서론
weaviate에서는 search 기능을 아주 다양한 방법들이 구현되어 있다. 그 방법으로는 공식문서 를 참고하면 더 자세히 알 수 있다. Vector similarity search, Image search, Keyword search, Hybrid search, Generative search, Reranking, Aggregate data, Filters 에 대해서 지원 중이고 필자는 이중 Vector similarity search 를 위주로 deepdive해보겠다.
vector 유사성 검색
기본
from weaviate.classes.query import MetadataQuery
reviews = client.collections.get("WineReviewNV")
response = reviews.query.near_text(
query="a sweet German white wine",
limit=2,
target_vector="title_country", # Specify the target vector for named vector collections
return_metadata=MetadataQuery(distance=True)
)
for o in response.objects:
print(o.properties)
print(o.metadata.distance)이렇게 query에 검색하고 싶은 문장을 작성하고 target_vector를 지정해 해당 속성에 대한 벡터 유사성 검색을 할 수 있다. 그런다음에 벡터 거리를 distance=True설정으로 반환해줄 수 있다.
텍스트 형식으로 검색하는 경우 이렇고 near_object="56b9449e-65db-5df4-887b-0a4773f52aa7" object ID를 기준으로 검색하거나 near_vector=query_vector 벡터를 쿼리할 수도 있다.
query에 제한 걸기
from weaviate.classes.query import MetadataQuery
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.near_text(
query="animals in movies",
distance=0.18, # max accepted distance
return_metadata=MetadataQuery(distance=True)
)
for o in response.objects:
print(o.properties)
print(o.metadata.distance)만일 코사인 유사도로 벡터거리를 계산한다고 했을때(따로 설정하지 않은 경우 코사인 유사도로 설정)만 certainty옵션이 가능하다.
Distance와 Certainty의 차이점

전자의 경우는 값이 낮을 수록 유사한 결과를 나타내며 특정 거리 이하의 결과를 반환하는데 유용하다. 후자는 값이 높을수록 유사한 결과를 나타내며 특정확률 이상의 결과를 반환하는 데 유용하다.
limit & offset
from weaviate.classes.query import MetadataQuery
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.near_text(
query="animals in movies",
limit=2, # return 2 objects
offset=1, # With an offset of 1
return_metadata=MetadataQuery(distance=True)
)
for o in response.objects:
print(o.properties)
print(o.metadata.distance)limit을 걸어서 반환되는 객체를 제한을 줄 수 있고 offset을 통해 첫번째 결과를 건너뒤고 두번째 결과부터 반환할 수 있다.
Group by
from weaviate.classes.query import GroupBy, MetadataQuery
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.near_text(
query="animals in movies",
distance=0.18,
group_by=GroupBy(
prop="points",
number_of_groups=3,
objects_per_group=5
),
return_metadata=MetadataQuery(distance=True)
)
for o in response.groups: # View by group
print(o)
for o in response.objects: # View by object
print(o)
이 예제를 보면 속성을 points로 걸은 다음 속성에 대한 그룹화를 진행한다. 그다음에 유사성 검색을 수행한다.
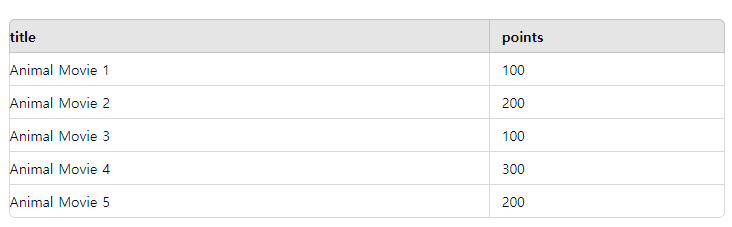
예를 들어 이러한 데이터가 존재할 때 GroupBy를 사용해 points 속성으로 그룹화하면
- 100 포인트 그룹: Animal Movie 1, Animal Movie 3
- 200 포인트 그룹: Animal Movie 2, Animal Movie 5
- 300 포인트 그룹: Animal Movie 4
이렇게 동일한 points값을 가진 객체들이 같은 그룹에 속하게 된다.
