📖 본 글은 모든 내용을 "Operating System Concepts Ed.10"에서 인용합니다.
👋 메인 메모리에 대해
💡 Memory consists of a large array of bytes, each with its own address. The CPU fetches instructions from memory according to the value of the program counter.
메모리는 하나의 거대한 바이트 배열로 이루어져있고, 각 바이트는 주소를 가지고 있다.
CPU는 PC의 값을 참고하여 해당 주소에서 명령어를 읽는다.
메모리 및 하드웨어
1장에서 배운대로, CPU는 직접 접근 가능한 저장장치로부터 명령어를 읽어온다.
그러나 하드디스크와 같은 2차 저장장치는 CPU가 읽을 수 없기 때문에,
프로그램이 실행되려면 우선 메모리로 올라와야 한다. (올라오면 프로세스가 된다)
CPU 레지스터는 보통 읽는데 한번의 CPU 사이클로 충분한 경우가 많다.
그러나 메모리는 여러 사이클이 필요하기 때문에, 그 과정에서 CPU는 멈춰야 한다.
그래서 Cache라는 CPU와 메모리 사이의 새로운 저장장치를 만들게 되었다.
이처럼 속도 측면에서 많은 보완을 해왔지만, 정확성 측면도 고민을 해봐야한다.
특정 프로세스에 접근하려고 할때, 다른 프로세스로 침범하는 일을 없애야 한다.
이를 위한 방법은 몇가지가 있지만, 가장 단순한 방법을 먼저 보려고 한다.
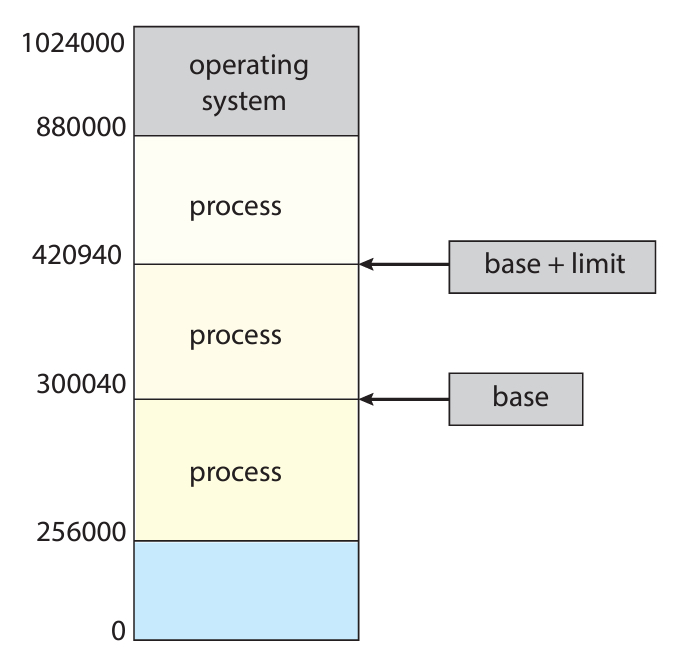
우선 모든 프로세스가 독립적인 주소를 가지고 있어야 한다. (당연하다)
2개의 레지스터를 사용해서 간단하게 구현할 수는 있다.
위 그림처럼 base 레지스터가 프로세스의 가장 낮은 주소를 가르킨다.
그리고 limit 레지스터가 프로세스의 전체 크기를 나타낸다.
이렇게 하면 base + limit 값이 곧 프로세스의 가장 높은 주소를 의미한다.
단, 이 2개의 레지스터는 반드시 OS만 가질 수 있도록 해야한다.
(다른 모든 하드웨어 관련 자원을 접근할 때도 마찬가지이다)
그러기 위해서는 이전에 배운 커널모드로 실행될 것이다.
다시 돌아와서, base와 limit 레지스터가 있다고 한다면,
아래와 같은 그림으로 메모리 내의 프로세스에 안전하게 접근할 수 있다.
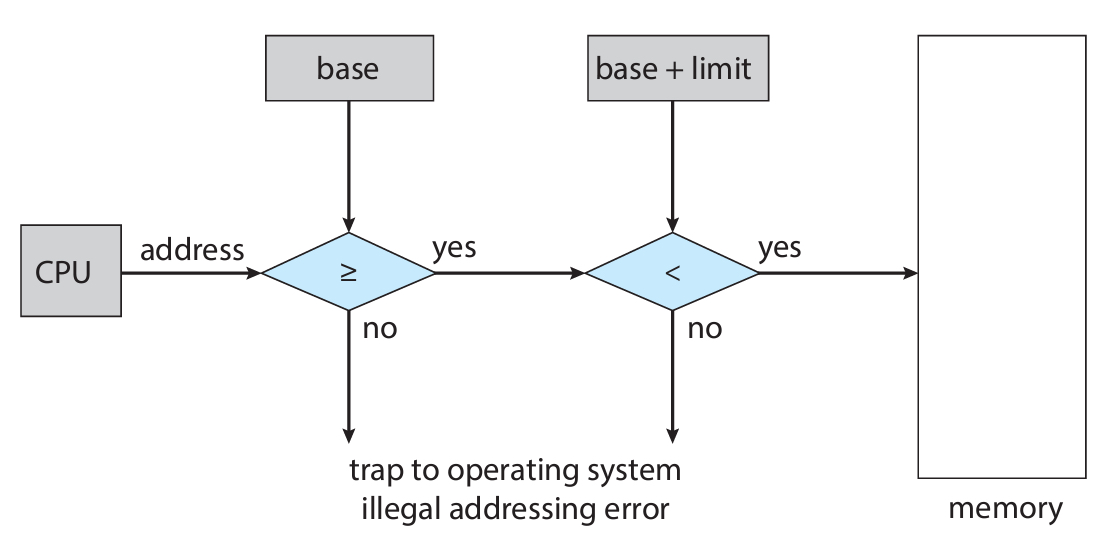
만약 base보다 작거나 base+limit보다 큰 주소로 접근하려고 하면,
OS는 이를 치명적인 오류로 판단하고 trap 처리를 해버린다.
💬 트랩은 소프트웨어 차원의 인터럽트이다. (익셉션이라고도 한다)
대표적으로 시스템콜과 잘못된 메모리 접근이 트랩으로 알려져있다.
주소 바인딩
프로그램이 프로세스가 되기 전, 즉 아직 하드디스크에 있을 때에는 본인의 주소를 모른다.
그래서 OS는 프로그램에게 적합한 주소를 찾아서 할당을 해줘야 한다.
그런데 문제는 프로그램 내의 코드는 대부분 symbolic하다.
예를 들어, int count = 0; 이런 식으로 되어있기 때문에 일일이 매핑을 해줘야 한다.
그러면 저 count라는 변수는 어느 시점에 어디로 매핑이 되어야 할까?
우선 "어디"에 대한 건 컴파일러가 처리해야 한다.
컴파일러는 다양하게 있고, 최적화도 하기 때문에 해당 컴파일러를 공부해야 알 수 있다.
그래도 미리 알 수 있는거는, 컴파일러는 모든 변수에 상대적인 주소를 주게 된다.
"count라는 변수는 시작주소로부터 14byte 위에 4byte를 차지한다" 라는 식으로.
이제 여기서부터 OS가 해야하는 역할이다.
저 상대주소가 실제 메모리에 올라갔을 때의 절대 주소를 할당하는 것과,
"언제" 최종적으로 절대 주소를 가지게 되는지를 결정해야 한다.
상대 주소를 절대 주소로 바꾸는 것은 나중에 보고, 우선 "언제"부터 알아보자.
