
대규모 프로그램을 구축할 때, 프로그래머는 새로운 데이터 타입의 설계와 구현에 관여하게 된다. 예를 들어, 대학의 강의를 나타내는 section이라는 데이터 객체를 생각해보면, 이 객체에는 교수의 이름, 강의실, 최대 등록 가능한 학생 수 등의 정보가 포함될 수 있다.
프로그래밍 언어 구현의 주요 목표 중 하나는 데이터의 다양한 형태를 프로그래머에게 투명하게 만드는 것이다. 이것은 기본 타입과 사용자 정의 타입이 프로그래머에게 사용상의 차이가 없어야 함을 의미한다. 즉, 사용자 정의 타입도 마치 언어에서 기본으로 제공하는 타입처럼 쉽고 자연스럽게 사용할 수 있어야 한다.
구조화 데이터
기본 개념
구조화된 데이터 객체는 다른 데이터 객체들의 집합으로, 이들 개별 객체를 원소 또는 부품이라고 한다. 구조화된 데이터는 기본 타입 데이터와 많은 공통점을 가지지만, 보다 복잡한 구조를 가지고 있다.
구조 정보의 명세와 구현, 그리고 구조화된 데이터의 다양한 연산에 따른 저장 관리 문제는 고려해야할 중요한 문제들이다.
데이터 구조 타입의 규약
속성
- 부품의 수(部件数量): 부품 수는 고정될 수도 있고(예: 배열, 레코드), 가변적일 수도 있다(예: 스택, 리스트, 집합, 파일).
- 각 부품의 타입(部件类型): 동일한 타입의 부품을 가질 수도 있고(예: 배열, 문자열), 다양한 타입의 부품을 가질 수도 있다(예: 레코드, 리스트).
- 부품 선택 메커니즘/이름: 부품을 선택하기 위한 메커니즘이 필요하다. 예를 들어 배열에서는 인덱스를 사용하여 개별 부품을 선택한다
- 부품의 최대 수량: 가변 길이 구조의 경우 최대 크기를 명시할 수 있다.
- 부품의 조직(组织): 가장 일반적인 조직은 선형 시퀀스다 (예: 벡터, 레코드, 문자열, 스택, 리스트). 배열등은 다차원으로 전개도 가능하다.
연산
- 부품 선택 연산: 무작위 선택 (임의 부품 선택)과 순차적 선택이 있다. v[4]로 선택 할 시, 우선 引用하여 v의 위치, l값을 확정하고 포인터를 반환, 그 후 선택하여 그 위치의 값을 가져온다.
- 전체 데이터 구조 연산: 전체 데이터 구조를 매개변수로 하여 새로운 데이터 구조를 결과로 생성한다. 배열의 덧셈, 집합 연산 등이 있다.
- 부품 삽입/삭제: 이는 부품 수를 변경하고 저장 표현과 관리에 영향을 미친다.
- 데이터 구조 생성/소멸: 이러한 연산은 저장 관리에 큰 영향을 미친다.
구조화 데이터 타입의 실현
구현 시 고려해야 할 주요 문제는 구성 요소의 효율적인 선택과 효율적인 저장 관리다.
