소의 데이터 타입 등
- 값: 원소의 유효한 값의 집합을 형성하는 수의 집합
- 연산: 개별 원소 선택, 배열 생성, 형태 변경, 상하한 접근, 배열간 수학적 연산 수행 등
기본 (간단) 데이터 타입
단일 데이터 값을 포함하는 객체를 기본/간단 데이터 타입이라고 한다. 정수, 실수, 불리안, Enum, 포인터 등 기본 타입이 있고, 언어마다 규약의 차이가 있다.
속성
객체의 기본 속성 (타입, 이름 등)은 대개 생명주기동안 변하지 않는다. 일부 속성은 런타입때 描述子에 저장되고, 객체의 일부로 나타나진다. 다른 속성들은 저장 표현을 결정하는데만 사용되며, 실행 중에는 명시적으로 나타나지 않는다. 속성 값과 객체의 값은 서로 다르다.
값
객체의 타입은 가능한 값 집합을 결정하고, 객체는 실행 중 어느 시점에든 그 집합내의 한개의 값만을 포함한다. 값 집합은 보통 순서가 있고, 최소와 최댓값이 있다.
연산
대이터 객체가 처리되는 방식을 제공한다. 내장된 원시 연산일 수도 있고, 사용자가 정의한 연산일 수도 있다.
주어진 입력에 대해 정의된, 유일한 결과를 가지는 수학적 함수가 연산이다. 연산의 基调 (signature)는 연산 도메인 내의 매개변수의 수량, 순서, 타입과 결과 값 도메인의 순서와 타입을 정의한다. 단항, 이항, 다항일 수 있다.
데이터 타입의 실현
구현/실현은 저장 표현과 데이터 타입의 연산을 포함한다.
存储表示는 컴퓨터 메모리 내에서 데이터 객체를 표현하는데 사용된다. 데이터 타입의 연산은 특수한 알고리즘 혹은 절차로 표현되며, 이들은 데이터 객체의 저장 표현을 조작한다.
기본 데이터 타입의 실현
저장 표현
우선 저장 표현은 하드웨어의 영향을 받는다. 정수와 실수는 하드웨어에서 사용되는 표현을 직접 사용하고, 문자 값도 하드웨어나 os의 문자 코드를 사용한다. 하드웨어의 저장 표현을 사용하면 해당 타입의 기본 연산을 하드웨어가 제공하는 연산으로 할 수 있어 효율적이다. 그렇지 않다면 소프트웨어 에뮬레이션으로 해야 해서 효율성이 떨어질 수도 있다. 객체 자체의 표현은 일반적으로 저장 위치와 독립적이며, 메모리 블록의 크기와 블록 내의 속성 및 값의 레이아웃을 통해 설명된다.
연산
하드웨어 연산으로 직접 가능하다. 혹은 프로시져, 함수 서브루틴 (函数子程序)로도 가능하다. 제곱근같이 객체가 하드웨어 표현을 사용하지 않을 경우 에뮬레이션으로 해야 하고, 이는 서브루틴 형태로 구현된다. 인라인 코드 시퀀스로도 가능하고, 이는 서브루틴 대신 필요한 연산 코드를 직접 호출 지점에 복사하여 사용하는 방식이다.
객체의 선언
선언은 언어 번역기에게 데이터 객체에 대한 정보를 알리는 프로그램 문장이다. 선언문이 특정 프로그램이나 클래스 정의 내에 위치하면 객체의 원하는 생명주기를 나타낸다. 선언은 명시적일 수도 있고, 암시적이거나 기본값을 가질 수도 있다.
연산의 선언
연산에 대한 정보는 번역 시 필요하며, 주로 연산의 基调에 관한 것이다. 언어에 내장되어 있기에, 기본 연산은 명시적인 매개변수 타입이나 결과 타입의 선언이 필요하지 않다. 하지만 프로그래머가 위처럼 정의한 연산은 매개변수 타임과 결과 타입을 확실히 명시해야 한다.
선언의 목적
- 저장 표현 선택: 데이터 타입과 객체의 속성 정보를 컴파일러에 제공해 최적의 저장 표현을 결정하게 하고, 공간 효율과 실행 시간 효율도가 늘어난다.
- 저장 관리: 객체의 수명에 관한 정보를 제공해 더 효율적으로 실행 중 저장 관리를 가능케 한다. 예를 들어, C언어에서는 서브루틴의 시작 부분에서 선언된 데이터 객체가 서브루틴의 수명을 공유하기 때문에, 서브루틴 진입 시 모든 데이터 객체를 위한 하나의 메모리 블록을 할당하고 서브루틴 종료 시 해제할 수 있다.
