강화학습을 공부해보니 발전과정이 복잡해서 그걸 한번 간단하게 정리해보려고 한다. 각 개념에 대해서는 차차 정리를 자세하게 해보겠다.
1. MDP (Markov Decision Process 마르코프 결정과정)
Markov property 설명 참조
MDP의 핵심은 Markov Property이다.
Markov property란, next state로 이동할 때, past state이 present state에 전혀 영향을 미치지 않는 것을 의미한다. (ex. Brownian motion)
즉, 현재 t만이 미래 t+1을 결정하는 지표이다.
P(St+1|St) = P(St+1|St,St-1,...,S0)
Stocastic process가 Markov property를 가지면 Markov process라고 한다. Markov property를 만족하면 현재 state만 알고 있으면 돼서 확률을 계산하는데 효율적이다.
(만약, 다음 state를 예측할 때, Markov property를 만족하지 않으면, past state에 의존하므로 이전 state들에 대해서 정확히 알아야지 계산이 가능하고 이전 state들을 모두 기억해야 하므로 복잡한 조건부확률을 계산해야 한다.)
MDP: 튜플 형태로 (S,A,P,R,γ)
S: state, A: action, P: state transition(s-> s'), R: reward, γ: discount factor 감가율
2. Bellman 방정식을 이용한 DP (Dynamic Programming)
DP는 복잡한 문제를 작은 문제로 나누어 직접 계산하는 것이다.
DP의 3가지 구성 요소
- Substructure - 하나의 복잡한 큰 문제를 간단한 작은 문제 여러개로 나눈다.
- Table Structure - 작은 문제들을 게산한 후에 해답을 테이블에 기록 하는 것이다. 이후에 같은 문제가 나오면 다시 계산하지 않고 사용함
- Bottom-up Computation - 밑에 있는 작은 문제들을 풀어 큰 문제를 해결하는 것이다. 작은 문제들의 해답을 이용해 -> 더 큰거 -> 더더 큰 문제의 해답 구하기
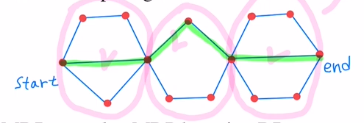 => 제일 짧은것만 다 선택해서 최적으로!
=> 제일 짧은것만 다 선택해서 최적으로!
이런 문제를 풀 때, DP가 효율적이다.
cf. Bellman Equation
-
Optimality - 각 state에서 제일 좋은 action만 선택해서 Bellman Equation 값을 구하는 것 (그래서 수식에 max가 들어가있음)
-
Expectation - 특정 행동의 선택이 확률적으로 결정될때, 이 확률들에 대한 기댓값으로 Bellman Equation 값을 구하는 것
DP의 두가지 방법으로 Value Iteration, Policy Iteration이 있다.
2-1. Policy Iteration (정책 반복)
- bellman expectation equation 사용
- 벨만 기대 방정식을 이용해 정책을 평가하고, 탐욕 정책 발전을 이용해 정책 발전함
- 즉, value가 바뀌지 않을때까지 evaluate해야 한다. (수렴할때까지)
- 오래걸린다는 단점이 있음
2-2. Value Iteration(가치 반복)
- bellman optimality equation 사용
- 최적 정책을 가정하고 벨만 최적 방정식을 이용한다. 정책이 직접적으로 주어지지 않아 큐함수를 통해 행동을 선택한다.
- 정확한 값으로 수렴할 때까지 기다리지 않고 중간에 멈추자! => 각 state를 한번씩 다 갱신한 이후에 value function의 변화량을 계산해보고 그 변화량이 아주 작은 값 이내로 들어오면 반복을 멈춘다.
- Evaluation을 단 한번만 한다.
하지만, DP에는 3가지 문제가 있다.
- 계산복잡도 - 작은 문제로 나누는데 한계
- 차원의 저주 - 테이블에 저장하는데 state space가 너무 커지면 다 기록하기가 어려움
- 환경에 대한 완벽한 정보 - transition probability와 reward를 알고 있어야 함
이 문제를 해결하고자 나온 것이 강화학습 RL이다.
DP는 Planning, RL은 Learning입니다.
계속 얻어지는 reward가 있을텐데 이 reward의 sum인 total reward를 계산하고 policy를 평가하여 total reward를 최대화하는 방향으로 policy를 update하는 것이 강화학습의 기본 틀이다.
강화학습은 주어진 데이터에 대해서만 계산을 하므로 계산 복잡도나 차원의 저주를 해결할 수 있다.