저장 표현
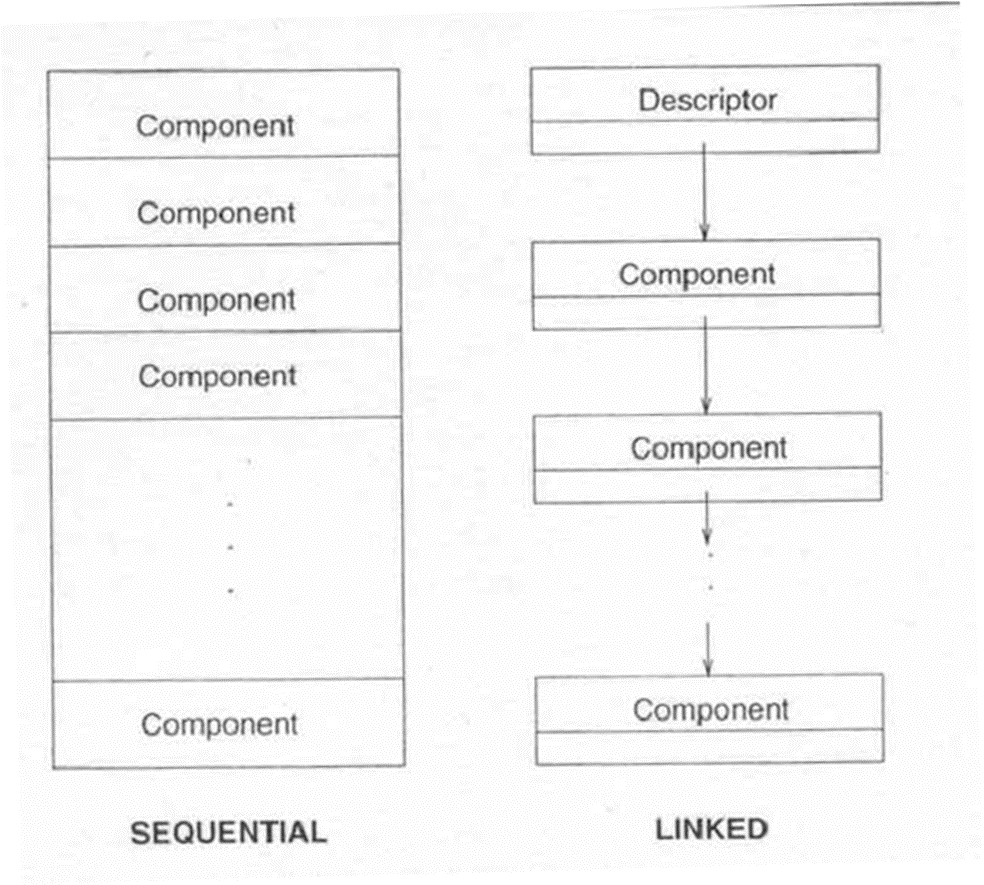
구조의 저장 관리는 구성 요소의 저장과 선택적인 설명자(구조의 속성을 저장하는데 사용됨)를 포함한다.
두가지 기본적인 저장 방식이 사용된다.
- 순차적 표현: 구조가 단일 연속적인 메모리 블록에 저장된다. 고정 길이 구조에 주로 사용되고, 때로는 일한 길이의 가변 길이 구조에도 사용된다.
- 연결 표현: 조가 여러 개의 비연속적인 메모리 블록에 저장되고, 이들 블록이 포인터로 연결된다. 가변 길이 구조에 주로 사용된다.
연산
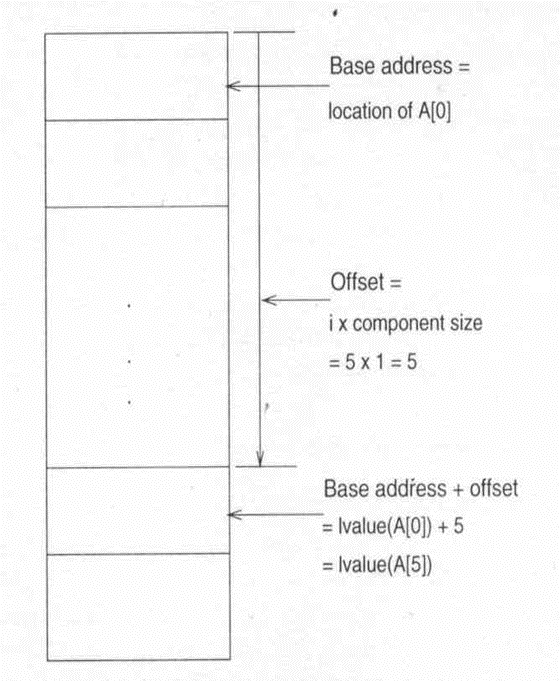
선택 연산이 보통 제일 중요하다. 순차적 표현에서는 구성 요소의 임의적 접근이 "기본 주소 + 오프셋" 계산을 통해 수행된다. 연결 표현에서는 임의적 선택이 포인터 체인을 따라 탐색을 필요로 하며, 순차적 선택은 보다 간단하게 포인터를 따라 진행된다.