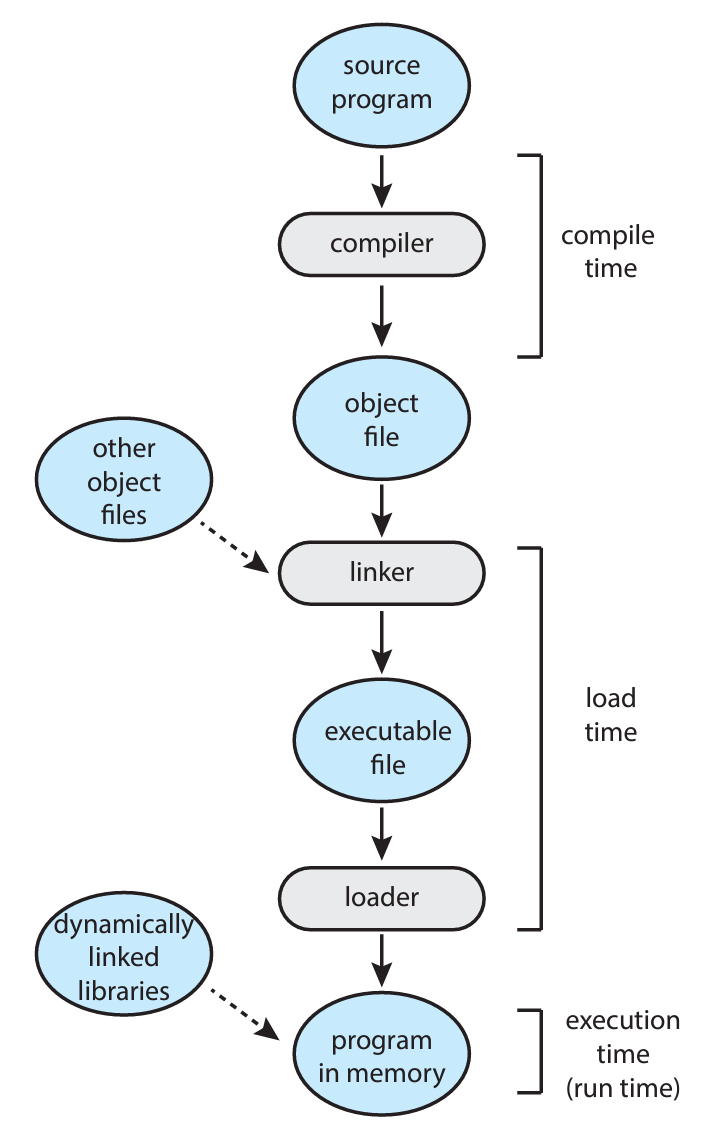
이전에 한번 봤던 그림인데, 이번에는 3가지 섹션으로 나눴다.
각 세션마다 어떤 식으로 매핑이 되는지 알아보도록 하자.
-
컴파일 타임: 컴파일이 되는 시점에서 실제 메모리 주소를 알 수 있다면, 굳이 OS가 주소를 할당하지 않고 컴파일러가 전부 할당해주면 된다.
-
로드 타임: 컴파일 완료된 프로그램이 올라가는 시점에서 메모리 주소를 알게 된다면, OS가 모든 상대주소에 특정 값을 더해줘서 끌어올려주기만 하면 된다.
-
런 타임: 실행 도중에 메모리 주소를 알 수 있게 된다면, 특별한 하드웨어의 도움이 필요하다. 그런데 대부분의 OS는 이 방식으로 작동한다! (바로 아래에서 볼 내용이다)
논리 주소 vs 물리 주소
💡 An address generated by the CPU is commonly referred to as logical address, whereas an address seen by the memory unit is commonly referred to as a physical address.
CPU로 부터 생성된 주소는 논리주소, 실제 메모리에 올라가는 주소가 물리주소이다.
위에서 계속 사용한 상대주소가 논리주소이고, 절대주소가 물리주소인 셈이다.
그리고 그 2개 간의 주소 매핑이 런타임에 주로 이뤄진다고 했다.
그 과정에서 특별한 하드웨어가 필요하다고 했는데, 그게 Memory-Management Unit (MMU)이다.
💡 In this case, we usually refer to the logical address as a virtual address.
이 경우에는 논리주소를 가상주소라고 부르기도 한다.
다시 돌아와서, 우리는 위에서 base 레지스터가 필요하다고 했는데,
MMU 내부적으로는 relocation 레지스터가 해당 일을 대신한다.
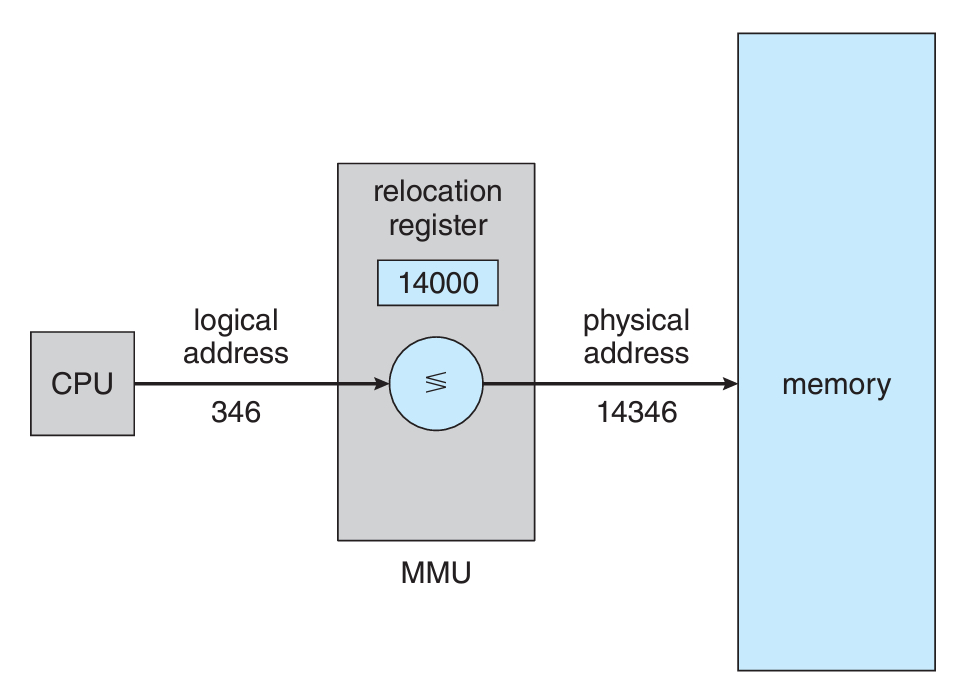
위의 그림처럼 컴파일이 완료된 논리주소를 가지는 프로그램이,
MMU를 통해 물리주소로 매핑이 되어 메모리에 올라가서 프로세스가 되는 것이다.
동적 로딩
동적 로딩은 제한된 메모리 공간을 효율적으로 쓰기 위한 방법이다.
💡 With dynamic loading, a routine is not loaded until it is called. All routines are kept on disk in a relocatable load format.
동적 로딩은 특정한 루틴이 사용되는 시점에서 호출하는 것을 얘기한다.
이를 위해 모든 루틴은 재배치 가능한 형태로 디스크에 저장되어있어야 한다.
💬 루틴은 프로그램의 실행 부분이라고 생각하면 된다. (코드 블록)
재배치 가능한 형태는 논리주소가 할당 완료된 상태이다.
이렇게 하면 당장 필요한 코드블록만 메모리에 올려두고 실행할 수 있다.
특히 프로그램의 사이즈가 큰 경우에 효과적으로 사용될 수 있다.
단, 이 방법은 OS가 도움만 줄 뿐, 개발자가 직접 디자인해야 하는 부분이다.
동적 링킹 & 공유 라이브러리
동적 링킹은 동적 로딩과 유사하지만, OS가 전적으로 지원하는 기능이다.
💡 Here, though, linking, rather than loading, is postponed until execution time.
동적 링킹은 말 그대로 "링크"과정이 런타임까지 미뤄지는 것이다.
대표적으로 C 라이브러리가 해당한다.
C로 구성된 프로그램이 여러개가 메모리에 올라간다고 해서,
모든 프로그램이 C 라이브러리를 각각 가지고 있을 필요가 있을까?
딱 봐도 비효율적이라는 사실을 알 수 있다.
그래서 동적 링킹을 통해 중복된 라이브러리를 하나만 올리는 것이다.
이렇게 하면 각 프로세스가 메모리에서 차지하는 공간이 줄어들고,
공통으로 하나의 라이브러리를 사용하기 때문에 해당 라이브러리가 하나만 올라가도 된다.
그러한 이유로 동적 링킹은 "공유 라이브러리"라고 불리기도 한다.
1. 연속 할당
OS도 당연히 코드를 가지고 있으니 메모리에 올라와야 한다.
💡 The memory is usually divided into two partitions: one for the operating system and one for the user processes. We can place the operating system in either low memory addresses or high memory addresses. This decision depends on many factors, such as the location of the interrupt vector.
메모리는 주로 OS 영역과 유저 프로세스 영역으로 분리된다.
OS 영역은 메모리의 가장 위 또는 아래에 위치하게 되는데,
인터럽트 벡터의 위치와 같은 여러 요소로 인해 결정될 수 있다.