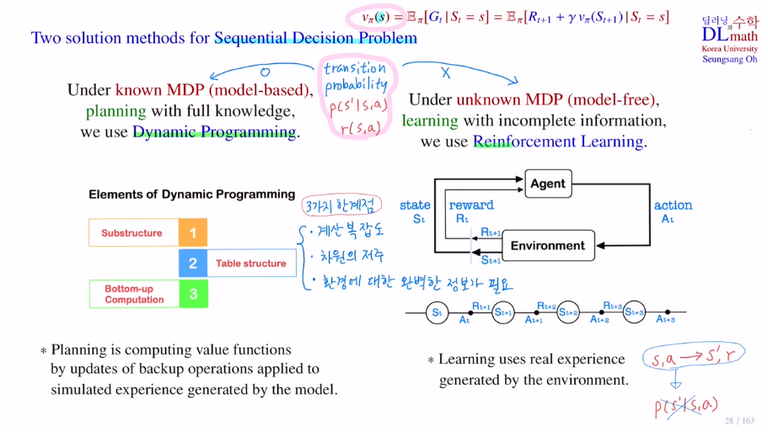
이렇게 RL의 예시로는 MC와 TD가 있다.
이렇게만 일단 봐두고 밑에서 다시 설명하겠다.
(이 그림이 후에 나오는 MC와 TD에 대해서도 잘 설명하므로 첨부한다.)
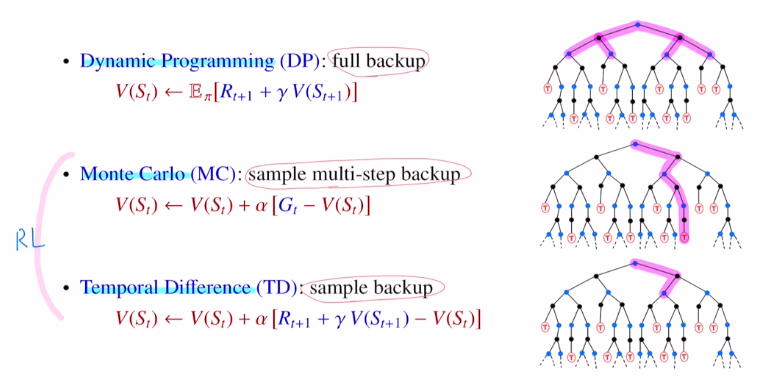
3. MC (Monte Carlo Method 몬테카를로)
MC 알고리즘 설명 참조
몬테카를로 알고리즘은 정확한 값을 얻는 방법이라기 보다는 무작위로 난수를 생성한 후, 원하는 정보의 확률값을 계산하는 알고리즘이다.
MC는 다른 강화학습과 다르게 episode-by-episode로 샘플을 얻어 진행한다.
한 게임이 끝날 때 return을 가지고 진행해서 episodic task이다.
매 샘플로 주어진 episode마다 리턴값을 얻고, 이들의 기댓값이 Q-value를 계산하는데 사용된다.
MC의 장점으로는 state의 개수에 의존하지 않고 확률이 아주 적은 경우들은 배제해주기에 효률적이다. 또, Markov property가 깨져도 크게 영향을 받지 않는다.
MC는 no bootstrapping 방식으로, 끝까지 간 후 return값들의 평균이므로, 현재 state만 다음 state에 영향을 미친다는 Markov Property에 조금의 오차가 생겨도 게임을 끝까지 한 결과에 크게 진행해서 크게 영향을 받지 않는다.
(cf. Bootstrapping이란?
같은 종류의 추정값에 대해서 업데이트를 할 때, 한개 혹은 그 이상의 추정값을 사용하는 것이다.)
(incremental mean을 기록해두는 방식이다.
k까지의 평균을 구하고 싶으면 k-1까지의 평균에 현재 값만 알면 구하기 쉽다.)
3-1. MC control
MC control: ε-greedy policy를 이용해서 MC policy improvement를 진행하는 것
"ε-greedy policy"란?
Exploitation은 이미 알고 있는 정보 내에서 가장 최선의 선택을 하는 것 (greedy)
Exploration은 알고 있는 정보 이외에 더 최선의 방법을 찾는 것 (모험)
=> ε의 확률만큼 Exploration으로 새로운 action을 취하고 1-ε 확률 만큼으로 highest Q-value를 선택하는 것.
이를 통해 가보지 않았던 pair에 대해 방문하며 sampling하는 것, ε확률만큼 손해 볼 수도 있지만 여러번 반복하면 더 좋은 Q값을 찾을 수도 있음.
ε-greedy policy는 stochastic policy가 된다.
4. TD Learning (Temporal Difference Learning 시간차 학습)
자세한 설명: TD Method 설명글
TD의 대표적인 알고리즘으로는 SARSA와 "Q-learning"이 있다.
TD도 policy iteration이지만 GPI(Generalized Policy Iteration)으로, one-step transition이다.
MC의 단점: 게임이 끝날때까지 가야 return 값을 계산함, no-bootstrapping
=> 이를 개선해서 DP처럼 bootstrapping을 이용해서 다음 상태의 실제 값이 아닌 추정값으로 update함

4-1. Sarsa
- ε-greedy policy를 통해 action을 정함
- Sarsa의 타겟이 Bellman expectation eq를 가져온 것
4-2. Q-learning
- agent가 다음 state에서 highest Q값을 갖게하는 action을 선택하는 것