접근
데이터 객체가 생성되면, 해당 객체에 접근할 수 있는 경로도 함께 생성되어야 한다. 접근 경로는 식별자(이름)를 객체에 연결하거나, 다른 접근 가능한 구조 내에 객체를 가리키는 포인터를 저장하여 생성된다.
객체의 수명 동안 추가적인 접근 경로가 생성될 수 있으며, 이는 서브루틴에 매개변수로 전달하거나 새로운 포인터를 생성함으로써 이루어질 수 있고, 접근 경로는 삭제될 수도 있다.
접근 관련해서 문제들이 발생할 수 있다.
- 쓰레기: 모든 접근 경로가 제거되었지만 데이터 객체가 여전히 존재하는 경우, 객체는 더 이상 접근할 수 없게 되며, 이와 연관된 저장 공간은 해제되어야 한다.
- Dangling Reference, 悬空引用: 관련 데이터 객체가 제거된 후에도 접근 경로가 여전히 존재하는 경우다. 이는 저장 관리에 심각한 문제를 일으킬 수 있으며, 런타임 구조의 무결성을 손상시킬 수 있다.
배열

배열은 동일한 데이터 타입의 일련의 정렬된 데이터 객체들로 구성된다. 배열의 각 요소는 스칼라 데이터 객체(대개 정수 또는 열거형)로 결정되는 인덱스나 하위(subscript)에 의해 접근된다. 예를 들어, 우리가 잘 알듯 배열 A에서 인덱스 I에 해당하는 요소는 A[I]로 표현된다. 다차원 배열은 여러 개의 인덱스를 가질 수 있으며, 이중 배열(two-dimensional array)은 행렬(matrix)로 볼 수 있다.
