1. TD 방식
TD = MC+DP
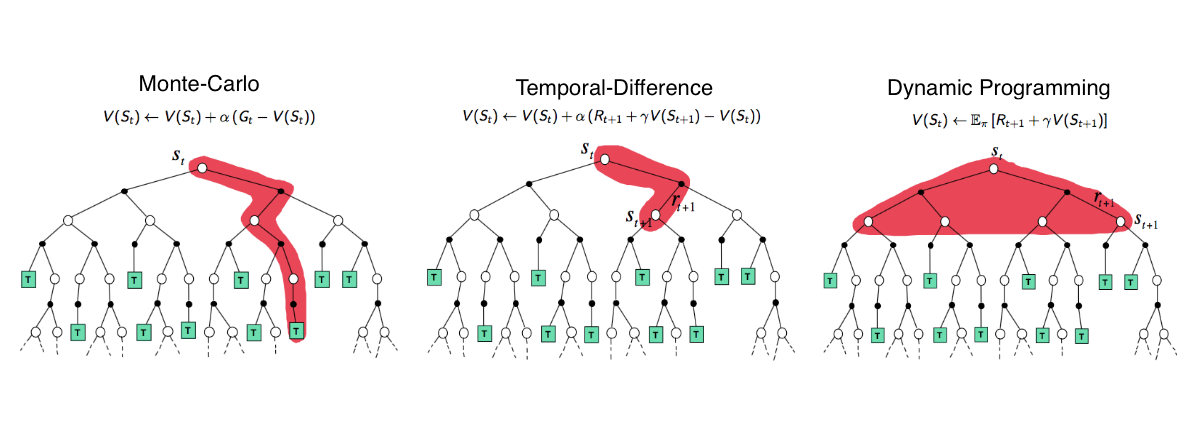
TD 학습은 몬테카를로 방법처럼 raw experience를 통해 학습할 수 있는 Model-Free 방식이며, DP처럼 Bootstrapping을 수행하여 최종 결과를 얻을 때까지 기다리지 않고 다른 학습된 추정값을 기반으로 추정값을 갱신한다.
몬테카를로 수식을 보면, Gt는 시각 t 이후의 실제 이득이며, V(St)의 증가량을 결정하기 위해서는 에피소드가 끝날 때까지 기다려야 한다. 갱신의 목표가 Gt가 된다.
하지만 TD 방법은 시각 t+1에서 관측된 보상 Rt+1과 추정값 V(St+1)을 이용하여 갱신하므로, 다음 시간 단계까지만 기다리면 된다. 갱신의 목표가 Rt+1 + γV(St+1)가 되고 이 값과 St의 추정값의 차이를 TD error라고 한다. 이러한 TD 방법을 TD(0), one-step TD라고 표현한다.

-
Every-vist MC에서는 실제 에피소드가 끝나고 받게 되는 보상을 사용해서 value function을 업데이트를 함 => MC의 갱신 목표 = Gt
-
TD에서는 실제보상과 다음 step에 대한 미래 추정 가치를 사용해서 학습을 함=> TD의 갱신 목표 TD target
TD target과 실제 V(St)와의 차이를 TD error(델타)라고 함
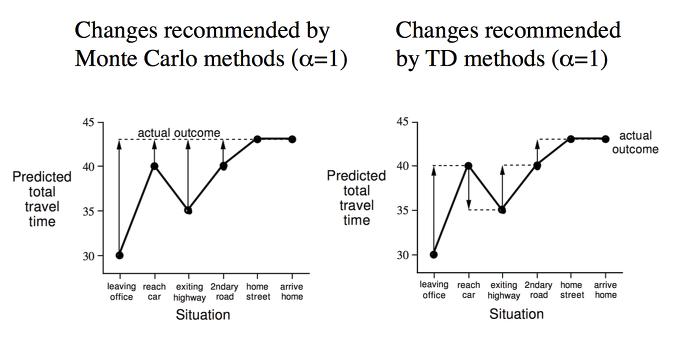
매일 사무실에서 집으로 퇴근할 때 집까지 얼마나 걸릴지 예측해보자. 왼쪽 방법이 몬테카를로 방법, 오른쪽 방법이 TD 방법이다.
고속도로를 빠져나왔을 때, 15분만 더 가면 집을 도착할 줄 알았는데 사실 23분이 더 걸렸다면 이 시각에서 오차는 23-15인 8분이 된다. 이렇게 몬테카를로 방법을 사용하면 추정시간의 변화는 집 도착한 이후에 만들어질 수 있다.
반면에 TD 방법은 즉각적으로 학습을 수행해서 추정값을 35분에서 40분으로 바꾼다. 따라서 각 오차는 시간에 따른 예측값의 변화량인 시간 차에 비례하게 된다.
=> 이처럼 TD의 장점은 종료가 없는 연속적인 에피소드 환경에서도 학습을 할 수 있음!
