서론
현재 필자는 원티드에서 진행하는 백엔드 프리온보딩 인턴십 교육에 참여중이다. 세션을 진행하던 중 restful api에 대해서 깊게 고민할 수 있는 시간을 가졌다. REST API라는 규격이 생겨난 이유는 사람마다 회사마다 각자의 규격으로 설계하기에 비용을 절감하고 이외에도 무상태, 클라이언트 서버 분리, 캐시처리 등등 요인으로 인해 Representational State Transfer라는 시각으로 등장하게 되었다고 한다. 중요 포인트는 Method와 URL로 응답을 예상할 수 있으면 된다.
이에 초점을 맞추니 내가 개발한 API가 전혀 restful 하지 못하다는 것을 알게되었다.
기존 API
그래서 이게 왜 나왔냐?! 하면 필자는 사용자가 인증된 사용자임을 구현하는 인증코드 전송 api를 개발하고 있었는데 아래와 같이 설계하였다.
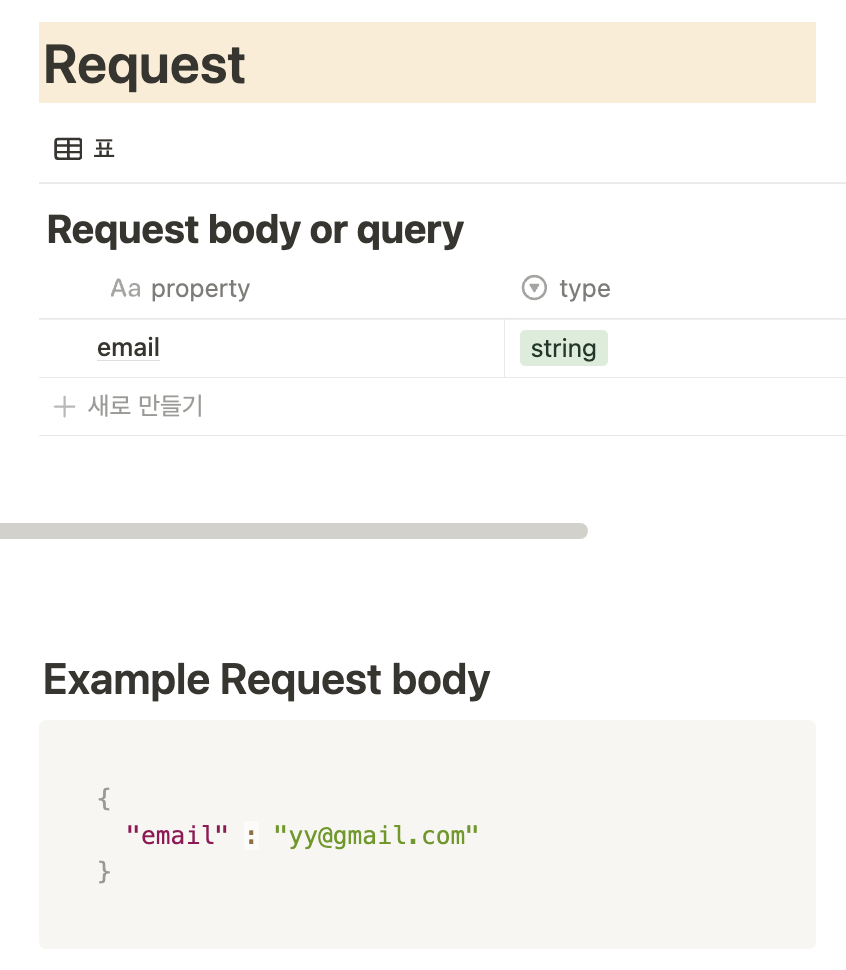
POST 방식으로 body에 사용자의 이메일을 전송하는 것이다. 근데? 프론트입장에서 보았을 때 전송할 때 보면 세션스토리지라던지 여러가지 기법을 통해 사용자의 고유한 코드를 적용할 수 있다. 그렇다면 사용자의 id를 전송하면 되지 않을까? 싶었다.