💬 대부분의 OS는 OS 영역을 높은 메모리 주소에 할당한다. (Windows, Linux)
OS는 최대한 많은 유저 프로세스를 메모리에 올리고 싶어하니 적당한 방법을 찾아야 하는데,
예전에 사용된 방식 중 하나가 연속 메모리 할당 방식이다.
이 방식은 모든 프로세스끼리 붙어서 메모리에 올라가는 형태이다.
그런데 메모리에 올라간 프로세스가 일이 끝나면 메모리에서 내려와야 할 것이다.
그렇게 해서 만들어진 공간을 어떻게 사용하고 관리해야 할까?
할당 방식
💡 The operating system keeps a table indicating which parts of memory are available and which are occupied. Initially, all memory is available for user processes and is considered one large block of available memory, a hole.
우선 OS는 메모리의 모든 빈 공간에 대한 정보를 테이블에 저장하고 있어야 한다.
처음에는 모든 메모리 공간이 사용 가능한 상태로 존재한다. (Hole이라 불린다)
실제로 어떤 모습일지 그림을 보면서 공부해보자.
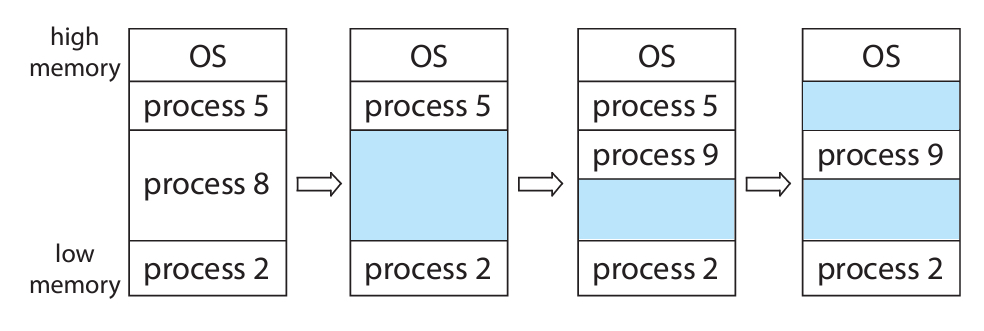
프로세스 2, 5, 8이 메모리에 올라와 있는 상태라고 가정하다.
시간이 지난 후에 프로세스8이 일을 끝내고 메모리에서 내려온다.
여기까지 진행되면 메모리에는 하나의 거대한 hole이 생긴다.
이후에 프로세스9가 실행되어 프로세스5 바로 밑에 붙어서 올라온다.
그리고 나서 프로세스5가 곧바로 일을 끝내고 메모리에서 내려온다.
이로써 메모리에는 2개의 거대한 hole이 생기는 것이다.
여기까지 왔으면 메모리가 어떤 식으로 동작하는지 감이 올 것이다.
그런데 아까 프로세스9가 왜 프로세스2가 아닌 5에 붙어서 올라온 걸까?
이 위치를 결정하는 방법에는 크게 3가지가 있다.
- First fit
- 가장 처음 발견하는 공간에 프로세스를 위치시킨다.
- 매번 바닥에서 스캔해도 되고, 마지막에 스캔이 끝난 시점부터 스캔을 시작해도 된다.
- Best fit
- 프로세스가 올라올 수 있는 공간 중 가장 작은 공간에 배치시킨다.
- 메모리의 전체 공간을 탐색해야 찾을 수 있다.
- Worst fit
- 프로세스가 올라올 수 있는 공간 중 가장 큰 공간에 배치시킨다.
- 마찬가지로 메모리를 전체 탐색해야 찾을 수 있다.
시뮬레이션을 돌려본 결과, worst fit 보다는 앞선 2가지 방식이 좋은 것으로 보인다.
그리고 first fit과 best fit은 공간활용에는 차이가 없지만, first fit이 속도는 빠르다.
단편화
위의 방법들은 모두 외부 단편화를 발생시킬 수 있다.
위 그림의 마지막 상황을 다시 예시로 들어보자면, hole이 총 2개가 있다.
hole 2개의 사이즈가 각각 10과 8이라고 쳤을 때, 새로운 프로세스가 11짜리 크기라면?
그 프로세스는 메모리에 총 18의 공간이 있음에도 들어갈 수 없는 문제가 생긴다.
우리는 프로세스를 자르지 않고 통째로 메모리에 올리기로 했으니까!
💡 External fragmentation exists when there is enough total memory space to satisfy a request but the available spaces are not contiguous: storage is fragmented into a large number of small holes.
외부 단편화는 메모리 공간이 충분함에도 불구하고 연속적이지 않아서 할당해줄 수 없는 것이다.
저장 공간에 무수히 많은 작은 hole들이 생기면서 발생한다.
first fit의 경우의 통계를 살펴보면, N개의 블록을 할당할 때마다 N/2개의 블록이 단편화된다.
결국 전체 공간의 1/3 정도가 사용 불가능한 공간이 되어버리는 것이다.
이러한 상황을 "50-percent rule"이라고 부른다.
외부 단편화는 알아봤는데, 내부 단편화도 있지 않을까?
💡 The general approach to avoiding this problem is to break the physical memory into fixed-sized blocks and allocate memory in units based on block size. With this approach, the memory allocated to a process may be slightly larger than the requested memory. The difference between these two numbers is internal fragmentation - unused memory that is internal to a partition.
외부 단편화를 피하기 위한 대표적 방법이 메모리를 고정된 크기의 단위로 자르는 것이다.
그리고 프로세스가 필요한 공간만큼의 블럭을 할당해주는 방식이다.
그러나 블럭은 고정된 크기이기 때문에 원하는 양보다 많은 블럭이 할당된다.
이렇게 할당된 공간 중에 사용하지 않은 메모리 공간이 내부 단편화이다.
그렇다면 내부 단편화를 만들지 않고 외부 단편화를 해결할 수는 없을까?
Compaction이라는 방법이 하나 존재하기는 한다.
그런데 이 방식은 메모리 상의 모든 프로세스를 다 한쪽으로 밀어버리는 것이라서
한 번 실행했을 때의 overhead가 지나치게 크다는 한계점이 있다.
그러니 다시 외부 단편화를 포기하고 내부 단편화를 수용하는 방식으로 돌아오자.
2. 페이징 (Paging)
작동 방식
💡 The basic method for implementing paging involves breaking physical memory into fixed-sized blocks called frames and breaking logical memory into blocks of the same size called pages.
물리적 메모리를 고정 크기의 여러 블럭으로 나누고 frame이라고 한다.
논리적 메모리도 위와 같은 크기로 나누고 page라고 한다.
즉, 우리가 알고 있는 하드웨어 메모리는 frame이라는 단위로 쪼개지게 되고,
프로세스도 특정 기준에 따라 frame과 같은 크기의 page로 나뉜다는 말이다.
우선 이를 구현하기 위해 모든 논리주소는 page number (p)와 page offset (d)로 구성된다.
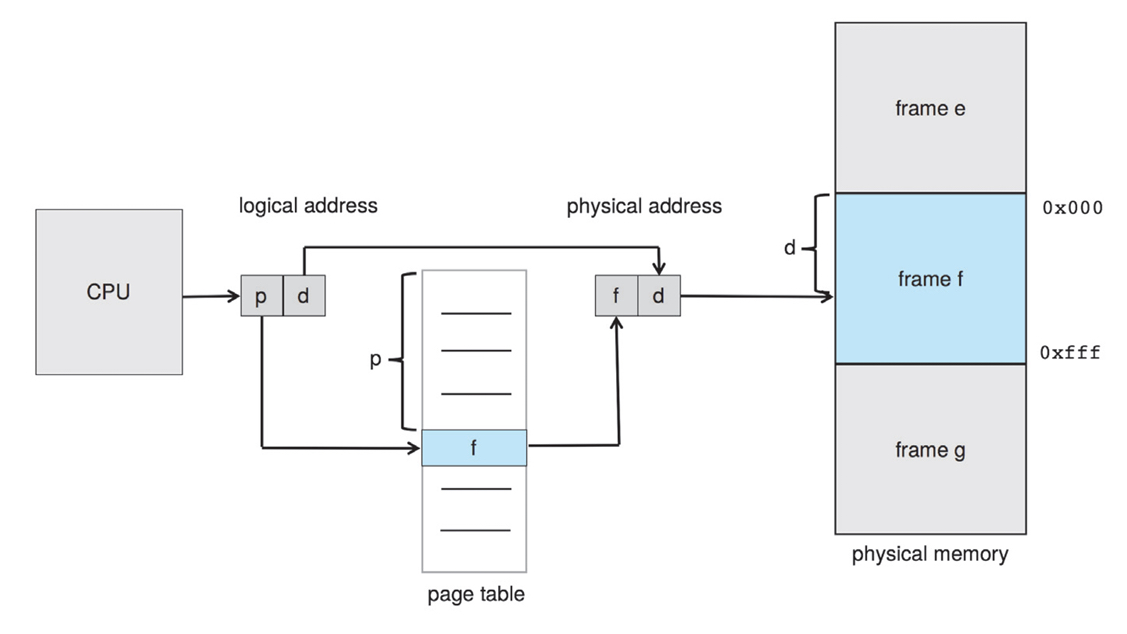
위의 그림이 사실상 page, frame의 관계와 page table에 대한 모든걸 보여준다.