2. TD 예측 방법의 장점
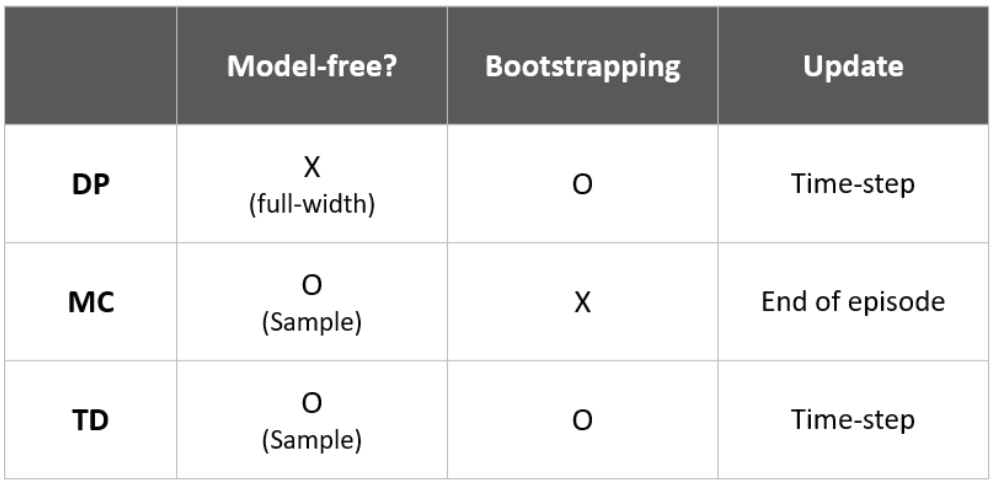
- DP 방법에 비해 환경에 대한 모델, 보상, 다음 상태의 확률 분포를 필요로 하지 않는다. (model free)
- 몬테카를로 방법에 비해 점증적인 방식으로 온라인에서 구현된다. ⇒ 몬테카를로 방법은 에피소드가 끝날 때까지 기다려야 하지만 TD 방법은 한 시간 단계만 기다리면 되므로 새로운 경험이 발생하는 즉시 학습 가능함
- TD 방법과 몬테카를로 방법 모두 올바른 결과로 수렴함을 보장한다. 또 실제 확률론적 문제에서는 TD 방법이 MC 방법보다 보통은 더 빨리 수렴하는 현상이 있었다.
TD 방식의 단점
- 초기값에 대한 민감도가 높음
- 편향된 예측을 할 가능성이 있음
DP/MC/TD 비교
3. TD(0)의 최적성
TD 방법은 무한히 길어질 수 있는 에피소드에서도 가능한 방법이다. 제한된 경험 즉 샘플 데이터를 가지고 학습을 이어나가는 학습법은 학습 결과가 수렴될 때까지 지속하여 제시한다. 이 방법이 가능한 이유는 Batch updating (일괄 갱신)이 되기 때문이다. Batch updating이란 갱신의 과정에서 각 시점에서의 예측마다 갱신하는 방식으로, 이를 반복적으로 수행해 최종 결과(Global optimum)에 도달하게 하는 것이다.
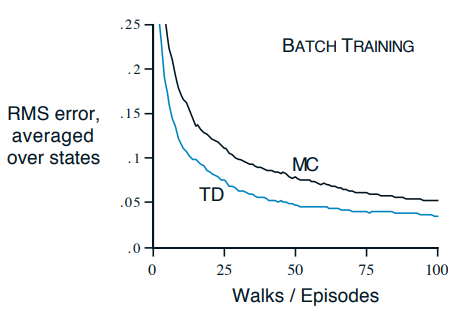
같은 방법으로 MC 방법도 가능하지만 TD가 성능이 더 좋다.
이유는 MC는 정확한 반환값을 기반으로 한 방법이므로 반환값 자체에 대한 정확한 평가가 나오지 않아 이후 개선에서 한계가 보이는 것이다. 하지만 TD는 이전 정책을 통해 예측한 가치 함숫값을 토대로 사용하는 진행 방식으로 더 최적화된 방식이므로 성능이 더 좋다.
확실성 동등 추정(Certainty-equivalence estimate) 개념이 등장한다. 이는 Bootstrapping 방식의 특성이기도 하다. 확실성 동등 추정은 ‘미지의 A 모델에 대해서 Bootstrapping 추정 방식을 사용하여 특정 B 모델을 추출하게 되었다면, B 모델이 실제 A 모델과 같다고 가정하는 것’이다. 이 개념으로 인해서 TD가 MC보다 더 빨리 수렴되는 이유가 설명된다. TD가 구성하는 정책에 대해 확실성을 갖는다는 전제 하에 불필요한 연산을 줄이고 평가와 개선을 이어나가기 때문이다. 이 때문에 편향(Bias)가 발생할 순 있지만 속도는 훨씬 빨라진다.
