📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
1. 시스템 모델
본격적으로 들어가기에 앞서, 데드락의 정의부터 다시 보고 가자.
💡 Situation in which every process in a set of processes is waiting for an event that can be caused only by another process in the set.
임의의 프로세스 집합 안의 모든 프로세스가 waiting 상태이며,
해당 집합 안의 프로세스만이 waiting 상태를 해제할 수 있는 상황
이제 본격적으로 시스템 모델에 대해서 알아보자.
💡 A system consists of a finite number of resources to be distributed among a number of competing threads. The resources may be partitioned into several types (or classes), each consisting of some number of identical instances. CPU cycles, files, and I/O devices are examples of resource types.
시스템은 여러 쓰레드 간의 경쟁을 일으킬 수 있는 한정된 자원들을 가지고 있다.
자원들은 여러 타입으로 나뉠 수 있고, 각 타입은 여러 인스턴스를 가지고 있다.
CPU 사이클, 파일, I/O 디바이스 모두 자원의 예시이다.
또다른 예로, 4개의 CPU가 있다면 CPU라는 타입의 자원이 4개의 인스턴스를 갖는 것이다.
결국 시스템을 추상적으로 봤을 때, 모든 요소들을 "자원"으로서 보고 있다.
그리고 쓰레드가 어떠한 자원을 "요청"하면, 시스템은 그에 대한 응답을 할 수 있어야 한다.
여태까지 배웠던 뮤텍스락과 세마포어도 모두 시스템의 자원의 일종이다.
특히, deadlock을 일으킬 수 있는 주요 원인이기도 하다.
뿐만 아니라, 쓰레드는 IPC를 통해 다른 프로세스의 자원도 요청할 수도 있다.
단, 모든 쓰레드는 다음과 같은 순서를 통해 자원을 다루어야 한다
- Request: 자원에 대한 요청을 해야 하고, 현재 불가능하다면 대기해야 한다.
- Use: 자원에 대한 각종 연산을 수행할 수 있다. (수정, 읽기 등)
- Release: 사용 이후에 자원을 해제해야만 한다.
Use의 경우에는 특별한 함수가 있는 것이 아니고, 일반적으로 변수를 다루는 행위이다.
Request와 Release 쌍은 시스템콜로 이루어져 있을 가능성이 있다.
대표적으로, 세마포어의 wait()의 signal()이 해당 역할을 대신한다.
흔히 파일을 열고 닫는 open()과 close() 시스템콜 역시 마찬가지이다.
이 "자원"에 대한 개념은 데드락을 이해하는 데에 용이하게 사용된다.
Livelock (라이브락)
데드락으로 본격적으로 들어가기 전에, 또다른 활성 보장 실패인 livelock에 대해 알아보자.
(라이브락은 "활성 교착 상태"라고 불리기도 한다)
라이브락은 데드락과 비슷하게 프로세스가 진전을 못하는 상황이지만,
반대로 blocking 상태는 아닌 현상을 얘기한다.
실생활 예시로 들었을 때,
2명의 사람이 좁은 복도에서 만나 서로 길을 비키려고 한다.
한명이 왼쪽으로 비켜줬는데 다른 한명도 같은 방향으로 비킨다.
그래서 둘다 계속 왔다갔다 하면서 비켜주기만 하는 상황과 비슷하다.
다시 쓰레드의 경우로 돌아와서, 2개의 쓰레드가 2개의 lock을 얻어야 하는 상황을 예로 들자.
POSIX의 pthread_mutex_trylock()가 대표적으로 위 상황을 발생시키는데,
위 함수는 락을 획득하는 것을 시도하는데, 실패 시에 본인 락을 내려놓는 로직이다.
그런데 두 쓰레드가 계속해서 lock을 놓고 상대 것을 집는 것을 반복한다면?
뭔가를 계속 시도는 하는데 진전은 전혀 없는 상황이 벌어진다.
데드락에 비해서 잘 일어나지는 않지만, 그래도 치명적인 상황은 맞다.
그래도 라이브락은 일반적으로 사용되는 해결 방법이 하나가 있다.
lock 취득에 실패할 경우, 랜덤한 시간 뒤에 다시 시도하는 방식이다.
예를 들어 쓰레드1이 0.1ms 뒤에 시도하고, 쓰레드2가 0.2ms 뒤에 시도한다면,
쓰레드1이 먼저 2개의 lock을 모두 들어서 정상적으로 진행이 될 것이다.
2. 데드락의 특성 (정의)
필수 조건
💡 A deadlock situation can arise if the following four conditions hold simultaneously in a system.
데드락은 아래의 4가지 조건이 전부 성립하는 경우 발생할 수 있다.