근데 현재 db 구조는
CREATE TABLE user (
userId INT AUTO_INCREMENT PRIMARY KEY,
account VARCHAR(255) UNIQUE NOT NULL,
email VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL,
createdAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);이렇게 auto increment로 고유 아이디를 생성하고 있다.
그렇다면? api를 요청할 때 /sendCode/:id 이런식으로 get 메소드로 요청하게 되고 이렇게 된다면 다른 유저도 /sendCode/2 이렇게 요청을 보낼 수 있는 것이다. (물론 사용자가 다른 사용자의 정보를 요청하는 경우 403 forbidden 코드를 보내는 등의 절차를 취할 수 있다.)
현직자분께서 말씀해주신 것으로는.... 늘 공격자가 있다는 것을 고려하고 개발에 임하라고 하셨다...
그니까 예측가능한 모델이 되어 SQL Injection의 위험성이 존재하기 때문이다.
그리고 이런 음침한 사람도 있다고 한다... 사실 음침한게 아니라 전략적인 거겠지..?
그래서 고려한 것이 uuid 였다. uuid가 중복될 확률은 하늘에서 길가다가 벼락맞을 확률이라고 하니.. 정말 unique한 것이다 ㅎㅎ
GET과 POST
여기서 어떤 때에는 GET을 쓰고 어떤 때에는 POST를 쓰는데 강사님 말씀으로는 개인마다 다르고 회사마다 다르니 각자의 기준을 정립하라고 했다. 나는 여러가지 레퍼런스와 조언을 들었을 때 아래와 같이 생각한다.
GET
주로 데이터를 조회할 때 사용된다. 명시할 수 있는 데이터면 get을 쓰는 것이 낫다. 서버 데이터에는 변화가 없다. 웹 브라우저나 중간 캐시가 GET 요청의 응답을 캐시할 수 있다.
POST
데이터의 생성 또는 서버에 상태를 변경하는 작업을 요청할 때 사용된다. 이때문에 캐싱이 필요하지 않는다. 민감한 정보를 담아서 무언가를 조회하는 경우에도 POST방식이 보안 측면에서 더 적합하다. get 방식은 url로 브라우저의 히스토리, 서버로그, 네트워크 상에서 쉽게 기록되거나 노출될 수 있기 때문이다. 이와 더불어 HTTPS로 암호화하여 데이터를 보호하자.
사용예시
특정 사용자의 정보 조회: GET /users/123
검색 쿼리에 대한 결과 조회: GET /search?q=example
특정 제품의 상세 정보 조회: GET /products/456
새로운 사용자 생성: POST /users
사용자가 작성한 폼 데이터 전송: POST /contact
새로운 주문 생성: POST /orders
인증을 위한 로그인 요청: POST /login
근데? 또 고려해야할 것은 PUT이다.
PUT과 POST
필자가 하려는 작업은 UUID를 통해 인증 코드를 발급하는 상황이고, 주어진 UUID를 사용하여 verification 테이블에서 인증 코드를 생성하거나 업데이트하는 것은 서버의 상태를 변경하는 작업이다. 이 경우, POST 방식 또는 PUT 방식이 적합한 것이다.
1. POST 방식
- 사용 시점:
- 일반적으로 새로운 리소스를 생성할 때 사용한다.
- 만약 특정 UUID에 대한 인증 코드가 아직
verification테이블에 존재하지 않는다면, 새로운 레코드를 생성하는 작업에 적합하다. - 또한, UUID에 해당하는 레코드가 이미 존재하더라도, 이 레코드에 대한 변경 작업을
POST로 처리할 수 있다.
2. PUT 방식
- 사용 시점:
- 리소스를 생성하거나 전체적인 업데이트를 할 때 사용한다.
- PUT은 주어진 URL에 지정된 리소스가 존재하면 해당 리소스를 완전히 대체하고, 존재하지 않으면 새로운 리소스를 생성하는 데 사용된다.