💡 The page number is used as an index into a per-process page table.
페이지 넘버는 각 프로세스가 가지는 페이지 테이블의 인덱스이다.
페이지 테이블의 해당 인덱스로 가면 프레임의 번호가 나온다.
그리고 프레임 번호에 프레임 사이즈를 곱하면 프레임 시작 주소가 나온다.
거기에 오프셋을 더하면 실제 메모리 상의 주소가 나오는 방식이다.
좀더 구체적인 예시를 한번 보자.
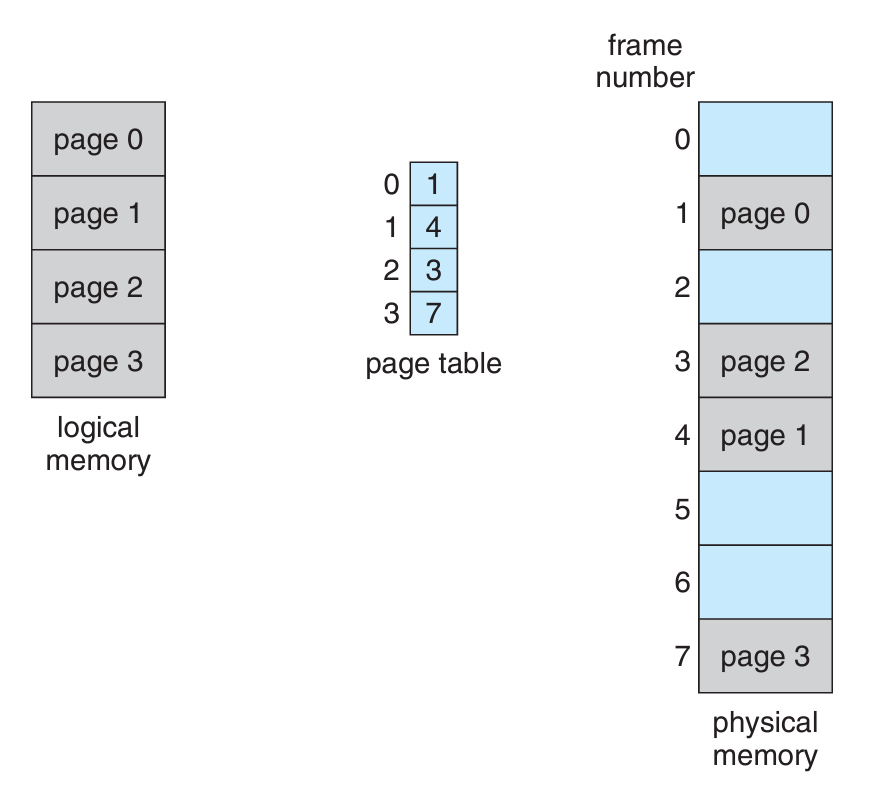
위 예시는 각 페이지의 크기가 4바이트, 프레임의 개수가 8개인 메모리 구조이다.
(물리 주소의 총 크기는 byte이다.)
이제 논리주소가 어떻게 쪼개지는지 보자.
모든 논리주소는 앞서 얘기했듯이 페이지 번호와 오프셋으로 나눠진다고 했다.
이 페이지 번호와 오프셋의 크기는 어떻게 결정하는 것일까?
2개의 정보가 필요하다: 논리주소의 크기 과 페이지의 크기
위 예시에서는 페이지의 크기(= 프레임 크기)가 4byte라고 했다.
그리고 프로세스가 4개의 페이지로 구성되고 있다.
그렇다면 논리주소의 크기는 byte일 것이다.
(프로세스 전체의 크기 = 논리주소의 크기)
(논리주소의 크기 = 페이지 개수 * 페이지 하나의 크기)
결과적으로, n은 2가 될 것이고 ()
m의 크기는 4가 될 것이다. ()
다시 논리주소를 어떻게 나타내는지로 돌아오면 다음과 같다.
페이지 번호 = m-n / 오프셋 = n
논리주소를 표현하기 위해서는 m개의 비트가 필요하다고 했다.
그러면 위의 예시에서는 2비트()의 페이지 주소와 2비트()의 오프셋이 생긴다.
이제 이 논리주소를 가지고 물리주소로 변환되는 과정을 한번만 더 살펴보자.
page1의 2번째 byte값을 찾는다고 가정하자. (offset = 1)
우선 페이지 테이블의 1번 인덱스로 간다.
그 칸에는 4라는 프레임 번호가 담겨져 있다.
위의 공식에 따라서 계산하면, 이 나온다.
그러면 메모리의 17이라는 주소에 page1의 2번째 바이트가 저장되어있다는 뜻이다!
페이지 작동 원리는 잘 알아봤으니, 위에서 소개만 했던 내부 단편화를 다시보자.
페이징 기법은 굉장히 강력한 툴이지만, 내부 단편화라는 결점을 가지고 있다.
내부단편화가 일어나는 예시를 먼저 보자.
페이지 크기가 2,048bytes이고 프로세스 크기가 72,766byte라고 치자.
그러면 총 35개의 프레임과 별도의 1,086byte가 필요함을 알 수 있다.
그런데 저 별도의 메모리도 필요하긴 하니까 1개의 프레임을 더 할당받아야 한다.
그러면 그 36번째 프레임에는 962bytes가 놀게 된다.
그래도 위에서 봤던 외부단편화는 총 메모리의 1/3을 사용하지 못했지만,
내부 단편화는 10%도 되지 않는 메모리 손해가 발생하는 것을 보면 훨씬 낫다.
마지막으로, 프레임에 대해서 조금만 더 알아보고 가자.
결국 프로그래머 입장에서는 메모리는 본인의 프로그램 하나가 통째로 올라간 것으로 보인다
그러나 실제로는 해당 프로그램이 쪼개져서 분산되어 저장되어 있게 된다.
이 모든 역할을 결국 OS가 하기 때문에 프레임에 대한 정보를 잘 저장해야 한다.
그래서 OS는 frame table이라 하는 프레임 관련 정보를 가지는 테이블을 가진다.
어떤 프레임이 사용 가능한지, 아니라면 어떤 페이지가 들어가 있는지 저장해야 한다.