접근
배열의 특정 원소를 방문하려면, Dope Vector (信息向量)을 사용한다.
생성
배열 생성 과정이다.
- 주소 α에서 시작하여 배열에 필요한 전체 저장 공간을 할당한다:
(U2-L2+1)*(U1-L1+1)*eltsize. d2 = eltsize(요소의 크기)d1 = (U2-L2+1)*d2VO = α - L1*d1 - L2*d2- 배열 A[I,J]에 접근하기 위해서는
Lvalue(A[I,J]) = VO + I*d1 + J*d2를 사용한다.
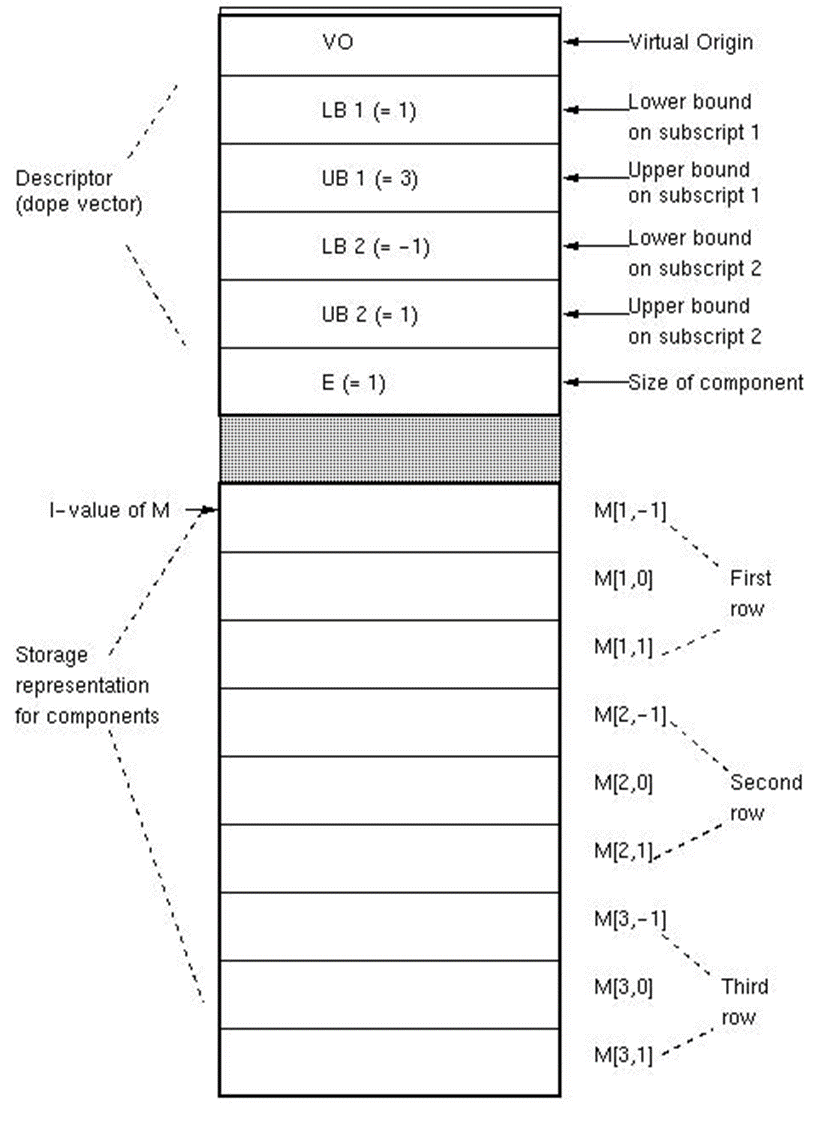
모든 값이 컴파일 시에 알려져 있으면 정보 벡터(dope vector)가 필요 없다. 예를 들어, Pascal에서는 d1, d2, VO가 컴파일 시 계산될 수 있다.
예시
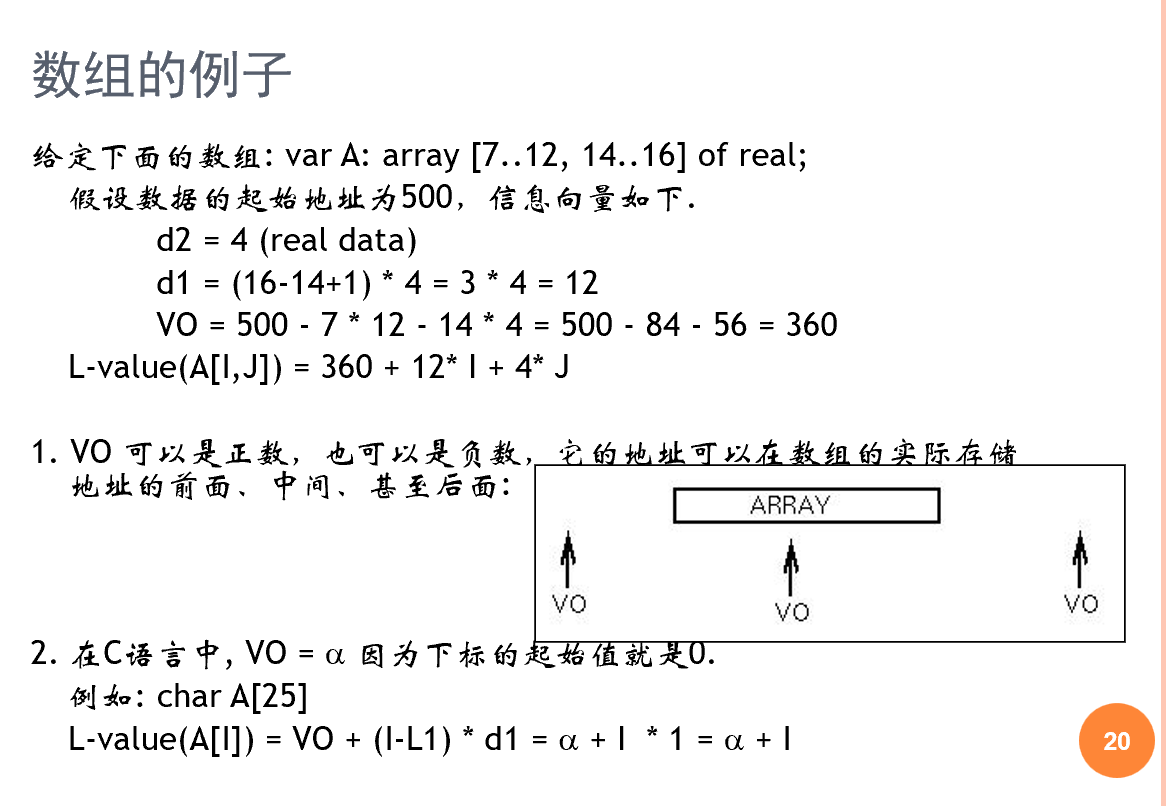
이 배열은 실수형(real) 두 차원 배열로, 첫 번째 차원의 범위는 7에서 12, 두 번째 차원의 범위는 14에서 16이다. 즉 12-7+1=6개의 행, 16-14+1=3개의 열이다.