-
Mutual Exclusion (상호 배제)
하나의 자원은 오로지 하나의 쓰레드만이 들고 있을 수 있다. -
Hold and Wait (점유와 대기)
모든 쓰레드는 최소 하나의 자원을 들고 있는 상태에서,
다른 쓰레드가 들고 있는 자원을 요청해야 한다. -
No Preemption (비선점)
자원은 선점될 수 없다. (다른 쓰레드가 뺏을 수 없다)
오직 작업이 끝난 쓰레드의 자의로만 자원이 해제될 수 있다. -
Circular Wait (원형 대기)
기다리는 쓰레드의 집합 내에서, 꼬리물기의 형태로 자원을 기다려야 한다.
T0이 T1을, T1이 T2를, ..., T2가 Tn을, 그리고 Tn이 T0을 기다리는 경우다.
위 조건 중 하나라도 만족하지 않으면 데드락은 발생할 수 없다
💡 The ciruclar-wait condition implies the hold-and-wait condition, so the four conditions are not completely independent.
원형 대기가 점유와 대기 상태를 내포하고 있음으로, 위 4가지 조건은 독립적이진 않다.
그럼에도 굳이 2가지 조건으로 나눈 이유는,
아래에서 배울 해결 방안 중 예방 방법에서 쓰이기 때문이다.
자원 할당 그래프
💡 Deadlocks can be described more precisely in terms of a directed graph called a system resource-allocation graph.
데드락은 "system resource-allocation graph"을 통해 정확히 설명될 수 있다.
자원 할당 그래프는 단방향 그래프이고, 쓰레드와 자원들의 할당 상태를 보여준다.
아래 그래프를 먼저 보고 각 도형이 무슨 의미를 갖는 지 알아보자.
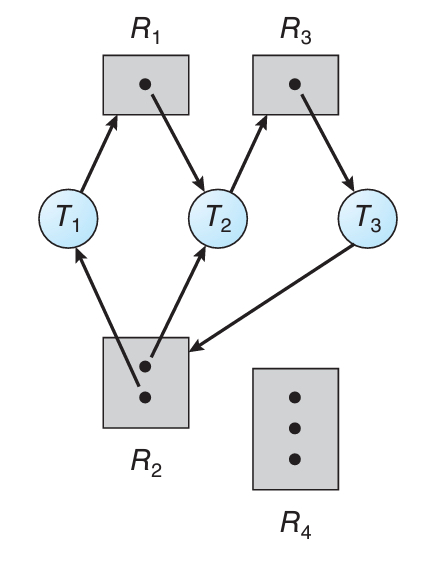
- 사각형은 자원을 뜻하는 도형이다. 모든 사각형은 어떤 자원인지 Rn으로 표시된다.
사각형 내부의 점은 자원의 인스턴스를 얘기한다. - 원은 하나의 쓰레드를 의미한. 어떤 쓰레드인지 Tn으로 표시된다.
- T→R : 쓰레드가 해당 자원을 요청 중에 있다는 뜻이다.
화살표가 사각형까지만 갔다면 남아있는 자원이 없어서 아무거나 기다리는 중이다. - R→T : 자원이 해당 쓰레드에 종속되어 있다는 뜻이다. (쓰레드가 자원을 들고 있음)
참고로 T→R 형태가 "요청 간선" (request edge)이고,
R→T 형태가 "할당 간선" (assignment edge)이다.
다시 위의 그림으로 돌아와서, 어떻게 데드락을 판별하는지 보자.
💡 Given the definition of a resource-allocation graph, it can be shown that, if the graph contains no cycles, then no thread in the system is deadlocked. If the graph does contain a cycle, then a deadlock may exist.
사이클이 존재하지 않다면, 데드락은 발생하지 않는다.
사이클이 존재한다면, 데드락이 발생할 "가능성"이 있다.
여기서 중요한건, 사이클이 있다고 데드락도 있는 것이 아니라는 것이다!
그러면 어떤 경우가 데드락이 생기는 걸까?
여기서 다시 2가지 경우의 수로 나눌 필요가 있다.
첫째, 사이클에 포함된 모든 자원이 인스턴스를 하나씩만 가지고 있다면,
모든 자원이 묶여있다는 뜻임으로 데드락이 발생했다는 사실이 자명하다.
둘째, 사이클에 포함된 자원에 여러 인스턴스를 가지는 경우가 있다면,
여기서는 다시 데드락이 발생했다고 보기 힘들다.
이 상황에 대해서는 아까 위의 그림과 아래의 그림을 비교해보면 된다.
우선 위의 그림을 보면, R2가 2개의 인스턴스를 가지고 있기는 하지만,
2개의 인스턴스 모두 사이클에 포함된 쓰레드가 이미 할당을 받은 상태이다.
또한, 그 인스턴스를 가지는 쓰레드는 모두 다른 자원을 기다리고 있는 상태이기도 하다.
이 경우에는 데드락이 발생했다고 얘기할 수 있는 것이다.
이제 사이클도 있고, 인스턴스도 여러개인 다른 그래프를 예를 들어보자.