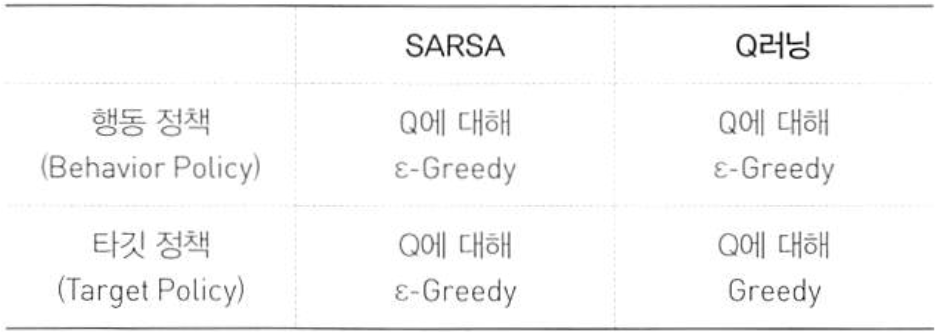
4. SARSA: On-Policy TD Control
- target policy: 목표 정책, 학습자의 정책
- behavior policy: action을 취할 때의 policy, 행동 정책
On-Policy 방법은 현재 policy를 평가하고 개선하는 동안 동일한 정책을 따르는 방법임
target policy = behavior policy
On-Policy 기반의 TD 제어 방법으로 SARSA가 있다. SARSA는 State, Action, Reward, next State, next Action 순서로 진행되는 시퀀스 구성 요소들에서 한 글자씩 따와 명명한 것이다.
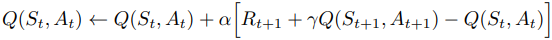
이는 행동 가치 함수 (상태-행동쌍)기반의 알고리즘으로 행동 정책 π에 대해서 qπ를 추정하고 동시에 π가 qπ에 대해 탐욕적이 되도록 π를 변화시키는 것이다.
5. Q-learning: Off-Policy TD Control
Off-Policy 방법은 다른 policy를 따르는 동안 현재 정책을 평가하고 개선하는 방법임
target policy != behavior policy
Off-Policy 기반의 TD 제어 방법으로 Q-learning이 있다.
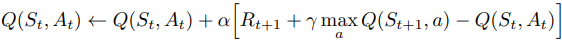
Target policy와 무관하게 Behavior policy를 기반으로 최적 정책을 구성하고 있고, 최대 Q를 target으로 잡아 학습한다. 이로 인해 On-Policy 방법보다 편향이 적다.
SARSA와 Q-learning 예시
절벽이라고 표시된 영역으로 이동할 경우에는 -100의 보상이, 이외의 행동에는 -1의 보상이 주어진다. 목표는 절벽을 피해 시점에서 종점까지 보상을 최대화하는 최적의 경로를 찾는 것이다.
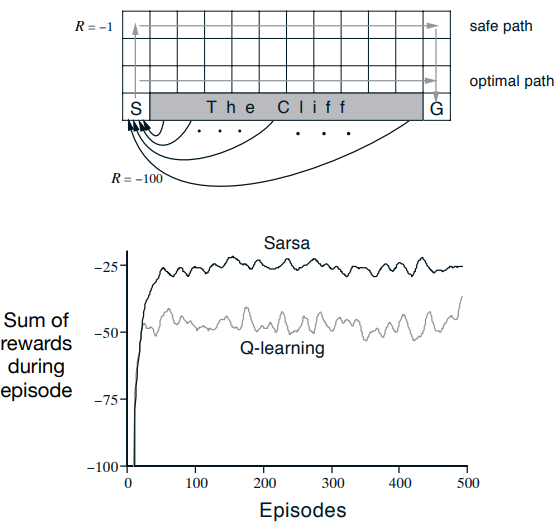
SARSA: 타겟에 의거하여 현재 정책에 기반해서 다음 상태의 향동가치의 평균치를 고려하는 방식이므로 절벽 근처 지점의 상태에 대해서 비관적인 가치평가를 한다. 그래서 절벽에서 멀리 떨어진 상태들을 위주로 경로를 짜서 Safe Path를 형성한다.
Q-learning: 정책에 무관하게 다음 상태의 최대행동가치를 고려하는 방식이므로 주변에 절벽이 존재하는지의 여부와 관계없이 최대가치행동만 보기때문에 최단거리 경로인 Optimal Path를 형성한다.
6. Expected SARSA
On-Policy인 SARSA를 Off-Policy 형태로 변환한 형태이다.
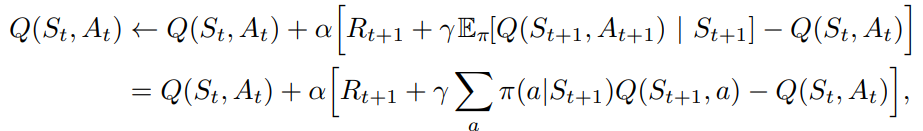
다음 상태 St+1이 주어지면, 기댓값 SARSA 알고리즘은 SARSA가 기댓값을 기준으로 이동하는 방향과 같은 방향으로 결정론적으로 이동한다.
deterministic을 띄는 점에서, 계산량은 많아지지만 At+1에 대한 무작위 선택 때문에 발생하는 분산을 줄여준다. 주로 기댓값 살사가 살사보다 성능이 더 좋다.
장점: SARSA 보다 더 낮은 분산을 가지고, Q-learning보다 작은 optimization overshoot을 보임