배열의 시작 주소가 500이라고 가정할 때, 배열 요소에 접근하기 위한 정보 벡터는 다음과 같이 계산된다:
d2 = 4(실수 데이터의 크기)d1 = (16-14+1) * 4 = 3 * 4 = 12(첫 번째 차원의 크기)VO = 500 - 7 * 12 - 14 * 4 = 500 - 84 - 56 = 360(가상 원점)
배열 요소 A[I, J]의 L-value(저장 위치) 계산 공식은 L-value(A[I,J]) = 360 + 12 * I + 4 * J가 된다.
C에선 배열의 인덱스가 0부터 시작한다. 예를 들어, char A[25]라는 배열이 있다면:
- 배열 요소 A[I]의 L-value 계산 공식은
L-value(A[I]) = VO + (I - L1) * d1 = α + I * 1 = α + I가 된다.
여기서 VO는 배열의 시작 주소 α와 동일하다. C 언어에서는 인덱스가 0부터 시작하기 때문에, L1이 0이고, d1은 char 타입의 크기인 1이다.
数组切片 (배열 슬라이싱)
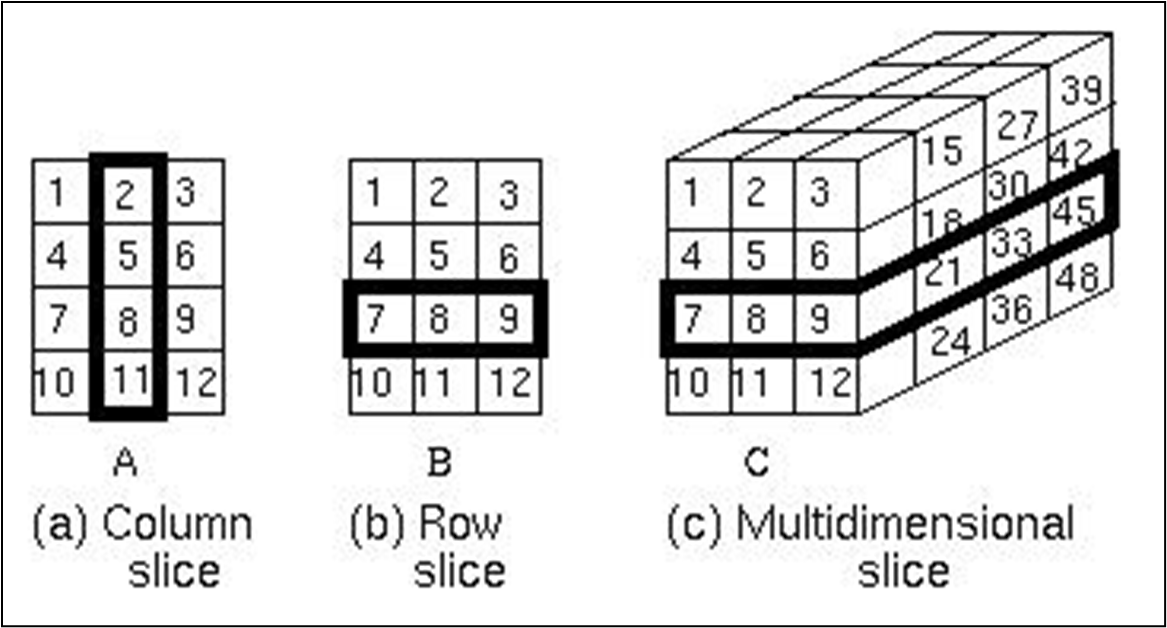
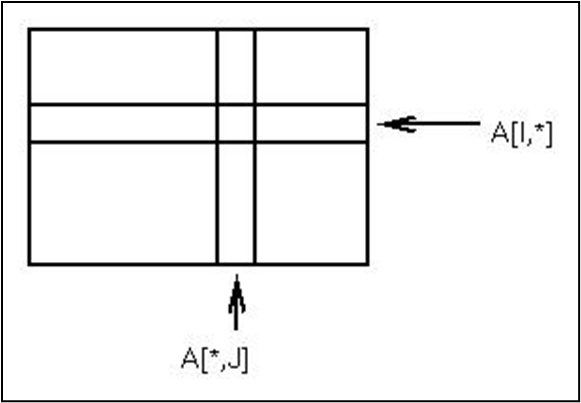
주어진 배열 A[L1:U1, L2:U2]에서 특정 행 또는 열을 슬라이스하는 경우, 새로운 정보 벡터를 다음과 같이 정의할 수 있다.

추상 데이터 타입
추상 메커니즘
- 데이터: 거의 모든 프로그래밍 언어는 기본 데이터 객체를 사용하여 더 복잡한 데이터 객체를 생성할 수 있는 기능을 제공한다.
- 연산 (서브루틴): 연산을 정의 가능하다.