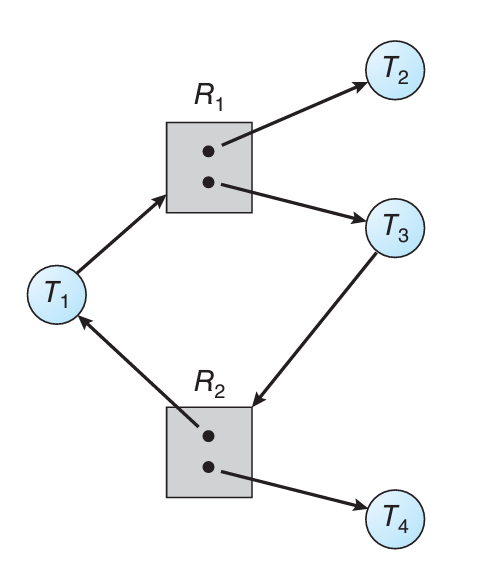
이 경우에도 모든 자원에 화살표가 존재하기 때문에 데드락처럼 보일 수 있지만,
사실 T2와 T4에 의해 자원이 풀려날 것임으로 데드락이 아니다.
T4를 먼저 보면, 자원을 가지고는 있지만 더이상 요청하는 자원이 없는 상황인데,
그러면 T4는 금방 R2 자원의 인스턴스 하나를 내려놓게 된다.
이후 T3가 해당 인스턴스를 줍게 되고, 본인의 작업을 시작할 것이다.
그러면 다시 T3가 일을 끝냈다면 R1의 인스턴스가 하나 풀리게 되고,
이를 T1이 줍게 되는 식으로 차근차근 꼬였던 간선들이 풀리게 된다.
이러한 자원 할당 그래프를 이해하는 것은 데드락을 다루는 데에 있어서 중요하다.
3. 데드락 대처 방안
💡 Generally speaking, we can deal with the deadlock problem in one of the three ways.
일반적으로, 데드락을 "대처"하는 방법은 크게 3가지가 있다.
- 발생할 수 있는 문제를 무시하고, 데드락이 발생하지 않을 것이라고 가정해버리는 것
- 데드락 상태로 도달할 수 없게 방지하거나 회피하는 프로토콜을 사용하는 것
- 데드락 상태로 진입할 수는 있게 하나, 이를 탐지하고 회복하는 것
우선 첫번째 방식인 "무시"는 간단하다.
커널 개발자나 애플리케이션 개발자에게 데드락을 직접 대처하게 책임을 전가하는 것이다.
대부분의 운영체제는 이 방식을 사용한다 (Windows, Linux)
데이터베이스는 데드락이 치명적이기 때문에 3번 방법을 체택하고는 한다.
두번째 방식의 포인트는 데드락 상태에 애초에 도달하지 못하게 막는 것인데,
이 방식은 크게 2가지 접근 방식이 있다.
하나는 데드락이 발생하는 4가지 조건 중 하나를 무시하는 것이다.
그로 인해 여태 쌓아올린 시스템의 구조가 살짝 바뀌겠지만 감안하겠다는 방식이다.
다른 하나는 운영체제가 각 자원과 쓰레드의 관계를 감시하고 있는 것이다.
특정 기준에 따라서 데드락 상태에 도달할 가능성을 배제하는 방식이다.
세번째 방식이 데드락을 허용하되, 상황을 파악해서 다시 회복하겠다는 방식이다.
이 과정에서 현재 상태를 "탐지"하는 알고리즘 하나와,
데드락이 발생했다면 "회복"을 하는 알고리즘이 하나씩 필요하다.
그러나 다시 말하지만, OS는 아무런 알고리즘 없이 데드락을 방치한다.
이는 데드락을 무시했을 때의 피해와 데드락을 해결하기 위한 소모를 저울질한 결과이다.
실제로는 데드락이 발생할 확률은 극히 낮고, (예를 들어 한 달에 한 번)
데드락을 해결하기 위한 각종 알고리즘은 그만큼 CPU를 사용해야 하기 때문이다.
4. 예방
💡 By ensuring that at least one of these conditions cannot hold, we can prevent the occurrence of a deadlock.
4가지 조건 중 하나를 충족하지 못하게 함으로써, 데드락 발생을 막을 수 있다.
앞서 살펴봤던 4가지 조건 들을 하나씩 살펴보면서 어떻게 데드락을 막는지 보자.
a) 상호 배제
💡 The mutual-exclusion condition must hold.
상호 배제는 반드시 충족해야 하는 조건이다.
사실 데드락이 발생하는 이유가 lock을 사용하기 때문인데,
lock은 다시 데이터의 일관성을 지키기 위해 사용는 것이다.