Filter걸기
from weaviate.classes.query import MetadataQuery, Filter
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.near_text(
query="animals in movies",
filters=Filter.by_property("round").equal("Double Jeopardy!"),
limit=2,
return_metadata=MetadataQuery(distance=True),
)
for o in response.objects:
print(o.properties)
print(o.metadata.distance)이렇게 특정 속성에 해당되는 값을 필터링을 건다음에 유사성 검색을 할 수 있다.
return 값 커스터마이징
questions = client.collections.get("JeopardyQuestion")
response = questions.query.bm25(
query="animal",
include_vector=True,
return_properties=["question"],
return_metadata=wvc.query.MetadataQuery(distance=True),
return_references=wvc.query.QueryReference(
link_on="hasCategory",
return_properties=["title"],
return_metadata=wvc.query.MetadataQuery(creation_time=True)
),
limit=2
)
for o in response.objects:
print(o.properties) # Selected properties only
print(o.references) # Selected references
print(o.uuid) # UUID included by default
print(o.vector) # With vector
print(o.metadata) # With selected metadata해당 쿼리는 키워드 서치를 위한 bm25 쿼리이다. 벡터 유사성 검사도 해당 반환값과 유사하기에 가져왔다.
이코드에서 보듯이 여러가지 파라미터를 사용해 반환값을 커스터마이징할 수 있다.
그러고 나서 response.objects를 확인해보면 properties, references, uuid, vector, metadata 등의 값을 확인할 수 있다.
Hybrid search
하이브리드 검색은 벡터 검색과 키워드(BM25F) 검색의 결과를 융합해 두 결과 집합을 결합한다. 융합 방법과 상대 가중치는 따로 구성할 수 있다.
score 확인
from weaviate.classes.query import MetadataQuery
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.hybrid(
query="food",
alpha=0.5,
return_metadata=MetadataQuery(score=True, explain_score=True),
limit=3,
)
for o in response.objects:
print(o.properties)
print(o.metadata.score, o.metadata.explain_score)MetadataQuery에서 확인하듯 스코어 설명을 True로 설정하면
{
"data": {
"Get": {
"JeopardyQuestion": [
{
"_additional": {
"explainScore": "(bm25)\n(hybrid) Document df958a90-c3ad-5fde-9122-cd777c22da6c contributed 0.003968253968253968 to the score\n(hybrid) Document df958a90-c3ad-5fde-9122-cd777c22da6c contributed 0.012295081967213115 to the score",
"score": "0.016263336"
},
"answer": "a closer grocer",
"question": "A nearer food merchant"
}
....이렇게 해당 객체가 왜 상위로 검색되었는지에 대한 설명이 같이 반환된다.
가중치 설정
client.collections.get("JeopardyQuestion")
response = jeopardy.query.hybrid(
query="food",
alpha=0.25,
limit=3,
)
for o in response.objects:
print(o.properties)alpha의 값을 조정하면서 어떤 검색에 더 치중할 건지 결정할 수 있다. 1에 가까워지면 벡터 서치에 좀더 가중치를 주는 것이고 0이면 키워드 서치에 더 가중치를 주는 것이다.
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.hybrid(
query="food",
query_properties=["question^2", "answer"],
alpha=0.25,
limit=3,
)
for o in response.objects:
print(o.properties)여기서 보면 question에 ^2 설정을 통해 해당 속성에 두배의 가중치를 부여해줄 수 있다. 그래서 answer 속성보다 question 속성이 더 중요한 것으로 평가될 수 있다.
move to, away
import weaviate
import weaviate.classes as wvc
from weaviate.classes.query import Move
import os
client = weaviate.connect_to_local()
try:
publications = client.collections.get("Publication")
response = publications.query.near_text(
query="fashion",
distance=0.6,
move_to=Move(force=0.85, concepts="haute couture"),
move_away=Move(force=0.45, concepts="finance"),
return_metadata=wvc.query.MetadataQuery(distance=True),
limit=2
)
for o in response.objects:
print(o.properties)
print(o.metadata)
finally:
client.close()
이 예제에서 보면 move_to와 move_away 설정을 해줄 수 있는데 전자는 해당 개념으로 쿼리를 이동시키고 후자는 해당 개념으로 쿼리를 멀어지게 하는 것이다. 그리고 force로 이동에 대한 강도를 나타낼 수 있다.