- 타입 선언 (类型声明): 새로운 타입과 그 연산의 정의가 가능하다. 추상 데이터 타입(Abstract Data Type, ADT)은 이러한 메커니즘이다.
- 상속: 이미 존재하는 타입을 기반으로 새로운 타입을 생성하는 메커니즘이다.
정보 은닉 (信息隐蔽)
프로그램의 각 부분은 가능한 한 사용자에게 정보를 숨겨야 한다. 정보가 추상화 내에 캡슐화될 때, 추상화의 사용자는 해당 추상화를 사용하기 위해 숨겨진 정보를 알 필요가 없고, 숨겨진 정보를 직접 사용하거나 조작할 수 없다.

위처럼 C로 은닉을 구현할 수 있다. 하지만 은닉은 강제가 아니다. 위의 P2에서 V.i 식으로 접근이 가능하다. Smalltalk, C++, Java, Ada와 같은 언어에서는 정보 은닉을 강제하는 메커니즘이 있으며, 이를 캡슐화(Encapsulation)라고 한다.
캡슐화 (封装)
프로그램이 쉽게 수정될 수 있도록 만들어주며, 특히 서브루틴(함수)의 인터페이스를 유지하는 한 변경이 용이해진다.
서브루틴은 프로그래머가 정의한 추상적인 연산으로, 프로그램의 기본적인 구성 요소다. 서브루틴의 정의(명세)는 프로그래머가 제공하며, 이는 서브루틴의 이름, 기초(基调,함수의 매개변수와 반환 타입), 그리고 동작을 포함한다. 단일 결과 객체를 반환하는 함수류와, 여러 결과를 반환하거나 매개변수를 통해 결과를 반환하는 프로시저류가 있다.
캡슐화는 서브루틴의 로컬 데이터와 문장이 사용자에게 직접 접근되지 않도록 보장하고, 이들은 오직 서브루틴을 통해서만 접근될 수 있다. 숨겨진 매개변수(비지역 변수)와 숨겨진 결과(부작용)를 가질 수 있고, 매개변수의 특정 조합에 대해 정의되지 않을 수 있으며, 역사적 맥락에 민감할 수 있다.