결국 이 조건을 무시하는 것은 일관성을 신경쓰지 않겠다는 말인데,
애초에 말이 되지 않는 방법이다.
b) 점유와 대기
이 조건을 무시하는 첫번째 프로토콜은, 쓰레드가 실행 전에 모든 자원을 획득하는 것이다.
그러나 점점 쓰레드가 많아지는 복잡한 환경에서는 현실성이 떨어진다.
또 다른 프로토콜은 쓰레드가 어떠한 자원을 들고 있지 않은 상태에서만 요청하는 방법인데,
어떤 요청을 하든간에 현재 들고있는 모든 자원을 놓아야만 한다.
위의 프로토콜들은 2가지 주요 결점이 있다.
-
자원의 효율이 낮다.
하나의 자원을 오래 들고 있는 상황이기 때문에,
할당이 되었음에도 실질적으로 자원이 사용되는 시간이 낮을 수 있다. -
기아 현상이 발생할 수 있다.
인기가 많은 자원들을 필요로 하는 쓰레드가 영원히 실행되지 못할 수도 있다.
c) 비선점
말그대로 비선점을 무시하려면 선점형으로 바꾸기만 하면 된다.
우선 쓰레드가 어떠한 자원을 요청할 때 해당 자원을 다른 쓰레드가 들고 있다면,
들고 있는 쓰레드가 다른 자원을 기다리는 중인지 체크하고 뺏으면 된다.
(실행 중인 쓰레드의 자원을 뺏을 수는 없다)
실제로 이 방식은 상태가 쉽게 저장되고 복원될 수 있는 자원에 대해서 사용된다.
CPU 레지스터와 DB 트랜잭션이 대표적으로 이 방식이 사용 가능한 자원이다.
반대로, 뮤텍스락이나 세마포어에 대해서는 사용하기 힘들다는 한계가 있다.
d) 원형 대기
여태 살펴본 3가지 옵션은 실용 가능성이 많이 떨어진다.
그러나, 원형 대기를 무시하는 방법은 사용 가능한 방법을 제시한다.
💡 One way to ensure that this condition never holds is to impose a total ordering of all resource types and to require that each thread requests in an increasing order of enumeration.
해당 조건이 성립되지 않게 하는 하나의 방법은 모든 자원에 순서를 부여하는 것이다.
각 쓰레드는 자원 요청을 자원의 오름차순으로 진행해야만 한다.
예를 들어서 T0과 T1이라는 2개의 쓰레드가 있고,
총 자원은 R0부터 R4까지 5개가 있다고 가정하자.
그리고 T0이 R1, R2, R4를 요청하고 있고 T1은 R1, R2를 요청하는 상황이라면?
각 자원에 대해서는 lock이 걸려있을 것이므로, 아무 쓰레드 (T0)이 먼저 R1을 얻었다고 치자.
그 상황에서 T1이 R2를 접근하려고 하면, 아직 R1을 얻지 못했기에 획득하지 못한다.
그래서 R1을 얻으려고 계획을 바꿔도, 이미 T0이 들고 있음으로 R1도 획득하지 못한다.
이 방식은 수학적으로 증명이 되니 관심이 있다면 따로 공부를 해보자.
단, 이 방법은 2가지 프로토콜로 구분이 되는데,
자원에 넘버링을 하는 프로토콜과, 오름차순으로만 요청해야하는 프로토콜이다.
자원의 넘버링은 시스템 차원에서 제공해야 하지만,
요청을 오름차순으로 하는 방식은 개발자가 직접 유의하여 코드를 작성해야 한다.
5. 회피
💡 An alternative method for avoiding deadlocks is to require additional information about how resources are to be requested.
...
With this knowledge of the complete sequence of requests and releases for each thread, the system can decide for each request whether or not the thread should wait in order to avoid a possible future deadlock.
데드락을 피하는 또다른 방법은 어떤 자원이 요청될 것인지에 대한 정보를 가지는 것이다.
이러한 정보를 바탕으로, 요청에 대해 자원을 할당할지 말지 미리 판단할 수 있다.
즉, 추가 정보를 바탕으로 발생가능한 데드락을 미리 방지하는 방법인 것이다.
그렇다면 그 추가 정보에는 어떤 것이 있는 걸까?
어떤 정보를 요구하냐에 따라 다양한 알고리즘이 존재한다.
💡 The simplest and most useful model requires that each thread declare the maximum number of resources of each type that it may need.
가장 간단하고 활용도가 높은 모델은 각 쓰레드가 본인이 필요로 할 수 있는 자원의 개수를 각 자원의 타입에 대해서 "최대치"를 설정하는 것이다.
그러면 시스템은 각 쓰레드의 "최대 자원 수"와 "현재 재원 수"를 보면서,
자원을 어떤 쓰레드에 할당해도 "안전한 상태"를 유지하는지를 확인하는 것이다.
Safe State (안전 상태)
💡 A state is safe if the system can allocate resources to each thread (up to its maximum) in some order and still avoid a deadlock. More formally, a system is in a safe state only if there exists a safe sequence.