- 만약 UUID가 주어졌을 때, 그 UUID에 해당하는 인증 코드가 반드시 특정한 형식으로 존재해야 하거나, 전체 레코드를 교체해야 하는 경우에 적합하다.
결론
코드가 없다면 새로 생성하고 있다면 만료시간을 확인해서 새로 업데이트 요청을 하기 때문에 좀 더 유연한 POST방식으로 선택!
왜 UUID?
UUID(Universally Unique Identifier)는 예측이 불가능하고 충분히 긴 고유 식별자이다. 자체는 고유하나 민감한 정보는 아니다.
UUID(Universally Unique Identifier)는 공개 소프트웨어 재단(OSF)에서 만든 고유성이 보장되는 표준 규약이다.
128bits로 구성되어 총 32개의 문자가 5묶음으로 구분되어 있는 형태이다.
(8-4-4-4-12개의 형태)
e6107646-b269-11ed-afa1-0242ac120002
각 필드의 구성 내용은 다음과 같다.
Timestamp - Timestamp - Timestamp & Version - Variant & Clock sequence - Node id
결론은 UUID는 MAC주소 혹은 노드ID를 기준으로 생성해 네트워크 내에서 중복되지 않은 ID로 분산환경에서도 활용할 수 있다.
MySQL에서 성능
근데? uuid를 pk로 삼는 것은 MYSQL의 특징과 데이터의 크기로 인해 비효율적이다.
MySQL의 특징과 데이터 크기
mysql에서는 클러스터드 인덱스(테이블의 데이터가 인덱스에 따라 물리적으로 정렬된다는 것)로 되어 있어 B- 트리 구조로 되어 항상 정렬된 상태를 유지한다.
특히 따로 데이터베이스 설정을 하지 않은 경우 InnoDB 스토리지 엔진으로 설정되어 기본적으로 프라이머리 키가 클러스터드 인덱스로 작동한다.
그래서 UUID를 프라이머리키로 지정하는 경우
비정렬성: UUID는 고유한 식별자를 생성하기 위해 무작위성을 사용한다. 이로 인해 삽입될 때마다 클러스터드 인덱스의 자연스러운 정렬이 깨지며, 디스크 페이지 분할이 많이 발생할 수 있다.
디스크 I/O 증가: 무작위적인 데이터 삽입으로 인해 디스크 페이지가 자주 분할되면서 I/O 작업이 증가하고, 성능 저하가 발생할 수 있다.
인덱스 크기 증가: UUID는 일반적으로 128비트(16바이트) 길이로, 정수형(예: INT 타입)보다 훨씬 크다. 이로 인해 인덱스 크기도 커지며, 캐싱 효율성이 떨어질 수 있다.
다양한 방법
찾아본 방법으로는 이런 방법이 있다.
1. 정렬된 UUID (UUIDv1, UUIDv6 등)
- UUIDv1: UUIDv1은 타임스탬프 기반으로 생성되기 때문에 순차적인 성격을 가지고 있어, 일반적인 무작위 UUID보다 클러스터드 인덱스에서 성능이 더 좋을 수 있다. 그러나 보안 측면에서 유저 식별에 사용하기에 적합하지 않을 수 있다.
- UUIDv6: 이는 비교적 새로운 표준으로, 순차적인 타임스탬프를 기반으로 하지만 무작위성을 일부 포함하여 보안과 성능 사이에서 균형을 잡을 수 있다.
2. 정수형 프라이머리 키 + UUID 서브 키
- MySQL에서AUTO_INCREMENT로 정수형 프라이머리 키를 사용하고, UUID는 별도의 고유 컬럼으로 관리할 수 있다.
- 이 경우, 인덱스는 정수형으로 최적화되며, UUID는 고유성만을 보장하는 용도로 사용된다.