실현
서브루틴은 프로그래밍 언어가 제공하는 데이터 구조와 연산을 사용하여 구현된다.지역 데이터 선언으로 지역 구조 또는 데이터를 정의하고, 문장으로 행동을 정의한다. 캡슐화는 사용자가 지역 데이터와 문장에 직접 접근하는 것을 방지하고, 매개변수를 통해서만 서브루틴을 호출할 수 있도록 보장한다.
정의와 호출
서브루틴이 호출될 때, 서브루틴을 위한 지역 데이터 공간이 생성된다. 이러한 정보는 활성화 레코드(激活记录) 에 저장된다. 서브루틴의 정의는 활성화 레코드를 생성하는 템플릿 역할을 한다.

위 예시에서 FN은 해당 서브루틴의 모든 정보를 활성화 레코드에 포함한다.
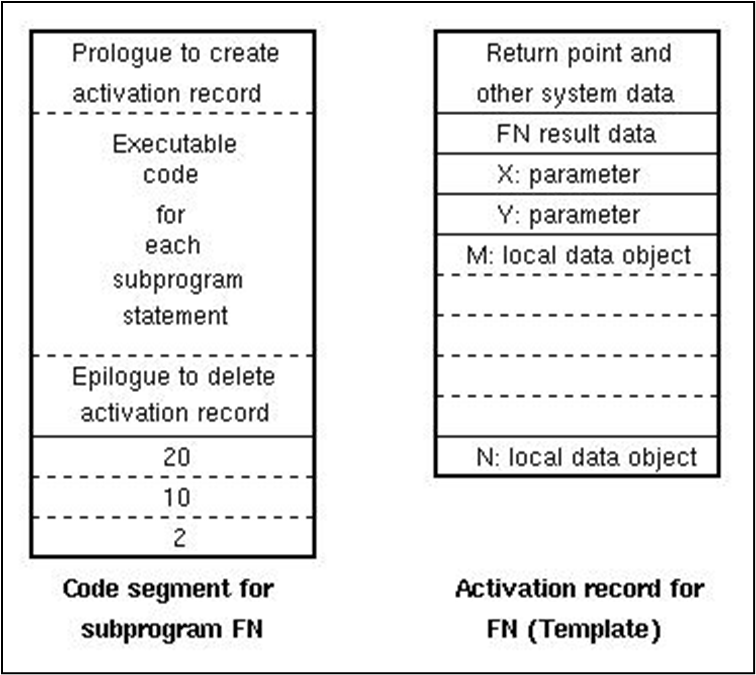
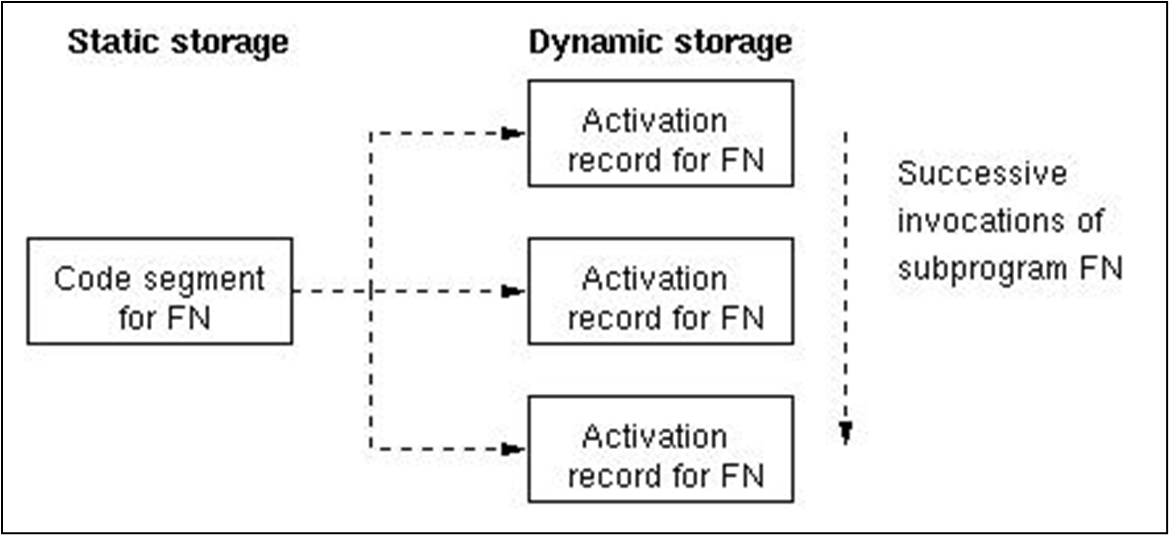
FN의 각 호출은 새로운 활성화 레코드를 생성하고, 컴파일러가 생성한 정적 코드는 새로운 활성화 레코드와 연결된다. 이러한 활성화 레코드들은 스택 구조로 저장된다.