- 다형성 연산 (多态操作): 언어에서는 操作들을 나타내기 위한 특별한 심볼을 사용하고, 구체적인 操作의 디테일은 매개변수의 데이터 타입에 의존한다. 이를 오버로딩 (重载)라고 하고, 객체지향 언어의 상속 메커니즘은 포함 다형성 (包含多态性)을 제공한다.
- 타입 체크 (类型检查): 정적, 동적 체크로 나뉜다. 오류를 방지하기 위한 중요한 과정이다.
타입
타입 체크
하드웨어 고유의 저장 표현은 유형 표현을 포함하지 않고, 데이터의 기본 操作들도 보통 타입 체크가 필요 없다. 어셈블리 언어나 기계 언어 프로그래밍에서 흔히 볼 수 있는 오류는 조작 유형에서 비롯되는데 이는 발견도 어렵고, 조작 자체는 성공하지만 결과가 의미 없는 경우도 있다.
타입 체크는 프로그램에서 각 연산이 올바른 타입의, 올바른 수의 매개변수를 받는지 검사하는 과정이다. 이는 컴파일 시 (정적) 혹은 실행 시 (동적)으로 수행 될 수 있다. 고급언어의 좋은 점은 모든 연산에 대한 타입 체크를 제공하는 것이다.
동적 타입 체크
타입 플래그가 필요하지만, 변수에 대한 선언이 필요 없다, 즉 변수가 타입을 가지지 않는다.
동적 타입 검사는 타입 정보를 프로그램 실행 시점에 검사한다. 장점으로 프로그래밍의 유연성이 증가된다. 다만 디버깅이 어려울 수 있고, 모든 타입오류들이 미리 제거되지 않을 수도 있다. 모든 실행 결로를 테스트하는것도 불가능하기에 일부 오류를 놓칠 수도 있고, 실행중에 타입 정보를 유지해야 해 추가적인 저장 공간이 필요하며, 소프트웨어로 구현되기에 실행 시간에도 부담이 간다.
정적 타입 체크
정적 타입 검사는 컴파일 시점에 수행되어, 프로그래머가 변수 선언시 혹은 다른 언어 구조를 통해 타입 정보를 제공해야 한다. 컴파일러는 이 타입 정보를 수집, 모든 연산의 타입을 검사한다.
정적 타입 검사의 범위는 아래와 같다.
- 각 연산에 대해 필요한 매개변수의 수, 순서, 타입과 결과 타입.
- 모든 변수에 대해 연관된 명명된 데이터 객체의 타입.
- 모든 상수 데이터 객체의 타입.
비교
정적 검사는 프로그램 내 모든 연산에 대해 수행되며, 가능한 모든 실행 경로가 검사된다. 따라서 타입 오류에 대한 추가 테스트는 필요하지 않으며, 런타임 타입 검사나 타입 플래그가 필요 없다.
대부분의 언어에서는 일부 언어 구조에 대한 정적 검사가 불가능한 경우가 있다. 해결책으로 동적 타입 검사나 무검사(no checking)를 사용할 수 있다.
프로그램 내 모든 타입 오류를 정적으로 탐지할 수 있다면, 해당 언어는 강한 타입 (强类型) 을 가진다고 한다. 타입 안전한 (类型安全) 함수는 실행 중에 결과 타입 이외의 값이 생성되지 않아, 동적 검사가 필요하지 않다.
타입 선언이 생략될 수 있는 경우, 두 가지 의미의 가능성이 없다면, 언어 구현이 누락된 타입 정보를 추론해 낼 수 있다.
서브타입과 타입 변환
어떤 타입 A가 타입 B의 서브타입 (子类型) 이라 함은, A의 모든 값이 B의 값의 집합에도 속한다는 의미다. C언어에서는 대부분의 타입이 정수 타입의 서브타입으로 간주될 수 있다. 변수 A와 B가 주어졌을 때 A := B가 합법적인 상황은 타입 변환의 규칙에 따라 달라진다.
- 显示的, 명시적 타입 변환: 서로 다른 타입간 변환은 반드시 명시적으로 지정해야 한다.
- 隐式的, 암시적 타입 변환: 언어 정의에 의해 암묵적으로 허용되는 타입 변환이다.
Pascal 언어를 예로 들면, A: real과 B: integer가 있을 때 A := B는 암시적 타입 변환(코어션)이 발생하여 자동으로 B의 타입이 A의 타입으로 변환된다.
A := B는 이경우에 放款的, 확장된 타입 변환으로, A가 B보다 표현할 수 있는 값이 넓기 때문이다.