- 테이블 설계 예시:```sql CREATE TABLE verification ( id INT AUTO_INCREMENT PRIMARY KEY, uuid CHAR(36) NOT NULL UNIQUE, verification_code VARCHAR(255) NOT NULL, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 기타 컬럼 ); ``` - 클라이언트와 API 간에는 UUID를 주고받고, 내부적으로는 정수형 프라이머리 키로 성능을 최적화할 수 있다.3. ULID (Universally Unique Lexicographically Sortable Identifier) 사용
- ULID는 UUID의 대안으로, 고유성을 유지하면서도 순차적으로 정렬될 수 있는 식별자를 제공한다.
- ULID는 128비트이며, UUID처럼 고유성을 제공하지만, 생성된 시간순으로 정렬이 가능해 클러스터드 인덱스에 더 적합하다.
찾았던 여러 참고자료들에는 uuidv1를 순차적으로 바꾸는 방법도 존재했고 uuidv7을 사용하는 방법도 존재했다.
포인트는 순차적인 uuid를 찾자는 것이다.
순차적인 uuid
각 방법론은 고유 식별자를 생성하기 위해 사용되며, 성능과 보안 측면에서 다양한 특성을 가지고 있다. 여기서는 UUIDv6, UUIDv7, Sequential UUID, ULID의 차이를 간단하게 설명하겠다.
1. UUIDv6
- 구조: UUIDv6는 기존 UUIDv1을 기반으로 하여, 시간순 정렬을 더 용이하게 하기 위해 일부 필드의 순서를 재배치한 형식이다. 타임스탬프를 앞쪽에 배치하여 시간순으로 정렬할 수 있다.
- 순차성: UUIDv6는 시간 기반으로 순차적인 특성을 가진다. 이로 인해 데이터베이스의 클러스터드 인덱스에서 더 효율적으로 사용할 수 있다.
- 장점: 기존 UUID의 장점(고유성, 범용성)을 유지하면서 순차적인 성격을 가지므로, 삽입 성능이 개선될 수 있다.
- 단점: 여전히 128비트 크기로, 인덱스 크기나 공간 측면에서 일부 성능 이슈가 있을 수 있다.
2. UUIDv7
- 구조: UUIDv7은 타임스탬프 기반이면서도, 좀 더 직관적인 시간 순서 정렬을 위해 설계된 새로운 표준이다. UUIDv6와 마찬가지로 시간 기반 순차성을 가지지만, 생성 속도와 보안성 측면에서 개선이 있다.
- 순차성: 생성된 UUID는 타임스탬프를 기반으로 하며, 기본적으로 순차적인 특성을 가진다.
- 장점: 시간 순서에 따른 고유성이 보장되며, UUIDv1과 v6보다 더 직관적이고 사용하기 쉽다.
- 단점: UUIDv6와 마찬가지로 128비트 크기이며, 인덱스 크기와 공간 사용이 클 수 있다.
3. Sequential UUID
- 구조: Sequential UUID는 일반적인 UUID와 달리, 순차적으로 증가하는 값(예: 타임스탬프 기반)을 포함하여 생성된다. 주로 데이터베이스 성능을 최적화하기 위해 설계되었다.
- 순차성: 타임스탬프나 증가하는 숫자 등을 사용하여 순차적으로 UUID를 생성하여 데이터베이스의 클러스터드 인덱스에서 매우 효율적이다
- 장점: 데이터베이스에서 인덱스 성능을 최적화할 수 있으며, 무작위성이 적어 순차적인 삽입 시 성능 이점을 얻을 수 있다.
- 단점: 무작위성이 부족하여 보안에 민감한 경우 사용하기 어렵고, 고유성에 대한 보장이 다른 UUID 표준보다 떨어질 수 있다.
4. ULID (Universally Unique Lexicographically Sortable Identifier)
- 구조: ULID는 128비트 식별자이지만, 기본적으로 26자 길이의 문자열로 표현되며, 시간순으로 정렬될 수 있도록 설계되었다. 각 ULID는 첫 번째 비트가 타임스탬프 기반이므로 순차적으로 생성된다.
- 순차성: ULID는 타임스탬프를 기반으로 하여, 순차적인 삽입이 가능한 특성을 가진다.