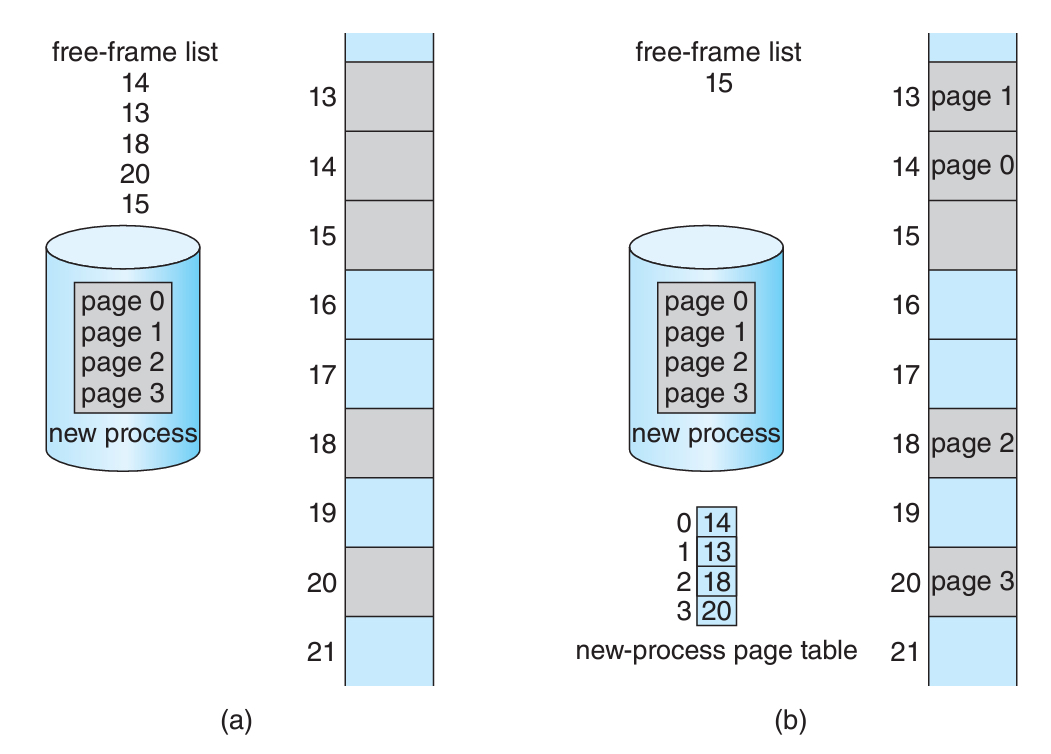
위 그림은 새로운 프로세스가 들어오기 전 (a)와,
4개의 프레임을 할당받는 프로세스가 들어온 직후 (b)의 예시이다.
결론으로, 프레임 테이블은 OS가 전체 메모리를 관리하기 위해 하나를 들고 있는 것이고,
페이지 테이블은 각 프로세스가 본인의 페이지를 찾기 위해 프로세스당 하나씩 존재하는 것이다!
TLB
이쯤에서 궁금한 점이 하나 생기는게, 페이지 테이블은 어디에 저장할까?
원래는 메모리에 저장을 해두고, page-table base register (PTBR)이라는
특수한 레지스터를 고정시켜두고, 해당 레지스터가 가리키는 곳에서 페이지 테이블을 찾았다.
그런데 이 방법이 과연 좋을까 생각해보면 그렇지 않다.
우선 프로세스가 본인의 자원을 찾기 위해서 페이지 번호를 들고 페이지 테이블에 접근한다.
이렇게 접근해서 프레임 번호를 가져오는 것까지가 메모리를 한 번 접근하는 것이다.
이제 실제 물리주소를 계산해서 해당 주소로 가게 되는데, 여기서 한 번 더 메모리로 간다.
메모리에 있는 데이터를 가져오기 위해 메모리를 2번이나 가는 불상사가 생긴다!
💡 The standard solution to this problem is to use a special, small, fast-lookup hardware cache called a translation look-aside buffer (TLB).
이 문제를 해결하기 위해 특별한 하드웨어 캐시인 TLB가 등장하게 되었다.
TLB는 key(tag)와 value 쌍으로 item들을 가지고 있다.
특정한 item을 찾으려 하면, TLB의 모든 key와 비교하게 되고, 찾으면 value를 리턴한다.
TLB의 특징으로는 굉장히 빠른 속도인데, 이는 파이프라이닝 덕분이다.
💬 파이프라이닝은 컴퓨터 아키텍처를 공부하면 된다.
파이프라이닝에 포함될 수 있는 명령이기 때문에 페널티가 존재하지 않는다.
그러면 구체적으로 어떻게 동작하게 되는가?
우선 TLB는 결국 캐시이기 때문에 모든 페이지 테이블을 가져올 수 없다.
만약 찾으려는 페이지 번호가 TLB에 있다면, 문제 없이 물리주소를 가져오면 된다.
그런데 TLB가 갖고 있지 않은 경우에는 TLB miss가 발생한다.
miss가 발생했으면 어쩔 수 없이 기존의 방식대로 메모리에서 페이지 정보를 가져와야 한다.
대신, 앞으로 다시 찾게 될 수 있으므로 TLB에 업데이트를 해준다.
만약 이 과정에서 TLB에 빈 공간이 없다면 어떻게 해야할까?
이때에는 LRU, Round-Robin, Random 등의 방식으로 교체를 해주면 된다.
(기존에 있던 페이지 중 가장 필요 없는 것을 빼야 한다)
단, 중요한 페이지도 있을 수가 있다. (ex. 커널 코드)
이러한 페이지는 "wired down"이라 해서 TLB에서 제외될 수 없게 고정할 수도 있다!
이 외에도 Address-Space Identifier (ASIDs)를 사용하는 TLB도 있고,
사실 상 대부분의 컴퓨터 시스템은 multi-level TLB를 사용한다.
심지어 TLB는 하드웨어에 가깝고 OS가 하는일이 아니다.
그럼에도 OS 디자이너들은 TLB에 대한 확실한 이해가 있어야 메모리를 관리하기 유리하다.
마지막으로, TLB의 특성 중 하나만 살펴보고 넘어가려고 한다.
찾고자 하는 페이지를 TLB에서 한번에 찾는 비율을 hit ratio라고 한다.
예를 들어, 100번을 접근해서 80번을 한번에 찾았다면 hit ratio는 80%인 것이다.
일단 이런게 있다는 것을 알고 가고, 자세한건 가상메모리에서 더 공부해보자.
보호 (Protection)
이제 페이징 기법의 걱정거리를 거의 다 처리한 것 같지만, 한가지가 더 남았다.
각 페이지에 대한 권한 (read only 또는 write and read)은 어떻게 해야할까?
이들은 사실 bit masking을 통해서 어렵지 않게 구현할 수 있다.
각 페이지마다 권한관련 비트를 두고 확인하면 문제 없다.
이보다 더 문제되는 것은 바로 페이지 테이블의 크기이다.
우선 아래의 예시 그림부터 보고 설명해보자.
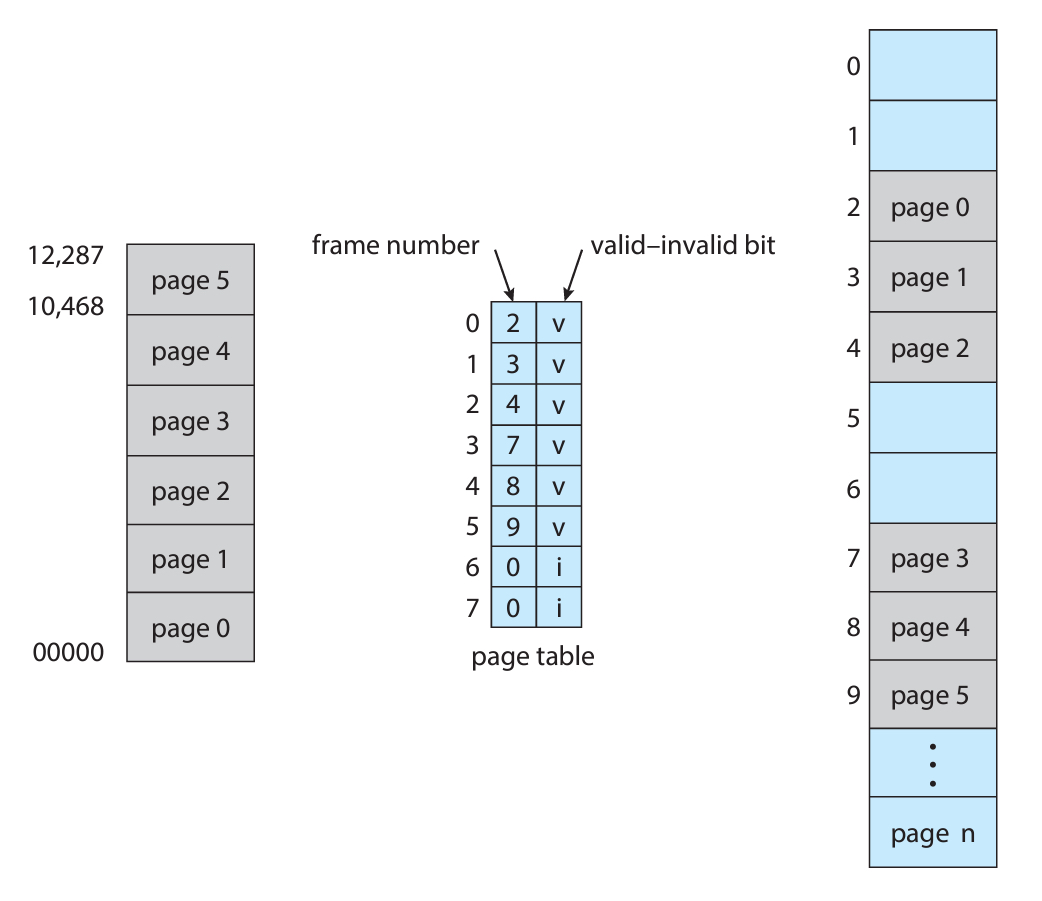
위처럼 페이지의 개수가 6개인 프로세스가 있다고 해보자.