B := A는 반대로 变窄的, 축소된 타입 변환으로, 정보 손실이 발생 할 수 있으며 허용되는 경우에만 할당이 이루어진다.
기본 데이터 타입
정수
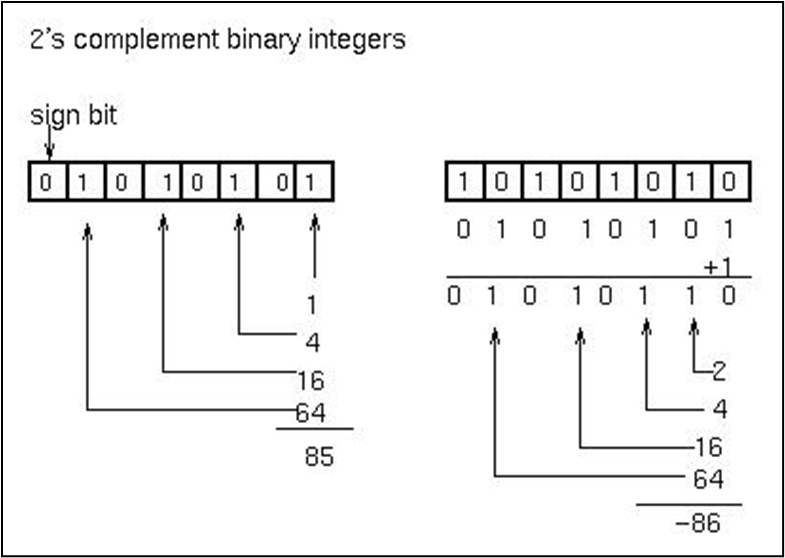
이진수의 보수 표현 (补码表示)으로 나타낸다. 32비트 정수의 경우 최대값은 이고, 최소값은 이다.
실수
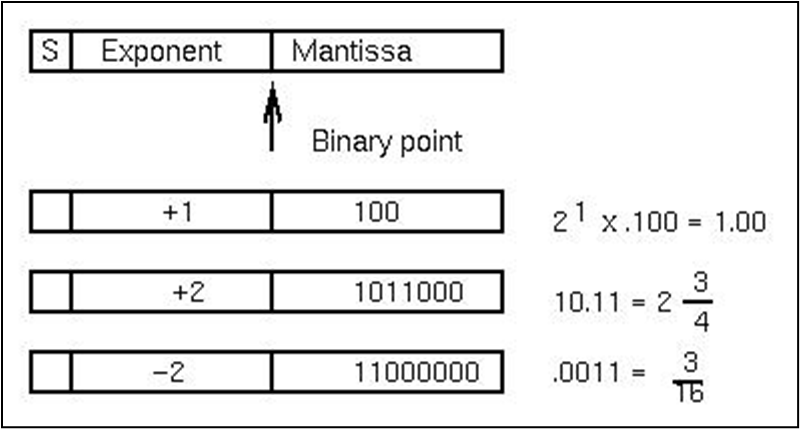
부동소수점 표현이고, 하드웨어 표현을 사용한다. 偏置 (편향)을 사용해서 표현되는데, 예를 들어 8비트 지수해서는 128을 더하는 형태로 편향된다. ICS때 배웠던 IEEE 754 규격을 많이 사용한다.
enum
열거형이라 한다.
typedef enum thing {A, B, C, D} NewType;는 새로운 타입 NewType을 정의하고 있으며, 이 타입의 가능한 값은 A, B, C, D이다.
십진 소수
DECLARE X FIXED DECIMAL(p, q);에서 p는 소수의 전체 자릿수, q는 소수점 이하 자릿수를 나타낸다.
정수 자릿수와 소수 자릿수를 지정하고 더할 수 있다. p=8은 두 4자리 수를 더했을 때 5자리 수가 될 수 있기 때문이고, q=3은 소수 부분을 저장하기 위해 필요하다. 이 값은 컴파일 시점에서 알 수 있다.

구현 과정이다.
복합 데이터
문자열
기본적인 문자 데이터로 구성된 데이터 객체다.