- 장점: 시간 순서에 따라 정렬될 수 있으며, 텍스트 기반 표현이 가능해 사람이 읽기 쉬운 장점을 가진다. 인덱스 크기가 작고, 데이터베이스 성능이 우수하다.
- 단점: 일부 응용 프로그램에서 기존 UUID 표준과의 호환성이 문제가 될 수 있다.
선택 기준:
선택 기준:
- 성능 우선:
Sequential UUID또는ULID가 좋다. 특히, 삽입 성능과 인덱스 크기 측면에서 유리하다. - 기존 UUID와의 호환성:
UUIDv6또는UUIDv7이 더 적합하다. 이는 기존 시스템과의 호환성을 유지하면서도 순차성을 가지는 이점을 제공한다. - 보안 및 고유성:
UUIDv7은 보안과 고유성을 고려한 최신 표준으로, 균형 잡힌 선택이 될 수 있다.
선택과 실험
그래서 나는 총 3가지를 선택하여 실험해보기로 했다.
1. auto increment pk
2. ULID
3. UUIDv7
저장시 속도
필자는 k6 부하 테스트 도구를 사용했다.
auto-increment
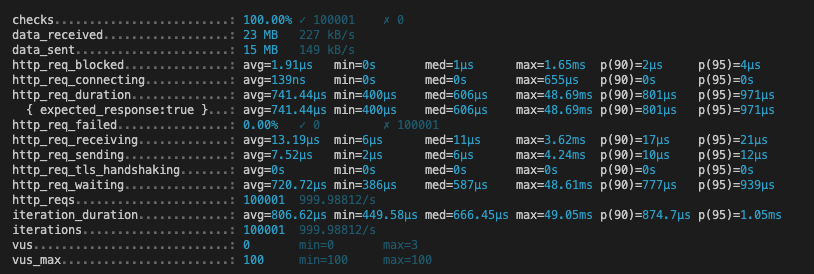
첫번째 시도
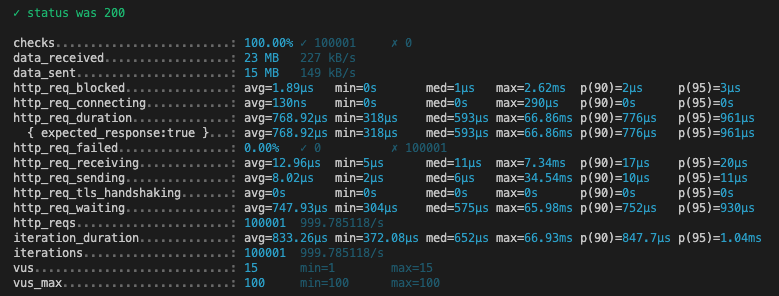
두번째 시도
ulid
첫번째 시도
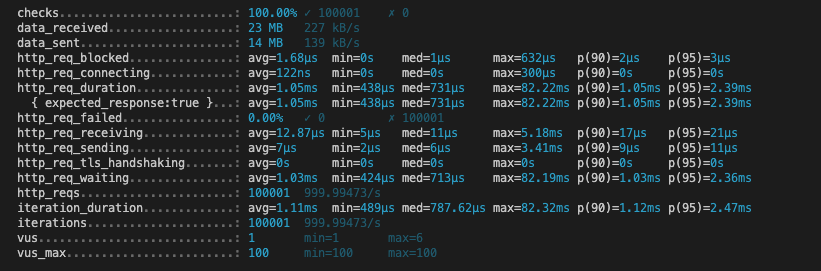
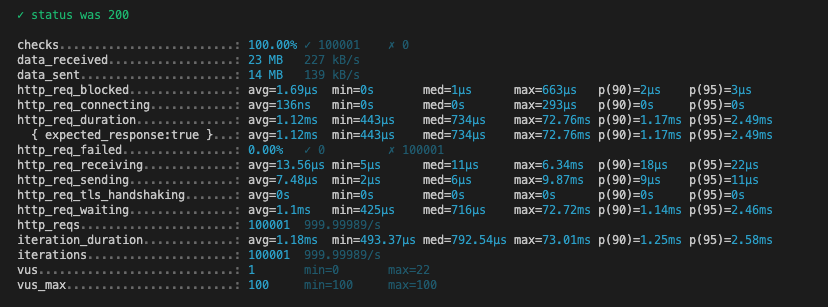
두번째 시도
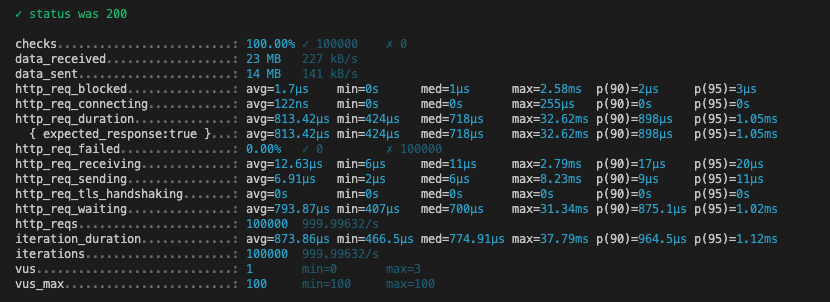
uuidv7
첫번째 시도
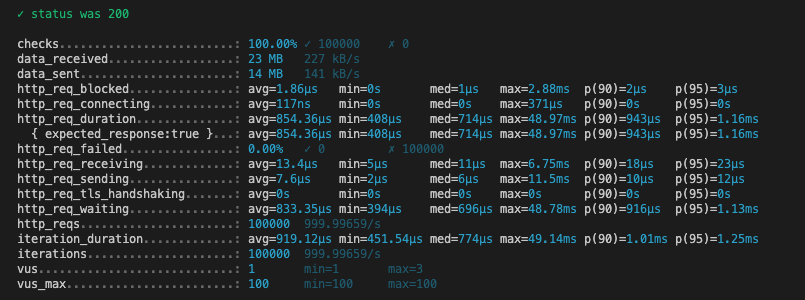
두번째 시도
총 10만행을 저장하는데 걸리는 속도를 비교한 표이다.
첫번째 시도이다.
| 메트릭 | auto | ulid | uuidv7 |
|---|---|---|---|