안전상태는 각 쓰레드에게 최대치까지 자원을 할당해도 데드락을 피할 수 있는 상태이다.
정확하게는, "safe sequence"가 존재하는 경우가 안전상태이다.
safe sequence가 무엇인지 보기 전에, 안전상태가 무엇인지 부터 확실히 하자.
정의로 보면 어려울 수 있는데, 쉽게 말해 데드락이 절대로 발생할 수 없는 상태를 얘기한다.
일단 예시를 보면서 천천히 살펴보자.
아래는 12개의 인스턴스를 가지는 하나의 자원 타입에 대한 요청 표이다.
| 쓰레드 | 최대로 필요한 자원 | 현재 필요한 자원 |
|---|---|---|
| T0 | 10 | 5 |
| T1 | 4 | 2 |
| T2 | 9 | 2 |
| 시스템 | 12 | 3 |
가장 먼저 현재 필요로 하는 자원의 총 수는 5+2+2=9개 이다.
그런데 자원이 총 12개가 존재한다고 했으니, 당연히 문제없는 상황이다.
그러나 우리가 알고싶은 안전상태는 말그대로 현재 안전한지를 물어보는 것이 아니다.
모든 쓰레드에게 순차적으로 최대치까지 자원을 할당해도 계속 이 상황이 지속되는 지이다.
다시 위의 표로 돌아가서 정리하자면, 총 9개의 자원이 할당되고 3개의 자원이 남는다.
이 상황에서 자원 2개를 T1에게 주었다고 치자.
그러면 T1은 현재 들고 있던 자원 2개에 새로운 자원 2개를 추가하여 최대치를 달성한다.
최대치를 달성했으니 T1이라는 쓰레드는 반드시 task를 끝낼 수 있다는 뜻이 된다.
확실히 끝날 수 있음을 확인했음으로, T1은 들고 있던 모든 자원을 내려놓는다.
그러면 시스템은 아까 준 자원 2개를 돌려받고, T1은 이제 무시할 수 있다.
여기까지 진행된 상황으로 다시 표로 정리해보자.
| 쓰레드 | 최대로 필요한 자원 | 현재 필요한 자원 |
|---|---|---|
| T0 | 10 | 5 |
| T1 | - | - |
| T2 | 9 | 2 |
| 시스템 | 12 | 5 |
이제 시스템은 남은 자원 5개를 누구한테 주어야 할까?
T2에게 준다면 최대치를 만족하지 못하니 T0에게 주어야 한다!
이처럼 자원을 줘야하는 쓰레드의 순서가 굉장히 중요하다!
다시 돌아와서 T0이 자원 5개를 받았다고 치자.
그러면 T0은 T1과 마찬가지로 최대치가 되었으니 확실하게 task를 마칠 수 있다.
여기까지 안전한 상태를 유지할 수 있음을 확인했으니 T0의 자원을 다시 시스템이 가져간다.
마지막으로 현재 상태의 표를 보면서 마무리하자.
| 쓰레드 | 최대로 필요한 자원 | 현재 필요한 자원 |
|---|---|---|
| T0 | - | - |
| T1 | - | - |
| T2 | 9 | 2 |
| 시스템 | 12 | 10 |
이제는 T2에게 남은 자원을 전부 주면 T2도 잘 마무리 될 것이다.
여태까지 따라온 쓰레드의 순서가 바로 Safe Sequence이다.
이 예시에서의 safe sequence는 <T1, T0, T2>이다.
그리고 이러한 safe sequence가 하나라도 존재하면 안전상태이다.
참고로 여태 본 예시에서의 safe sequence는 하나만 존재한다.
직접 다른 순서로 시도해보면서 계산하면 금방 감을 잡을 수 있을 것이다.
Resource-Allocation-Graph 알고리즘
우리는 이미 자원 할당 그래프에 대해서 알아보았다.
자원 할당 그래프 알고리즘은 그 그래프를 이용한 알고리즘이다.
단, 모든 자원이 하나의 인스턴스를 들고 있다는 가정 하에만 작동한다.
실용성이 낮으니 아래의 그림을 보면서 이해하고 넘어가자.
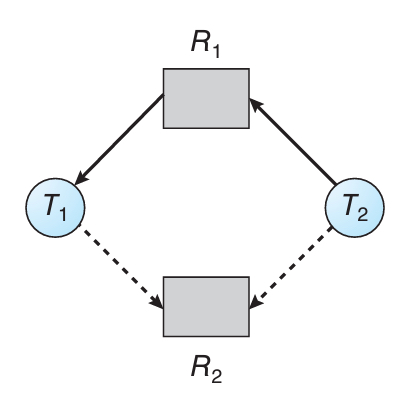
- R→T는 해당 자원을 해당 쓰레드가 가지고 있다는 뜻이다.