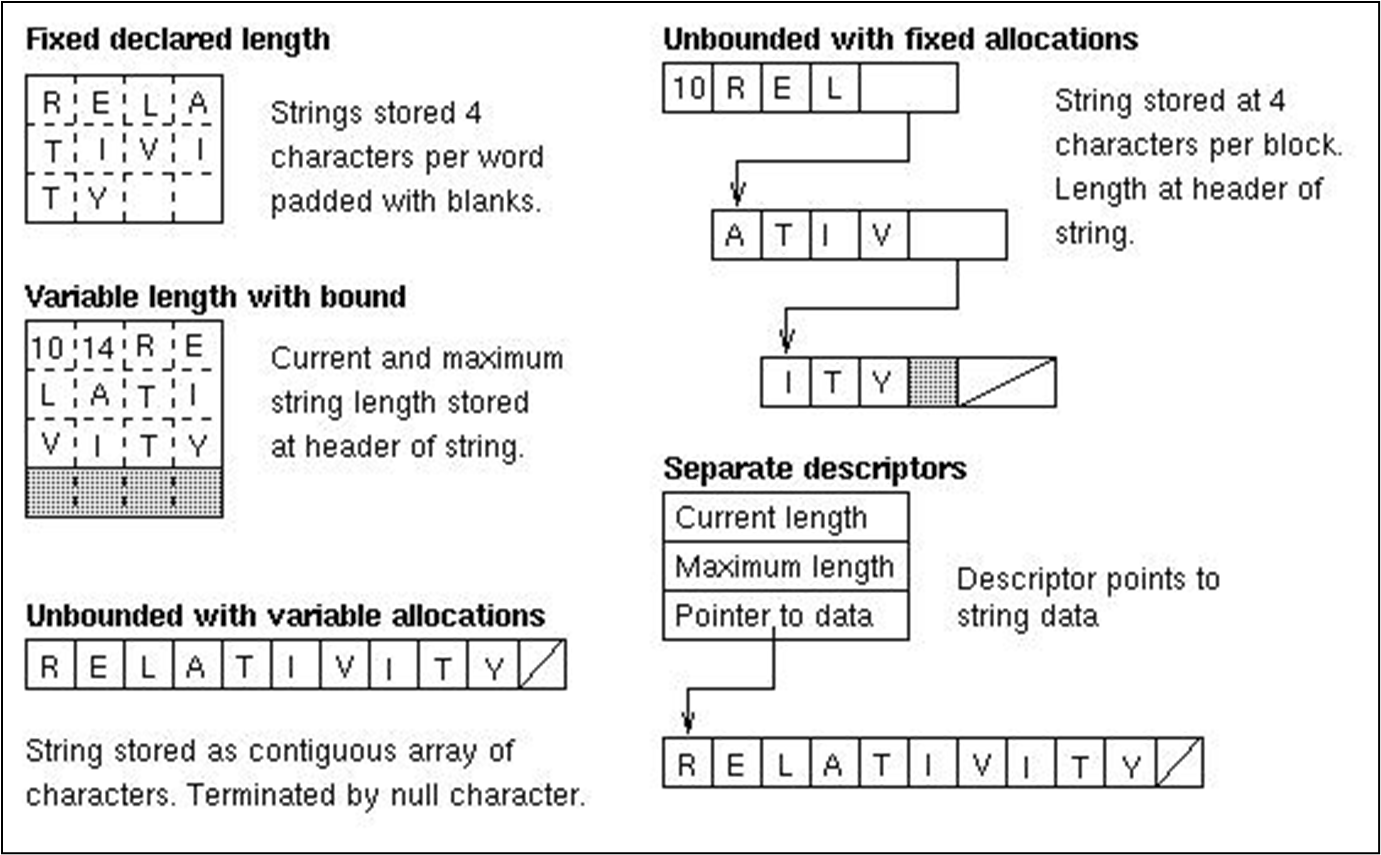
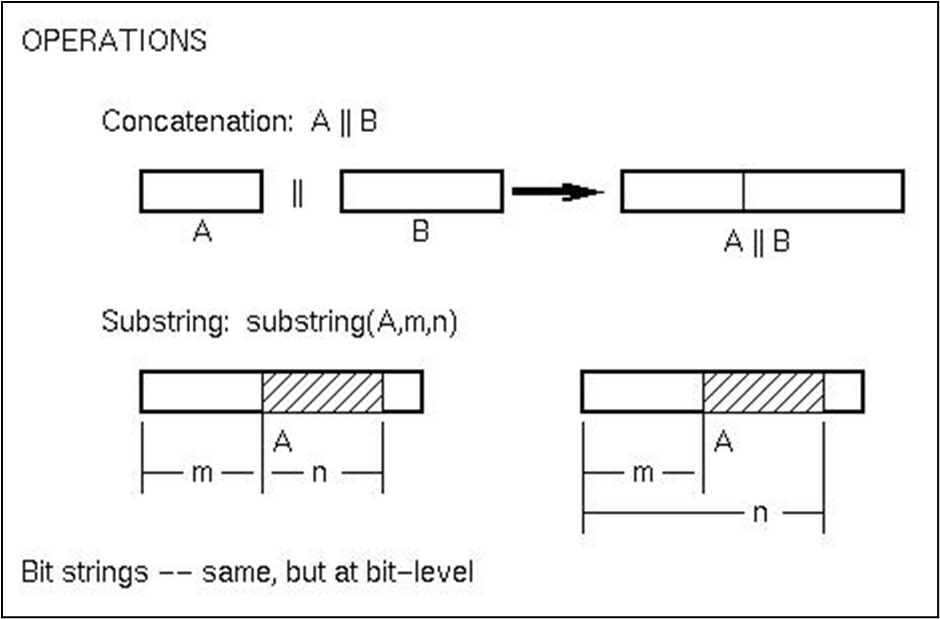
C 언어에서는 배열과 문자열이 거의 동일하게 취급된다. 문자열의 구현에서, 특정 인덱스 I에 있는 문자에 대한 L-value(저장 위치)는 