| HTTP 요청 평균 응답 시간 | 741.44 µs | 1.05 ms | 813.42 µs |
| 최대 응답 시간 | 48.69 ms | 82.22 ms | 32.62 ms |
| 평균 반복 시간 | 806.62 µs | 1.11 ms | 873.86 µs |
auto: 전반적으로 가장 빠른 응답 시간을 보였으며, 최대 응답 시간도 비교적 낮았다.
ulid: 응답 시간이 가장 길었으며, 특히 최대 응답 시간도 가장 높았다. 이는 ULID를 생성하는 데 시간이 더 소요된다는 것을 나타낼 수 있다.
uuidv7: auto보다는 느리지만, ulid보다는 더 빠른 응답 시간을 보였다.
두번째시도이다.
| 메트릭 | auto | ulid | uuidv7 |
|---|---|---|---|
| HTTP 요청 평균 응답 시간 | 768.92 µs | 1.12 ms | 854.36 µs |
| 최대 응답 시간 | 66.86 ms | 72.76 ms | 48.97 ms |
| 평균 반복 시간 | 833.26 µs | 1.18 ms | 919.12 µs |
확실히 데이터가 많아지니 응답 속도가 느려진 것을 확인할 수 있다.
첫 번째와 두 번째 결과를 종합하여 얻을 수 있는 주요 인사이트는 다음과 같다:
-
Auto Increment의 일관된 성능:
auto방식은 두 번의 테스트에서 모두 가장 짧은 평균 응답 시간을 기록했다(741.44 µs 및 768.92 µs). 최대 응답 시간도 다른 방식들에 비해 안정적인 범위 내에 있었다(48.69 ms 및 66.86 ms).- 인사이트:
auto increment방식은 데이터베이스에서 일관되게 빠르고 안정적인 성능을 보여주며, 특히 많은 요청을 처리할 때도 예측 가능한 성능을 유지한다.