Filter
필터를 사용하면 제공된 조건에 따라 특정 개체를 결과 집합에 포함하거나 제외할 수 있다. 공식문서 에서 확인하듯이 And, Or, Equal, NotEqual, Greater Than, GreaterThanEqual, LessThan, LessThanEqual, Like, WithinGeoRange, IsNull, ContainsAny, ContainsAll 를 사용할 수 있으니 참고하자
사용법 기초
from weaviate.classes.query import Filter
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.fetch_objects(
# Use & as AND
# | as OR
filters=(
Filter.by_property("round").equal("Double Jeopardy!") &
Filter.by_property("points").less_than(600)
),
limit=3
)
for o in response.objects:
print(o.properties)
# filter with all of
from weaviate.classes.query import Filter
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.fetch_objects(
filters=(
Filter.all_of([ # Combines the below with `&`
Filter.by_property("points").greater_than(300),
Filter.by_property("points").less_than(700),
Filter.by_property("round").equal("Double Jeopardy!"),
])
),
limit=5
)
for o in response.objects:
print(o.properties)이렇게 and 연산자를 표현할 수 있다.
ContainsAny, partial match
from weaviate.classes.query import Filter
jeopardy = client.collections.get("JeopardyQuestion")
token_list = ["australia", "india"]
response = jeopardy.query.fetch_objects(
# Find objects where the `answer` property contains any of the strings in `token_list`
filters=Filter.by_property("answer").contains_any(token_list),
limit=3
)
for o in response.objects:
print(o.properties)이 연산자는 텍스트 속성에서만 작동하며 값 배열을 입력으로 받는다. 그래서 속성의 값 중 하나 이상의 값이 포함된 객체를 일치시킨다.
from weaviate.classes.query import Filter
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.fetch_objects(
filters=Filter.by_property("answer").like("*inter*"),
limit=3
)
for o in response.objects:
print(o.properties)like 연산자를 사용해 inter 이 들어간 내용에 대해서 필터링을 걸 수 있다.
Date datatype
from datetime import datetime, timezone
from weaviate.classes.query import Filter, MetadataQuery
# Set the timezone for avoidance of doubt
filter_time = datetime(2022, 6, 10).replace(tzinfo=timezone.utc)
# The filter threshold could also be an RFC 3339 timestamp, e.g.:
# filter_time = "2022-06-10T00:00:00.00Z"
response = collection.query.fetch_objects(
limit=3,
# This property (`some_date`) is a `DATE` datatype
filters=Filter.by_property("some_date").greater_than(filter_time),
)
for o in response.objects:
print(o.properties) # Inspect returned objects날짜 데이터 유형 속성을 기준으로 필터링 하려면 날짜/시간을 RFC 3339 타임 스탬프 또는 Python 날짜/시간 개체와 같은 클라이언트 라이브러리 호환 유형으로 지정한다.
from datetime import datetime, timezone
from weaviate.classes.query import Filter, MetadataQuery
collection = client.collections.get("Article")
# Set the timezone for avoidance of doubt (otherwise the client will emit a warning)
filter_time = datetime(2020, 1, 1).replace(tzinfo=timezone.utc)
response = collection.query.fetch_objects(
limit=3,
filters=Filter.by_creation_time().greater_than(filter_time),
return_metadata=MetadataQuery(creation_time=True)
)
for o in response.objects:
print(o.properties) # Inspect returned objects
print(o.metadata.creation_time) # Inspect object creation time그래서 이렇게 시간을 설정하고 해당 시간보다 더 지난 시간 즉 2020년 1월 1일보다 이후에 생성된 데이터에 대해서 필터를 걸고 MetadataQuery를 통해 생성시간을 반환하게 한다.