지역 데이터는 활성화 레코드(또는 스택 프레임)에 저장될고, 우선 해당 선언이 포함된 활성화 레코드의 포인터 주소를 얻고 활성화 레코드 내에서 데이터 항목의 오프셋 주소를 찾는다.
데이터의 생명주기
활성화 레코드의 생명주기는 서브루틴(함수)이 호출되어 그 서브루틴의 로컬 변수가 생성될 때 시작하여, 서브루틴이 종료되고 로컬 변수가 소멸될 때 끝난다.
데이터의 생명주기는 크게 두가지로 분류된다:
- 정적: 프로그램의 정적 구조에 따라 결정된다. 예를 들어, 전역 변수나 정적 변수는 프로그램의 실행 기간 동안 생존한다.
- 동적: 프로그램의 실행에 따라 결정된다. 예를 들어, 로컬 변수는 해당 변수를 포함하는 함수가 활성화되어 있는 동안만 존재한다.
정적 생명주기는 보통 스택을 사용해 구현되고, 동적은 힙을 사용해 구현된다.
변수의 생명주기
변수의 생명주기는 해당 변수를 포함하는 서브루틴의 활성화 레코드가 존재하는 기간에 해당한다.
변수의 스코프 (作用域)는 소스 코드에서 해당 변수에 접근할 수 있는 코드 영역을 의미한다.
타입 정의와 등가
타입 정의
새로운 추상 데이터 타입을 정의하기 위해서는 데이터 객체 집합을 정의하는 메커니즘이 필요하다. 타입 정의는 타입 이름과 데이터 객체 구조에 대한 선언을 포함한다.
타입 정의를 사용하면 수정이 필요할 때 해당 타입만 수정하면 된다. 이 또한 캡슐화/정보 은닉의 일종으로, 내부 구조가 숨겨져 있다.
타입 체크
타입 체크의 목적은 언어에서 안전한 표현식만 허용하는 것이다. 안전한 표현식은 f(a) = b가 a가 x에 속함을 의미하며, 잘못된 함수 호출을 방지한다. 예를 들어, / 연산자는 float x float → float로 정의되지만, 3/0과 같은 경우는 안전하지 않다.
강타입/약타입
언어가 강타입이라 함은 모든 표현식이 안전하게 타입 체크를 거쳐야 함을 의미한다.

위의 경우, char에서 a+b가 255보다 클수 있으므로 안전하지 않다. long에서는 오버플로우가 프로그램을 종료시켜서 안전하고, A[I]는 체크를 해서 안전하다.

반면 약타입이면, 안전하지 않은 표현식이 허용된다.
타입 체크와 등가성
값의 동등성은 두 데이터 객체가 같은 값을 가지고 있는지를 판단하는 것이다. 기본 데이터 타입의 경우, 값의 동등성은 비트 단위의 동등성으로 판단됩니다. 예를 들어, 두 int 변수가 같은 이진 값을 가지면 동등한 것으로 간주된다.
타입의 동등성은 두 타입이 같은지를 판단하는 것으로, 주로 '이름에 의한 동등성'과 '구조에 의한 동등성'으로 구분된다. 전자는 두 타입이 같은 타입 이름을 가지고 있을 때 동등한 것으로 간주한다. 후자는 두 타입이 같은 구조(예: 필드의 수와 타입, 배열의 크기 등)를 가지고 있을 때 동등한것으로 간주한다.