6개의 경우의 수를 나타내기 위한 비트의 수는 몇개인가?
총 3개의 비트가 필요한 것이다. ()
그러면 페이지 테이블 내의 페이지 개수는 자연스럽게 8개가 될 수밖에 없다!
하지만 프로세스는 6, 7번 페이지는 영원히 쓸 일이 없다.
그래서 페이지 번호 옆에 "valid-invalid bit"을 추가해서 사용 여부를 체크한다.
invalid한 페이지에 접근하면 OS는 trap 처리해버리면 된다.
그러면 절대 안쓰는 페이지에 대한 안전성은 확보한 셈이다.
그런데 여기서 문제가 하나 또 있는데, 바로 5번 페이지이다.
5번 페이지는 valid한 페이지이지만, 그 안에서 사용하지 않는 주소가 있다.
프로세스가 10,467까지 쓰기 때문에, 10,468~12,287까지는 접근하면 안되는 주소다.
그렇다고 한 페이지 내에 또다른 내부 페이지 테이블을 만들기에는 메모리가 아깝다.
그래서 몇 시스템은 page-table length register (PTLR)을 사용한다.
모든 논리 주소에 해당 레지스터와 연산하여 valid한 범위인지 확인하는 것이다.
공유 페이지 (Shared Pages)
마지막으로 페이징 기법의 강점 중 하나인 공유 페이지에 대해 알아보자.
외부 단편화를 막을 수 있다는 점부터 이미 강력하지만, 공유 페이지도 굉장히 좋은 기능이다.
대표적으로 C 라이브러리는 많은 프로세스가 공용으로 사용하기 때문에,
모든 프로세스가 해당 코드를 다 본인 메모리에 들고 있기에는 아깝다는 생각이 든다.
💡 If the code is reentrant code, however, it can be shared.
재진입성 코드는 공유될 수 있다.
재진입성 코드는 기본적으로 런타임에 고정되어 있는 코드이다.
그리고 여러 프로세스가 동시에 접근하여 사용해도 된다. (수정이 안되니까)
우리가 이미 알아본 공유 라이브러리가 생각이 나는데, 어떤 관계일까?
그 공유 라이브러리가 공유 페이지로 구현이 된다!
심지어 어떤 OS는 공유 메모리를 공유 페이지로 구현하기도 한다.
3. 페이지 테이블 구조
요즘의 컴퓨터들은 주소공간을 에서 까지 사용한다.
그 중 32bit 주소체계 ()를 가지고 페이지의 크기를 4Kb로 나눈다고 치자.
그러면 페이지의 개수는 개가 된다. (1Kb가 이다)
결국 100만개 이상의 페이지 엔트리를 가지고 있어야 하는데,
문제는 한 페이지가 4byte씩 차지할 것이고, 총 인 4Mb 공간이 필요하다.
그런데 페이지 크기가 4Kb면서 페이지 테이블은 막상 4Mb면 말이 안된다.
그래서 페이지 테이블을 저장할 방법들에 대해 고민할 필요가 생겼다.
a) 계층적 페이징
💡 One way is to use a two-level paging algorithm, in which the page table itself is also paged.
하나의 방법은 페이지 테이블을 페이징을 해서 2계층으로 저장하는 것이다.
다시 위의 예시처럼 4Kb의 페이지 크기와 32bit 주소체계를 사용한다고 하자.
그러면 논리주소는 아래와 같이 생길 것이다.
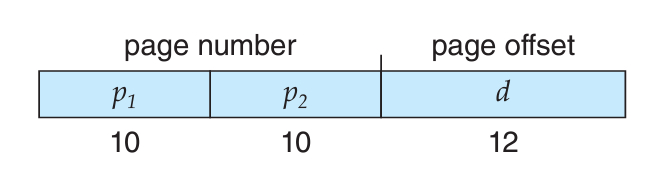
우선 offset은 페이지 크기의 영향을 받아 12로 되는 것은 그대로이다.
대신 페이지 번호에 20bit가 남게 되는데, 이를 2개로 쪼개는 것이다.
그래서 10bit의 p1의 페이지 테이블의 페이지 번호가 되고, p2가 페이지 테이블 내의 offset이 된다.
좀더 구체적으로 아래 그림을 보고 천천히 따라가보자.
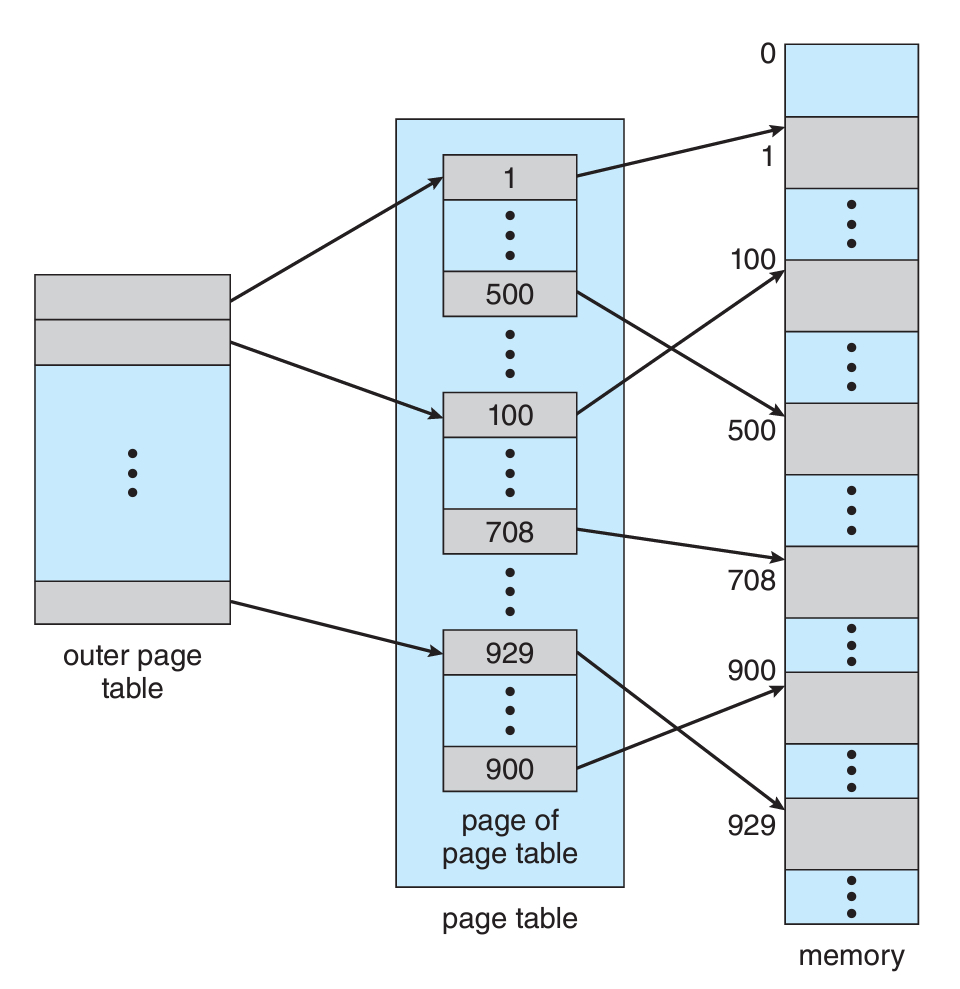
p1은 outer page의 페이지 번호이다. (outer page가 root라고 보면된다)
그러면 해당 번호에 적힌 주소를 따라가면 그때 page table 내의 특정 주소로 가게 되는데,
그 지점에서 p2 offset을 더한 곳으로 가면 그제서야 메모리 상의 주소가 나온다.
최종적으로 해당 메모리 주소 + offset을 해서 값의 위치를 찾을 수 있는 것이다.
하지만 최근들어 64bit 주소체계가 자주 쓰이는데, 여기서는 사용 불가능하다.
