📚 문자열 검색
문자열 검색은 어떤 문자열 안에 다른 문자열이 포함되어 있는지 검사하고, 만약 포함되어 있다면 어디에 위치하는지 찾아내는 것
- 텍스트 : 검색되는 전체 문자열
- 패턴 : 검색할 부분 문자열
문자열에서 부분 문자열을 검색하는 알고리즘 중 브루트 포스법, KMP법, 보이어/무어법에 대해 알아보자!
브루트 포스법
문자열 검색 알고리즘 중 가장 기초적이고 단순한 검색 방법
선형 검색을 단순하게 확장한 알고리즘이며, 이미 검사한 위치를 기억하지 못하기 때문에 비효율적이다.
연산자와 라이브러리를 사용한 문자열 검색
1) 멤버십 연산자 : in, not in
pattern in text
pattern not in text이 방법은 포함 여부는 판단할 수 있지만 위치(인덱스)는 알 수 없다.
2) find, index 계열 함수 : find(), rfind(), index(), rindex()
text.find(pattern[, start[, end]]): pattern 문자열이 존재하면 가장 작은 인덱스를 반환하고, 그렇지 않으면 -1 반환
-text.rfind(pattern[, start[, end]]): pattern 문자열이 존재하면 가장 큰 인덱스를 반환하고, 그렇지 않으면 -1 반환text.index(pattern[, start[, end]]): find() 함수와 같지만 pattern 문자열이 존재하지 않으면 예외 처리로 ValueError가 발생text.rindex(pattern[, start[, end]]): rfind() 함수와 같지만 pattern 문자열이 존재하지 않으면 예외 처리로 ValueError가 발생
KMP법
브루트 포스법과 달리 검사한 결과를 효율적으로 사용할 수 있는 알고리즘
브루트 포스법은 일치하지 않는 문자열을 만나면 이전 단계에서 검사했던 결과를 버리고 패턴의 첫 문자부터 다시 검사를 수행한다.
KMP법은 접두사와 접미사라는 개념을 통해 문자열 검색 횟수를 줄이는 방법이다.
문자열을 검사하다가 불일치가 발생하면 해당 위치 전까지의 문자열에서 접두사(문자열의 앞)와 접미사(문자열의 뒤)가 일치한 최대 길이를 확인하여 그 길이만큼 탐색 문자열을 건너뛰어 검색한다.
KMP 검색 과정
1) 전체 문자열 'ababdababa'에서 ababa를 찾는다.

이때 5번째 문자에서 불일치가 발생한다.
불일치가 발생한 부분 전까지의 문자열에서 접두사와 접미사 부분이 일치했던 최대 문자열이 'ab'였다. (앞의 'ab' = 뒤의 'ab')
2) 따라서 KMP법에서는 일치했던 문자열의 길이인 2만큼 건너뛴 후 문자열 검색을 다시 시도한다.

실패 함수
KMP법에서 어떻게 건너뛸 길이를 정할까?
KMP법에서는 실패 함수를 만들어 이전까지 상황을 참고할 수 있는 표를 제공한다.
2개의 인덱스 (i, j)를 이용해 실패 함수 표를 만들어보자!
j와 i가 가리키는 두 문자가 일치하면 두 개의 인덱스를 모두 증가시키고, 일치하지 않으면 이전까지의 실패 함수를 참고한다. 만약 참고할 값이 없으면 0이 된다.

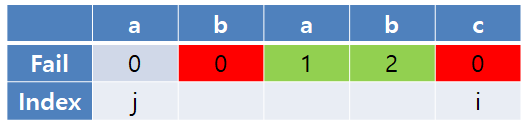
위에서 검색했던 문자열 'ababa'이다.
실패 함수의 첫 번째 항목은 0이다.
현재 i와 j가 가리키는 문자가 불일치하므로, 이전까지의 실패 함수를 참고해야 하지만 이전 상태의 실패 함수 값이 0이다.
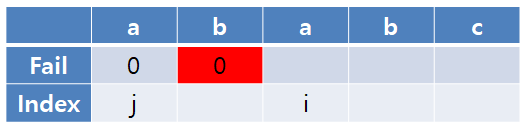
따라서 i번째 실패 함수 값은 0으로 갱신되고, i를 증가시킨다.
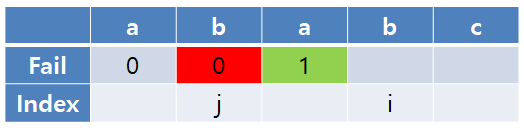
다음 비교 시 i와 j의 문자가 일치하면 j+1의 값이 i번째 실패 함수 값이 되고, i와 j 모두 증가시킨다.
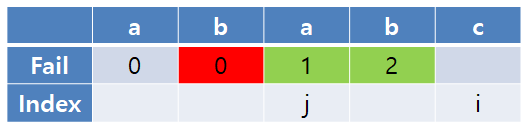
다음 비교에서도 두 문자가 일치하므로 i번째 실패 함수 값은 2가 되고, i와 j를 증가시킨다.
다음 비교에서는 두 문자가 불일치하므로, j를 감소시킨 후 다시 문자를 비교한다. 불일치가 반복되면 j가 0이 될 때까지 반복한다.