- T→R은 해당 쓰레드가 해당 자원을 요청했다는 뜻이다.
- 화살표가 점선이면 "claim edge"라 불리는 새로운 간선이다.
요청과 할당은 같지만, 현재가 아닌 미래에 발생할 수 있는 요청이라는 뜻이다.
이제 이 알고리즘은 그래프를 보고 어떻게 안전상태를 보장하는 지 보자.
1. 임의의 점선 하나의 화살표 방향을 반대로 돌린다.
2. 그 상태에서 사이클이 존재한다면 위험 상태로 인지한다.
위의 예시에서는 T2→R2 간선을 돌렸을 때 사이클이 발생한다.
그리고 사이클이 발생했으면 데드락이 발생할 "가능성"이 있음으로 안전상태가 아니다.
참고로 이 알고리즘의 시간복잡도는 이다. (N은 쓰레드의 개수)
Banker's (은행원) 알고리즘
앞서 말했듯이, 자원 할당 그래프 알고리즘은 실용성이 떨어진다.
그래서 여러 타입의 자원들이 여러개의 인스턴스를 가지는 시스템에서의 알고리즘이 필요하다.
은행원 알고리즘이 잘 알려진 알고리즘 중 하나이다.
💬 실제 뱅킹 시스템에서 쓰일 법한 알고리즘이라 이름이 그렇게 붙었다고 한다.
이 알고리즘은 NxM 형태이기 때문에 하나씩 살펴보면 굉장히 오래 걸린다.
새로 등장하는 자료구조와 예시를 보고 직접 해보자.
우선 새로 등장하는 자료구조는 4가지가 있는데,
사실 자원 할당 그래프 알고리즘의 2차원 버전이라 생각해도 된다.
N개의 쓰레드와 M개의 자원 타입이 있다고 생각하고 보자.
-
Available
M을 크기로 가지는 1차원 벡터이다.
각 칸에는 해당 자원 타입의 인스턴스가 몇개 할당 가능한지를 나타낸다. -
Max
NxM 2차원 배열이다.
n번째 쓰레드가 m번째 자원의 인스턴스를 최대 몇개로 필요하는지 나타낸다. -
Allocation
NxM 2차원 배열이다.
n번째 쓰레드가 m번째 자원의 인스턴스를 몇개 할당 받았는지 나타낸다. -
Need
NxM 2차원 배열이다.
n번째 쓰레드가 m번째 자원의 인스턴스를 현재 몇개 필요하는지 나타낸다.
사실 이렇게 보면 이해가 힘드니 아래 실제 예시를 보자.
쓰레드는 총 5개가 있고 (T0~T4), 자원 타입은 A, B, C로 총 3가지가 있는 상황이다.
표 내의 {}는 각 A, B, C 자원에 대한 인스턴스 개수이다.
| 쓰레드 | Allocation | Max | Need | Available |
|---|---|---|---|---|
| T0 | {0, 1, 0} | {7, 5, 3} | {7, 4, 3} | {3, 3, 2} |
| T1 | {2, 0, 0} | {3, 2, 2} | {1, 2, 2} | - |
| T2 | {3, 0, 2} | {9, 0, 2} | {6, 0, 0} | - |
| T3 | {2, 1, 1} | {2, 2, 2} | {0, 1, 1} | - |
| T4 | {0, 0, 2} | {4, 3, 3} | {4, 3, 1} | - |
자원 할당 그래프 알고리즘에서 했던 것과 똑같이 safe sequence를 찾으면 된다.
이 예시에서의 safe sequence는 <T1, T3, T4, T2, T0>이다.
5개 쓰레드 전부 다 해보면 글이 너무 길어지니 T1에 대해서만 해보자.
Allocation인 {2, 0, 0}이 Max인 {3, 2, 2}가 되려면 각 자원이 몇개씩 필요할까?
{3-2, 2-0, 2-0}인 {1, 2, 2}가 필요함을 알 수 있다.
그런데 이 필요로 하는 배열이 이미 Need에 있다!
다시 돌아와서 T1은 최대치를 달성했음으로 자원을 모두 사용하고 돌려놓는다.
그러면 Available의 상태는 {5, 3, 2}가 될 것이다.
(T1의 할당{2, 0, 0}에서 시스템 자원{3, 3, 2}을 더하기만 하면 되는 단순한 연산이다)
이 알고리즘은 강력한 대신, 효율은 조금 떨어진다.
의 시간복잡도를 가진다. (N은 쓰레드 개수, M은 자원의 종류)
6. 탐지와 회복
만약 시스템이 예방이나 회피 방법을 체택하지 않았다면, 데드락이 발생할 여지가 생긴다.
대신, 시스템은 2가지 알고리즘을 통해 데드락을 회복해야 할 것이다.
- 데드락이 발생했는지 확인하는 알고리즘
- 회복하는 알고리즘
이번에도 마찬가지로 인스턴스가 하나인 경우와 여러개인 경우로 나눠서 살펴볼 것이다.