32bit에서 64bit는 비트 수로만 보면 2배가 늘어난거지만,
실제로는 위 예시에서의 4Mb 짜리 페이지 테이블이 개 필요하다. (는 약 43억이다)
그래서 대충 계산을 해보면, 7개의 계층을 만들어야 64bit 주소체계에 적용할 수 있다.
그런데 7개의 페이지 테이블을 방문하는 것은 상식적으로 말이 안된다.
이 때문에 64bit의 경우에는 계층 구조 방식을 부적절하다고 판단한다.
💬 outer 페이지 테이블부터 안쪽으로 들어가서 주소를 찾는다고 해서,
계층적 페이징을 "forward-mapped" page table 이라고도 한다.
b) 해시 페이지 테이블
💡 One approach for handling address spaces larger than 32 bits is to use a hashed page table, with the hash value being the virtual page number.
32bit 이상의 주소체계를 사용하는 OS를 위한 하나의 방법이 hashed page table이다.
해시의 각 value는 가상 페이지 번호를 의미한다.
그리고 해시 테이블은 chaining 방식을 사용한다.
해시 테이블의 각 원소들은 3개의 필드를 가진다.
1. 가상 페이지 번호
2. 페이지에 매핑된 프레임 번호
3. 다음 원소로 가는 포인터
각 필드가 어떻게 동작하는지 아래 그림을 보고 이해해보자.
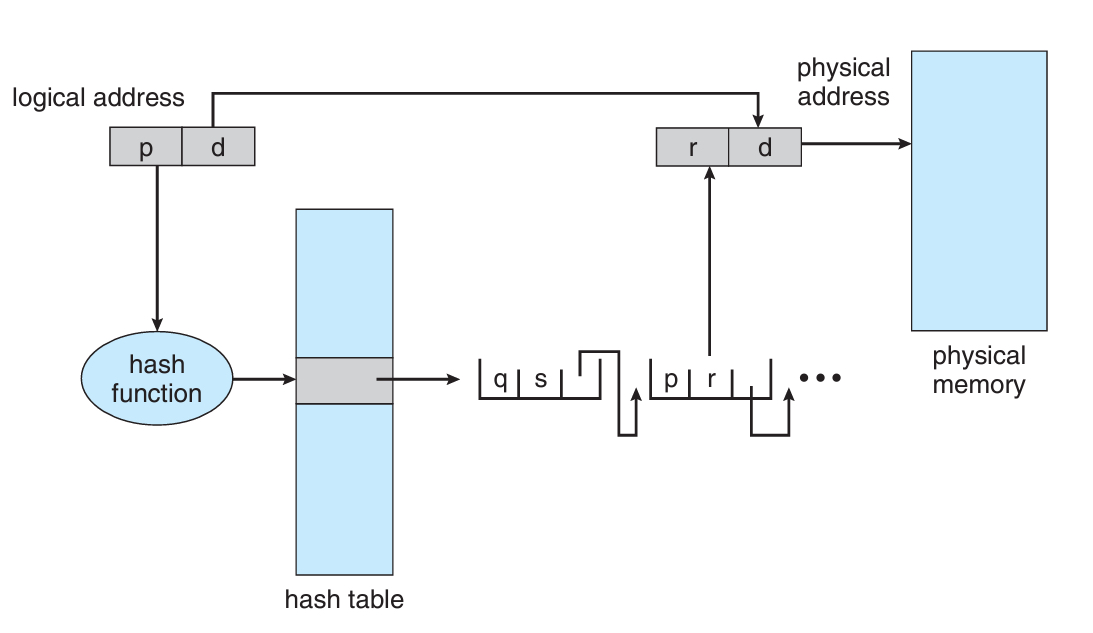
우선 논리 주소의 페이지 번호 파트를 해시함수에 넣어서 해당하는 연결리스트를 찾는다.
연결리스트를 순회하면서 본인의 가상 페이지 번호와 일치하는 원소를 찾는다.
찾았으면 2번째 필드인 프레임번호를 가져오면 끝난다.
물론 이 방식의 변형도 존재하는데, clustered page table이 있다.
클러스터 페이지 테이블은 해시와 기본 동작 원리는 비슷하지만,
해시 테이블의 각 엔트리가 하나가 아닌 여러 페이지의 정보를 들고 있는 것이다.
이 변형 방식은 주로 메모리 전반적으로 듬성듬성하게 저장되어있는 경우 유리하다.
c) 역 페이지 테이블
프레임의 개수는 메모리를 일정 간격으로 나눈 것이기 때문에 고정된 값이다.
하지만 페이지의 개수는 프로세스의 개수와 비례하여 많아진다.
그러다보면 프로세스의 개수가 너무 많아지면 페이지 테이블도 같이 커지게 될 것이다.
💡 To solve this problem, we can use an inverted page table. An inverted page table has one entry for each real page (or frame) of memory.
이를 해결하기 위한 방법으로 역 페이지 테이블이 있다.
페이지 테이블을 하나만 두고, 각 프레임마다 하나의 엔트리만 존재한다.
쉽게 말해 여태까지는 "특정 페이지가 어떤 프레임에 저장됐는지" 찾는 거라면,
역 페이지 테이블은 "특정 프레임에 어떤 페이지가 들어있는지" 조사하는 것이다.
IBM RT에서 어떻게 구현되어있는지 그림으로 보면서 이해해보자.
💬 IBM은 역 페이지 테이블을 도입한 첫 주요 기업이다.
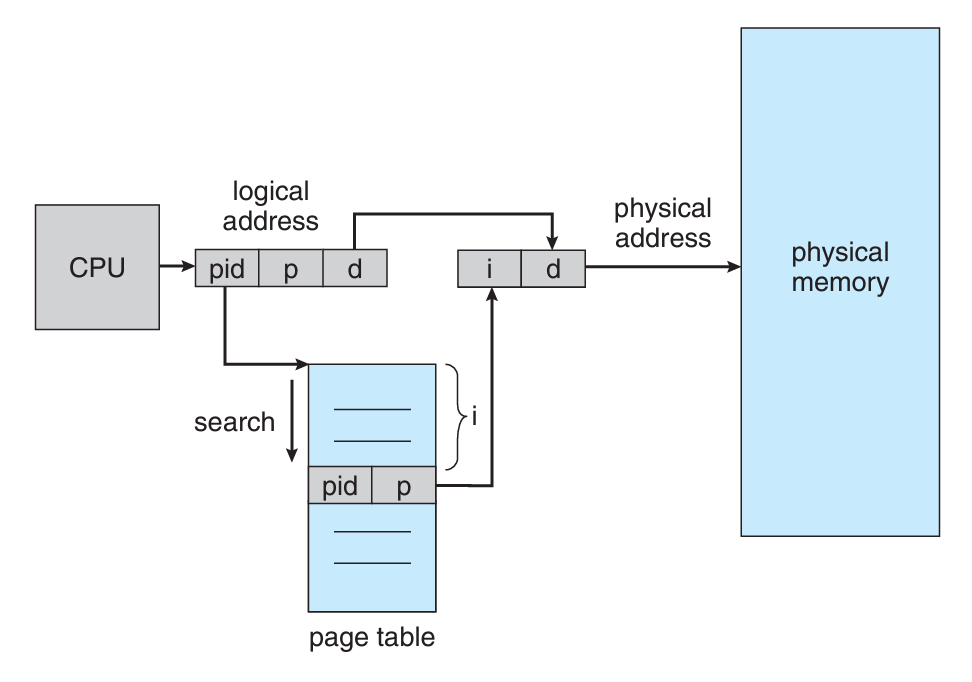
우선 논리주소는 총 3가지로 나뉘어야 한다.
offset인 d는 원래대로 냅두고, p를 쪼개서 pid를 위한 공간을 만들어줘야 한다.
(pid는 프로세스의 ID를 뜻하는 줄임말이다)
이 상태에서 우리는 pid와 p를 가지고 페이지 테이블을 스캔해야 한다.
페이지 테이블의 모든 entry도 마찬가지로 {pid, p}의 쌍을 들고 있기 때문에,
본인의 쌍과 일치하는 쌍을 찾을 때까지 테이블을 linear하게 탐색한다.
만약 찾았다면, 해당 index를 가져오고, 그 index가 프레임 번호이다.
역 페이지 테이블 방식은 공간을 절약하는 대신, 시간을 희생해야 한다.
찾고자 하는 쌍이 맨 아래에 있으면 결국 테이블 전체를 스캔하는 것과 같으니까.
