
소개
강화학습의 시초 같은 논문을 읽어보겠다. NeuralPS (NIPS)에 기재된 논문이다.
이 논문에 대해서 발표를 하게 되어 작성한 ppt를 첨부한다.
PG PPT
Abstract
Function approximation (함수 근사)는 강화학습에서 필수적이지만, value fuction을 근사하고 가치 함수를 기반으로 policy정책을 결정하는 표준 접근 방식은 여전히 다루기 어렵다.
이 논문에서는 이에 대한 대안으로, 가치함수와 독립적인 자체 fuction approximator로 표현하고 expected reward (기대 보상)의 gradient를 사용하여 업데이트하는 방법을 설명한다. 이런 접근 방식의 에시로는 Williams의 reinforce 방법이 있다.
이에 대한 결과로, gradient가 경험을 통해 추정할 수 있는 적절한 형태로 나타낼 수 있고, 이 과정에서 approximate action-value 함수 또는 advantage 함수를 활용할 수 있었다. 이를 바탕으로 임의의 미분 가능한 함수 approximation을 사용하는 policy iteration 방식이 optimal 정책으로 수렴함을 처음으로 증명한다.
Introduction
과거에는 value-function 기반의 접근 방식으로, action-selection policy는 greedy (탐욕적) 정책으로 표현된다.
좀 더 쉽게 말하자면,
이전에는 value-based 접근 방식으로, policy를 또 optimize하지 않고 approximated value function에서 어떤 상태에서 가치 함수를 최대화하는 값을 policy로 정하면 돼서 간단하면서도 좋은 성능을 보였음
(ex. 각 상태에서 가장 높은 추정가치를 갖는 행동을 선택하는 방식)
가치함수 기반 접근 방식은 "2가지 한계"가 있음
1. 가치 함수 기반은 가치 함수의 최대만 취하므로, policy가 deterministic (결정론적)이다.
but 최적 정책은 종종 stochastic (확률적)문제이고, 특정확률로 서로 다른 행동을 선택해야한다.(exploration을 해야함)
2. policy가 max만을 취하므로, 행동의 추정된 가치가 아주 작은 변화를 겪어도, policy에 아주 큰 변화를 낸다.
이런 불연속 변화가 value-based method의 수렴 보장을 얻는데에 큰 장애물이 된다.
이를 해결하기 위해 stochastic policy (확률적 정책)을 직접 근사한다.
Content
value function을 approximate해서 그걸 deterministic 정책을 계산하는데 쓰기보다는 independent policy function을 이용해서 stochastic 정책을 계산하자
policy gradient 접근 방식으로는, p(단계별 평균 reward)에 대해 최대화 되는 방향으로 세타(policy파라미터)를 gradient ascent를 진행함 (아래 수식 참고-알파: step size)
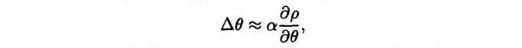
이렇게 하면 value-function 기반 방식과 다르게 세타의 작은 변화-> policy/state-visitation 분포에 작은 변화만 초래한다.
이 논문에서
- 경험을 통해 approximate value function을 이용하면 policy gradient를 편향 없이 추정할 수 있음을 증명함
- 임의의 미분 가능한 함수 approximation을 사용하는 policy iteration 방식을 쓰더라도(정책을 직접 학습하는 방식도) locally optimal policy로 수렴함을 처음으로 증명함
(기존의 경험 기반 REINFORCE 알고리즘보다 더 빠르고 안정적임)
1. Policy Gradient Theorem
learning agent는 MDP(Markov decision process 마르코프 결정 과정)와 상호작용함