💡 At this point, however, we note that a detection-and-recovery scheme requires overhead that includes not only the run-time costs of maintaining the necessary information and executing the detection algorithm but also the potential losses inherit in recovering from a deadlock.
하지만 이 탐지와 회복 방식은 런타임에서 정보를 유지하고 데드락을 탐지하는 알고리즘에 대한 오버헤드가 클 뿐만 아니라, 데드락에서 회복하는 과정에서 생기는 손실도 존재한다.
결국 실용성, 손실, 연산 시간 등으로 인해 OS가 데드락을 대처하지 않는 것이다.
탐지
싱글 인스턴스의 경우에는 마찬가지로 자원 할당 그래프의 일종으로 확인할 수 있다.
(회피 방법에서도 비슷한 그래프를 사용해왔다)
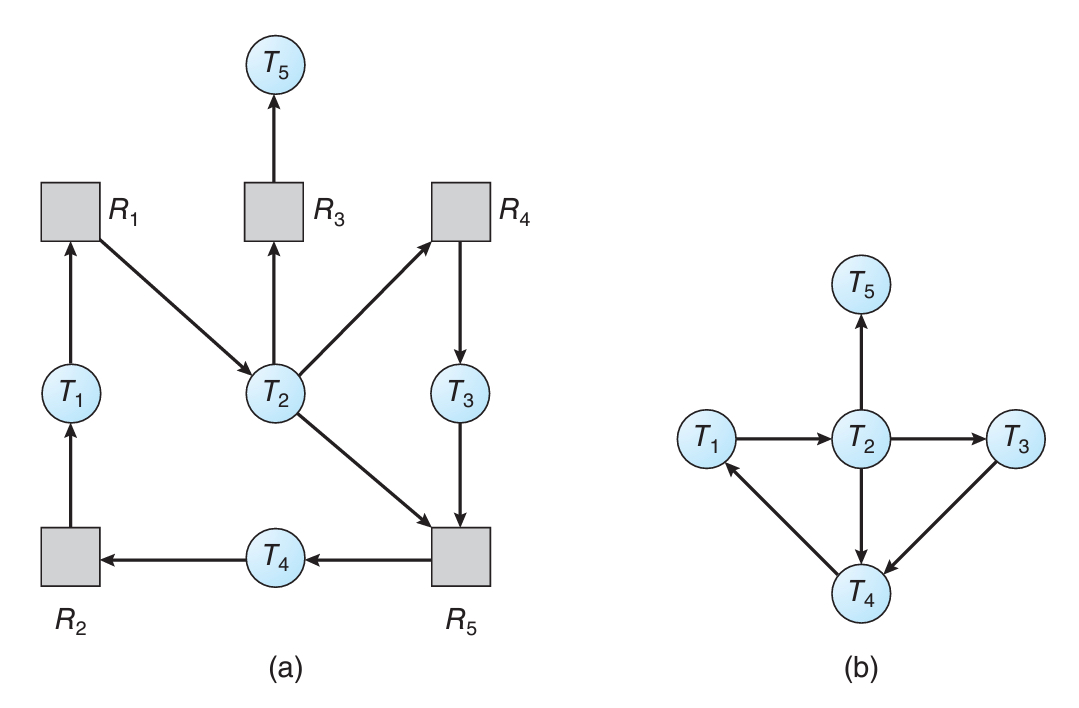
(a)가 우리가 알고 있는 자원 할당 그래프이고,
이 그래프에서 자원을 전부 제거한 버전이 (b)인 wait-for 그래프이다.
wait-for 그래프는 자원의 타입과 무관하게 쓰레드가 어떤 쓰레드를 기다리는지만 나타내는 그래프이다.
이 그래프에서 사이클이 발생했다면, 데드락이 존재할 "가능성"이 생기는 것이고,
사이클이 없다면 데드락은 절대로 발생할 수 없다.
시스템은 모든 쓰레드의 자원 요청을 간선으로 가지고 있어야 하며,
주기적으로 알고리즘을 호출하여 사이클이 있는지 확인해야 한다.
싱글 인스턴스에서 사이클 확인은 시간복잡도가 이다. (N은 간선의 개수)
멀티 인스턴스의 경우에는 Banker's 알고리즘과 자료구조가 유사하다.
일단 어떤점이 달라졌는지 아래 표를 보고 확인해보자.
| 쓰레드 | 할당 | 요청 | 시스템 자원 |
|---|---|---|---|
| T0 | {0, 1, 0} | {0, 0, 0} | {0, 0, 0} |
| T1 | {2, 0, 0} | {2, 0, 2} | - |
| T2 | {3, 0, 3} | {0, 0, 0} | - |
| T3 | {2, 1, 1} | {1, 0, 0} | - |
| T4 | {0, 0, 2} | {0, 0, 2} | - |
우선 "최대 필요"라는 개념이 필요 없어졌음을 알 수 있다.