-
ULID의 상대적 성능 저하:
ulid방식은 두 번의 테스트에서 모두 가장 긴 평균 응답 시간을 기록했다(1.05 ms 및 1.12 ms). 최대 응답 시간 역시 가장 길었다(82.22 ms 및 72.76 ms).- 인사이트: ULID는 고유 ID를 생성하는 데 시간이 더 걸리며, 이로 인해 고부하 상황에서 다른 방식에 비해 성능이 떨어지는 경향이 있다.
-
UUIDv7의 성능 변동:
uuidv7방식은 첫 번째 테스트에서 최대 응답 시간이 가장 짧았으나(32.62 ms), 두 번째 테스트에서는 그보다 큰 값(48.97 ms)을 기록했다. 그러나 평균 응답 시간은 두 번째 테스트에서 개선되었다(813.42 µs에서 854.36 µs로 약간 증가).- 인사이트: UUIDv7는 성능이 상황에 따라 변동될 수 있지만, 대체로
auto increment와 비교적 근접한 성능을 보여준다. 이는 UUIDv7이 시간 기반 UUID이므로, 데이터베이스의 인덱싱 효율성에 영향을 미치는 것과 관련이 있을 수 있다.
-
전반적인 비교:
auto increment는 가장 일관되고 성능이 우수하며, 대규모 트랜잭션 처리 시 가장 안정적인 선택으로 보인다.ULID는 고유성을 보장하지만, 성능 면에서 다소 손해를 보는 것으로 나타났다.UUIDv7는 상황에 따라 성능이 변동될 수 있지만, 전반적으로auto increment에 가깝게 유지되며, 시간이 중요한 경우에 더 나은 선택이 될 수 있다.
결론:
- 자동 증가(Auto Increment)는 성능 면에서 여전히 가장 안정적이고 빠른 선택이다.
- ULID는 성능보다는 고유 ID 생성의 필요성이 더 중요할 때 고려해야 한다.
- UUIDv7는 성능과 고유성의 균형을 잘 유지하는 선택으로 보이며, 특정 상황에서는 성능 면에서
auto increment에 근접할 수 있다.
구현한 레포가 궁금하다면... 컴 히얼....
uuid 데이터 크기
표준 uuid는 하이픈을 포함해 36자이다. 하이픈을 제거하면 32자이고 unhex 방법을 이용해서 uuid를 16바이트 바이너리 데이터로 변환해 저장할 수 있다. 그래서 BINARY(16)으로 저장할 수 있다. base64로 인코딩한 후 저장할 수 있는데 이는 22~24 바이트이기에 UUID_TO_BIN()을 사용하는 것이 가장 베스트이다.
결론
그래서 데이터베이스의 크기가 어느정도 크게 확보할 수 있는 경제적 여건이 된다면 autoincrement pk + uuid subkey 로 가는 전략을 세울 수 있고 그게아니라면 UUIDv7가 나은 선택이 될 수 있을 것 같다.
그래서 필자는! post로 body에 uuidv7를 담아서 보내는 것으로 수정해야겠다.!!!!!!!!!
이번에 부하 테스트 도구를 써봤는데 10만행 정도로는 mac pro m2의 cpu 10%정도로만 쓰는 것 같아서 역시 돈이 최고라는 생각이 들었다.
참고
https://planetscale.com/blog/the-problem-with-using-a-uuid-primary-key-in-mysql
https://devs0n.tistory.com/39
https://chanos.tistory.com/entry/MySQL-UUID%EB%A5%BC-%ED%9A%A8%EC%9C%A8%EC%A0%81%EC%9C%BC%EB%A1%9C-%ED%99%9C%EC%9A%A9%ED%95%98%EA%B8%B0-%EC%9C%84%ED%95%9C-%EB%85%B8%EB%A0%A5%EA%B3%BC-%ED%95%9C%EA%B3%84