첫 번째 문자의 L-value에 I를 더한 값과 같다. (L-value(A[I]) = L-value(A[0]) + I)
포인터
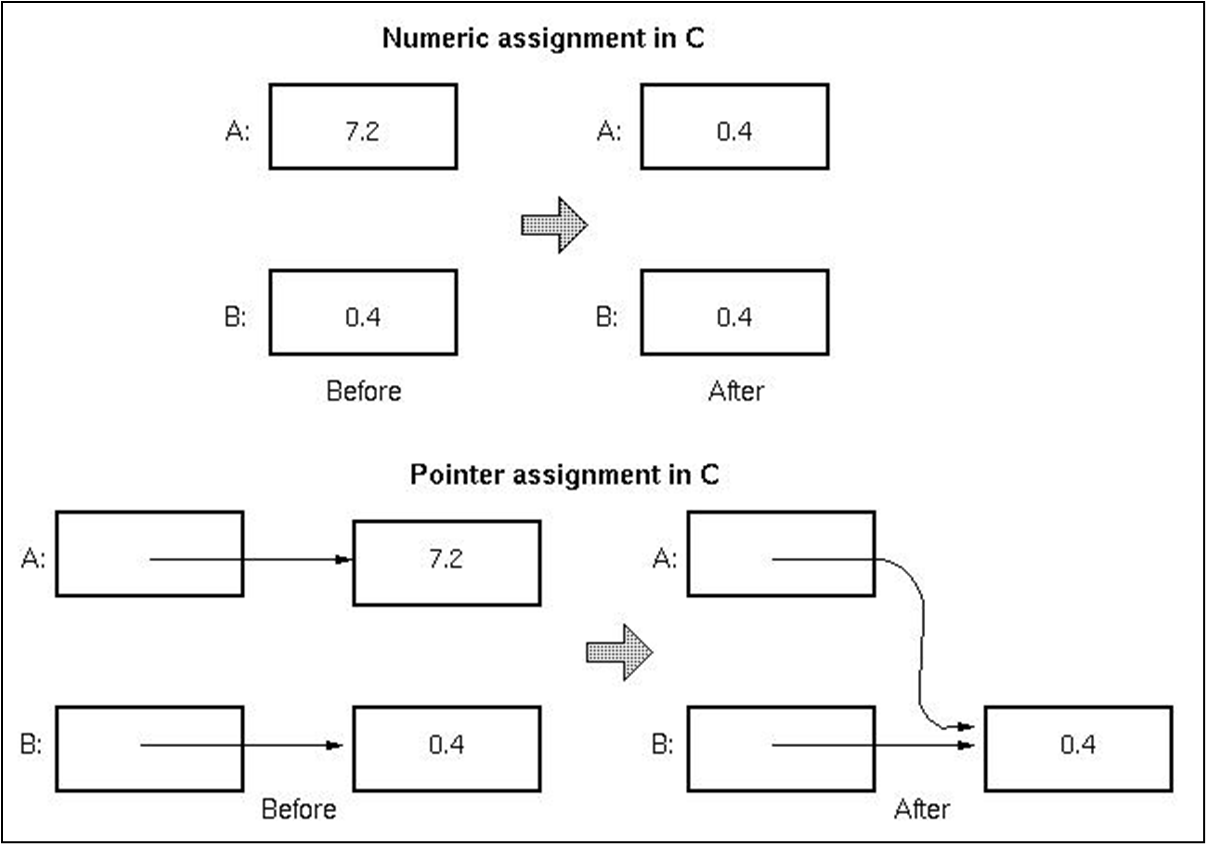
포인터를 사용하여 다른 데이터 객체를 가리키고, 다양한 데이터 구조를 생성할 수 있다.