최대치라는 개념 자체가 안전상태를 고집하기 위함이었기 때문에,
데드락을 허용하는 알고리즘에서는 더이상 필요가 없는 것이다.
대신, safe sequence는 찾을 필요가 있다.
해당 순서대로 자원을 할당하면 데드락 상태에 진입하지 않는다는 뜻이니까.
위 예시에서는 <T0, T2, T3, T1, T4> 순서로는 데드락이 발생하지 않는다.
하지만, T2가 3번째 자원 타입에 대해서 하나의 인스턴스를 더 요청한다고 하자.
그러면 T2의 요청 배열이 {0, 0, 1}로 변할 것이고,
이 상태에서는 safe sequence가 존재하지 않으니, 데드락이 발생했다고 판단한다.
탐지 알고리즘의 사용
그렇다면 탐지 알고리즘을 언제 호출해야 할까?
다음 2가지 요소에 따라서 결정이 달라질 수 있다.
- 데드락이 얼마나 자주 발생할 것인지
- 데드락 발생 시에 몇개의 쓰레드가 영향을 받을 것인지
당연히 데드락이 많이 발생할수록 탐지를 자주해줘야 할 것이고,
영향 받는 쓰레드의 개수가 많아지게 않게 막아야 할 것이다.
그런데 문제는 데드락이 언제 발생할지 전혀 알수가 없다는 것이다.
데드락을 냅두게 되면 쓰레드가 해당 사이클에 참여하면서 규모가 커질 수 있다.
그렇다고 매 요청마다 탐지하기에는 오버헤드가 너무 커서 CPU가 낭비된다.
하지만 데드락을 자주 확인 안하기에는 앞서 얘기한 것처럼 사이클이 커질 수 있다.
그래서 탐지 알고리즘 호출을 위한 기준을 마련을 해야한다.
예를 들어, CPU 사용량이 40% 미만으로 간다던가, 매 시간마다 호출하는 등.
회복
탐지와 회복 방식을 체택했다고 하고, 탐지 알고리즘도 잘 작동한다고 치자.
그러면 데드락으로 부터 탈출하는 방법은 무엇이 있을까?
크게 2가지로 볼 수 있다.
1. 데드락을 결정적으로 발생시킨 프로세스/쓰레드를 종료한다.
2. 자원을 선점 가능하게 하여 기존 쓰레드의 자원을 뺐는다.
프로세스 종료
프로세스를 종료하는 것으로 결정했다고 하면, 무엇을 종료해야 할까?
애초에 어떤 프로세스를 종료할 것인가보다 몇개를 종료할지가 우선이다.
- 모든 프로세스를 종료한다
- 데드락을 한번에 해결할 수 있는 확실한 방법이다
- 대신 프로세스가 종료됨으로서 생기는 손실이 막대하다
- 데드락이 풀릴때까지 하나씩 종료한다
- 프로세스를 하나 종료하고 탐지 알고리즘을 돌린다
- 데드락이 해제될때까지 반복한다
- 손실이 적은 대신 생갹해야 할 점이 하나 더 생긴다
2번 방법을 체택했다면, 이제 어떤 프로세스를 죽일지 결정해야 한다.
💡 This determination is a policy decision, similar to CPU-scheduling decisions.
이 선택은 각자의 정책에 맞게 고르는 것이다. (CPU 스케줄링 처럼)
그대신 종료한 프로세스 선택에 대한 가이드라인은 다음과 같다.
- 스케줄링의 우선순위
- 여태까지 일한 시간과 앞으로 일해야 할 시간
- 사용한 자원의 종류와 양
- 완료하기 위해 더 필요한 자원의 양
- 종료되어야 할 프로세스의 개수
자원 선점
만약 프로세스를 종료하는 대신 자원을 선점하는 것으로 결정했다면?
아래 3가지 문제점을 잘 해결해야 할 것이다.
-
희생 프로세스 결정
- 프로세스 종료 방법처럼 희생자 결정 정책이 필요하다
- 단순히 우선순위로 한다면 하나의 프로세스가 계속해서 희생자가 되는 문제가 있다
-
롤백
- 자원을 뺐긴 프로세스에 대한 처리도 고민해야 한다
- 해당 프로세스의 상태를 특점 지점이나 처음으로 롤백해야 할 것이다
-
기아 현상
- 자원을 뺐는 과정에서 프로세스가 굶는 현상을 막아야 한다
- 어떤 기준을 세우더라도 모든 프로세스가 자원을 획득할 수 있어야 한다
🎯 마치며
OS에서는 CPU가 너무 소중한 자원이기 때문에 데드락을 무시하는 것 같다.
그래도 개념을 확실히 잡아서 데이터베이스시스템을 공부하면 좋을 듯 하다.
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』