그리고 한가지 더 한계점이 있다면, 공유 페이지를 사용할 수 없다.
하나의 프레임은 하나의 {pid, page number} 쌍으로 이루어지는데,
그렇다면 해당 프레임은 하나의 프로세스에 종속적이게 되기 때문이다.
4. 스와핑 (Swapping)
💡 Process instructions and the data they operate on must be in memory to be executed. However, a process, or a portion of a process, can be swapped temporarily out of memory to a backin store and then brought back into memory for continued execution.
프로세스의 명령어와 데이터는 실행되기 위해 반드시 메모리에 존재해야 한다.
하지만, 프로세스 전체 또는 일부가 메모리에서 나와 Backing Store에 들어갈 수도 있다.
다시 필요해지면 해당 프로세스를 찾아 다시 메모리에 올려서 마저 실행되어야 한다.
많이 헷갈리는 부분이지만, 페이징은 가상 메모리 전부터 있었던 개념이다!
a) 표준 스와핑
우선 page 이전의 표준으로 쓰였던 스와핑 기법에 대해서 알아보자.
표준 스와핑은 기본적으로 프로세스 전체를 빼고 다시 가져오는 방식을 사용한다.
아래 그림은 빼놨던 프로세스2가 다시 활성화되어 가져오는 과정이다.
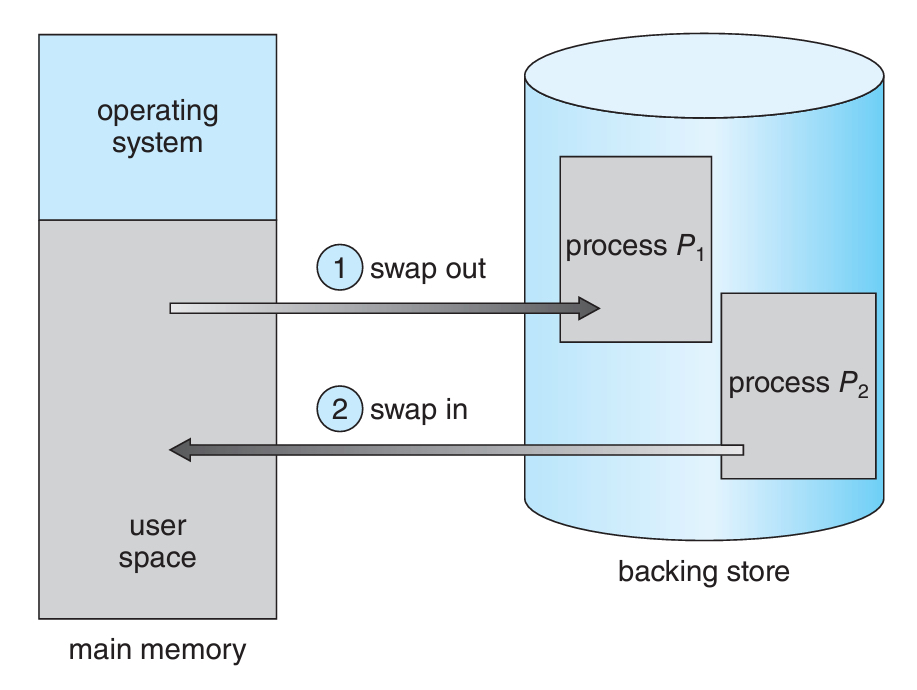
💬 Backing Store는 보통 Disk의 일부를 백업 공간으로 사용하는 부분이다.
보통 교재에서 원통형 그림이 나오면 디스크를 의미하는 경우가 많다.
프로세스가 backing store (이하 백업 저장소)에 가기 위해서는 모든 정보가 함께 가야한다.
우선 프로세스가 사용하는 모든 자료구조가 함께 이동해야한다.
멀티쓰레드라면 쓰레드별로 사용하는 내용 역시 다같이 이동해야한다.
또한, OS는 해당 프로세스의 metadata를 가지고 있어야 재개할수도 있을 것이다.
이렇게 현재 활성화된 프로세스만 메모리에 올리면 실제 메모리 용량보다 크게 사용할 수 있다.
예를 들어 4Gb짜리 램을 쓴다고 해도, 프로세스는 4Gb를 넘어서 올릴 수 있는 것이다.
특히, 자주 활성화되지 않는 프로세스가 많은 경우 효과적으로 사용될 수 있다.
b) 페이지 스와핑
위의 표준 스와핑은 사실 초창기의 UNIX에서만 사용하고, 현재는 잘 사용하지 않는다.
일단 프로세스 전체를 옮기는 오버헤드가 굉장히 컸기 때문이다.
그래서 현재의 대부분 OS는 페이지를 스와핑하는 방식을 채택한다.
페이지만 스와핑을 하게 된다면 물리주소를 초과하여 사용할 뿐만 아니라,
프로세스의 일부만 교체하기 때문에 오버헤드도 적고 더 많은 프로세스를 올릴 수도 있다.
💬 페이지를 백업 저장소로 빼는 것은 page out이라고 하고,
백업 저장소의 페이지를 다시 가져오는 것을 page in이라고 한다.
페이지 스와핑을 하게 되었을 때의 예시 그림이 아래와 같다.
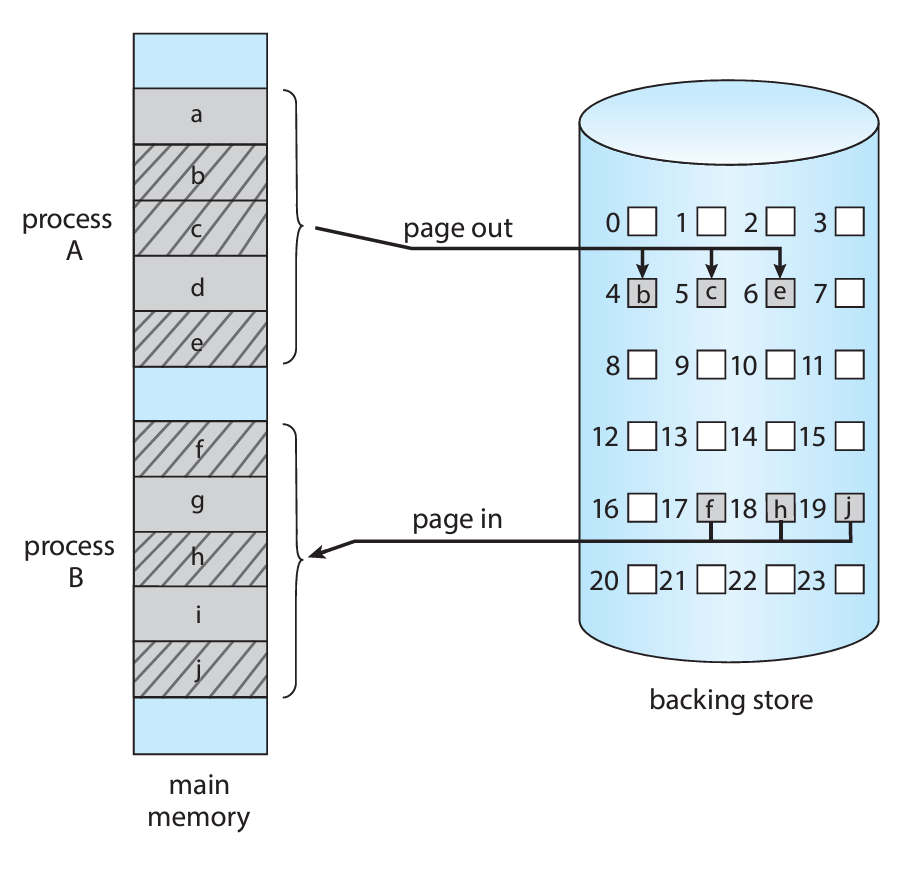
이 그림을 보면 표준 스와핑보다 효율적임을 직관적으로 알 수 있다.
💡 In fact, the term swapping now generally refers to standard swapping, and paging refers to the swapping with paging.
사실 요즘은 그냥 "스와핑"이라고만 하면 표준 스와핑을 뜻하고,
"페이징"이라고 하면 페이징 기법을 활용한 스와핑을 의미한다.
🎯 마치며
페이징 기법은 메모리 관리 차원에서 혁신적인 기술인 것 같다.
메모리에 대한 이해를 확실히 해서 가상메모리까지 정복해보자.
출처
Abraham Silberschatz, 『Operating System Concepts Ed.10』

좋은 글 감사합니다 : )